sparkPi源码解析
在ubuntu的eclipse系统上,基于maven建立了第一个spark程序sparkPi,顺利执行正确结果。
现在对sparkPi源码进行解析,借此熟悉spark java API,为后面基于java的spark编程做准备。
sparkPi源码如下:
package sparkTest;
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import java.util.ArrayList;
import java.util.List;
/**
* Computes an approximation to pi
* Usage: JavaSparkPi [slices]
*/
public final class JavaSparkPi {
public static void main(String[] args) throws Exception {
SparkConf sparkConf = new SparkConf().setAppName("JavaSparkPi").setMaster("local");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2;
int n = 100000 * slices;
List<Integer> l = new ArrayList<Integer>(n);
for (int i = 0; i < n; i++) {
l.add(i);
}
JavaRDD<Integer> dataSet = jsc.parallelize(l, slices);
int count = dataSet.map(new Function<Integer, Integer>() {
@Override
public Integer call(Integer integer) {
double x = Math.random() * 2 - 1;
double y = Math.random() * 2 - 1;
return (x * x + y * y < 1) ? 1 : 0;
}
}).reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) {
return integer + integer2;
}
});
System.out.println("Pi is roughly " + 4.0 * count / n);
jsc.stop();
}
}
源码解析:
1、SparkContext是
spark程序中非常核心的变量,所有spark程序的第一步都是创建+设置SparkContext。
sparkContext的作用是告诉spark如何访问集群cluster。
appName()设置程序名称,将会显示在cluster UI上。
master()是spark、Mesos、yarn集群的URL;或者是“local”字符串,表示在本地模式运行程序。
实际编程和运行程序时,并不会在编码中设置master(),因为这样灵活性不强。
常用的做法是,启动spark-submit -params,通过参数输入设置master()。
如果是本地测试程序,可以设置master为local。
2、parallelize()对输入数据进行并行化处理,处理后的数据就能进行RDD上的操作了,比如各种transformations、actions。
<span style="white-space:pre"> </span>parallelize()
3、map操作是一种transformation,将map的函数参数在数据集上的每个element,操作一次,得到一个新的RDD。
<span style="white-space:pre"> </span>map()
4、reduce操作是将RDD所有元素的聚合起来,通过reduce中的函数参数,从而得到一个最终结果。
<span style="white-space:pre"> </span>reduce
5、map、reduce内的函数传递是spark程序中常见的方式。它的实现形式有两种。
new fuction():传统方式。
lamda表达式:更简洁。
6、函数Function是接口函数。T1为输入参数,R为返回值。同理Function2也一样,不同的是起实现函数call不同。
Interface Function<T1,R>; Function2<T1,T2,R>
<span style="white-space:pre"> </span>new Function<Integer, Integer>()
<pre name="code" class="java"><span style="white-space:pre"> </span>new Function2<Integer, Integer, Integer>()
7、spark除了map、reduce函数外,还支持许多数据操作,比如filter()、collect()、count()等等。
补充说明:
1、数据如何并行化处理?
<span style="white-space:pre"> </span>List<Integer> data = Arrays.asList(1, 2, 3, 4, 5); <span style="white-space:pre"> </span>JavaRDD<Integer> distData = sc.parallelize(data);通过上述操作,将普通集合data通过函数parallelize(),并行化处理后,就变成了分布式数据集distributed dataset(distData),这种类型就能被spark集群做并行处理了。
<span style="white-space:pre"> </span>sc.parallelize(data, 10)我们也可以通过手动设置dataset的partitions个数,一个partition对应一个spark task。
如果没有设置partitions,则spark自动设置partitions个数。
2、spark支持的外部输入数据有哪些?
spark的输入数据可以来自hadoop的hdfs、local file system、Cassandra、HBase、Amazon S3、
textFile()函数用来将文件转化为RDD,转化结束后,新的RDD上就可以进行map、reduce、transformations、actions等操作。
textFile()函数中的参数path可以是directory、compress files、wildcards.
textFile()对文件的划分默认是64M一块(等同与HDFS系统),我们也可以根据参数修改划分标准。
val lines = textFile(“test.txt”)的解读。这句话并没有将test.txt加载到内存,也没有在文件上进行任何操作,只是使lines指向这个文件。
3、spark的RDD有两种创建方式:对以存在的数据集合进行并行化;对Hadoop HDFS、Hbase的数据进行转化。
4、spark支持两种操作:transformations、actions。
transformations:从已有数据集创建RDD数据集。比如:map就是一种transformation。
actions:对RDD上的dataset进行computation,return a value to the driver program.比如:reduce就是一种action。
transformations采取懒惰策略。即直到action需要result时,transformation才进行具体操作。之前都只是记住这些操作。
这种lazy策略,能够提高spark效率。避免transformation结果产生,只产生action结果。
对于如下操作:
<span style="white-space:pre"> </span>JavaRDD<String> lines = sc.textFile("data.txt");
<span style="white-space:pre"> </span>JavaRDD<Integer> lineLengths = lines.map(s -> s.length());
<span style="white-space:pre"> </span>int totalLength = lineLengths.reduce((a, b) -> a + b);
前面两步都没有直接执行,知道最后一部reduce,才触发真个spark程序执行。
reduce触发spark程序将task分解到集群中的每个机器上,每个机器执行其本地的map和reduce操作。向driver program返回其执行结果。
如果我们想在程序执行完毕后,查看lineLengths的值。可以使用如下方式,将其值persist().
lineLengths.persist(StorageLevel.MEMORY_ONLY());5、RDD可以通过persist()和cache()让其贮存在内存中,加快下次访问RDD的速度。
RDD也支持将起贮存在disk,多节点之间的deplicated。
如何选取存储介质,需要根据具体情况。
如果不想等cache()满了以后自动触发清除操作,可以手动.unpersist()清除数据。
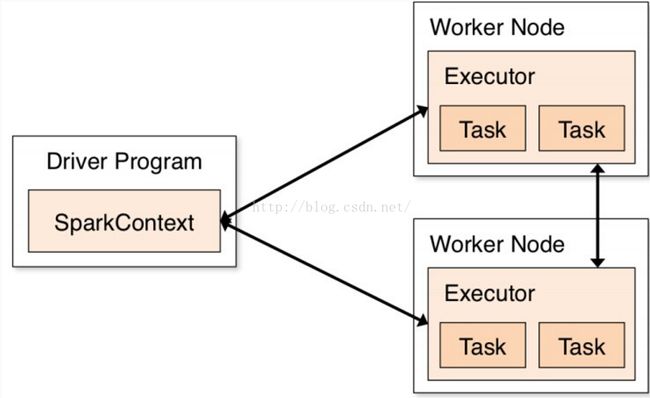
6、何为driver program,官方文档中反复提及。
可以理解为我们编写的spark源程序。
7、spark提供两种方式共享数据。
broadcast variables
accumulators
spark工作方式,简单参考图如下: