Tire树(字典树)的基本操作
Tire树的基本原理:
Tire树是一种树形结构,因其是词典的一种存储方式,故又叫字典树。词典中的每一个单
词在tire树中表现为一条从根结点出发的路径,路径边上的点连起来就是一颗tire树,如右图:
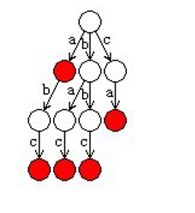 其中含有ab,abc,bac,bbc,ca五个单词。
其中含有ab,abc,bac,bbc,ca五个单词。
Tire树的基本性质可以归纳为:
(1)根结点不包含字符,其他的每一个节点只包含一个字符;
(2)从根结点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串;
(3)每个节点的所有子节点包含的字符都不相同。
典型的应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度的减少无谓的字符串比较,查询效率要高于哈希表。
Tire树核心是空间换时间,利用字符串的公共前缀来降低查询的时间开销,从而达到提高效率的目的。对于庞大的空间消耗,我们可以用链表来动态开辟空间,达到空间上利用率的最大化。
Tire树的基本操作:
Tire树的操作有:插入,查询和删除,删除操作不常用,下面我们主要看一下插入和查询操作:
#include <cstdio>
#include <cstdlib>
#include <iostream>
using namespace std;
#define son_num 30 //字符串中包含的字符个数
#define maxn 10 //单词的最大长度
struct tire
{
int num; //纪录到达该节点的字符串的个数,即相同前缀数
bool terminal; //如果terminal=true,表示当前点为该字符串最后一个字符
struct tire *next[son_num]; //纪录下一个节点
};
tire *root;
tire *init() //创建新节点
{
tire *p=(tire *)malloc(sizeof(tire));
for(int i=0;i<son_num;i++)
p->next[i]=NULL;
p->terminal=false;
p->num=0;
return p;
}
void insert(tire *root,char str[]) //插入操作
{
int i=0;
tire *p=root;
while(str[i]!='\0')
{
if(!p->next[ str[i]-'a' ]) //如果不存在,建立新节点
p->next[ str[i]-'a' ]=init();
p=p->next[ str[i]-'a' ];
p->num++;
i++;
}
p->terminal=true;
}
bool find(tire *p,char str[]) //查找操作
{
int i=0;
while(str[i]!='\0'&&p->next[ str[i]-'a' ])
{
p=p->next[ str[i]-'a' ];
i++;
}
if(str[i]=='\0'&&p->terminal) return true; //查找字符串本身
//if(str[i]=='\0') return true; 查找前缀
return false;
}
void del(tire *root) //清空操作
{
for(int i=0;i<son_num;i++)
if(root->next[i]!=NULL)
del(root->next[i]);
free(root);
}
int main()
{
root=init(); //创建根结点
char str[maxn];
int n,m; //n为建立字典树的单词数,m为要查找的单词数
cin>>n>>m;
for(int i=0;i<n;i++) //建立字典树
{
cin>>str;
insert(root,str);
}
for(int i=0;i<m;i++) //查找操作
{
cin>>str;
if(find(root,str)) puts("Yes");
else puts("No");
}
del(root); //释放字典树占用的空间
return 0;
}