apue学习第九天——标准I/O库(第五章)
这是第五章标准I/O库的内容,花了几个小时浏览了一遍。感觉这些东西在第一遍看的时候没必要太抠细节,用到的时候再查,所以下面只是简单记录,好啦,开始。
首先,给stream一个系统的定义:In computer science, a stream is a sequence of data elements made available over time. A stream can be thought of as a conveyor belt that allows items to be processed one at a time rather than in large batches. 流与batch data不同,Batch processing is the execution of a series of programs ("jobs") on a computer without manual intervention.
好啦,关于stream和batch data的区别,看上面,自己领悟。
当然,standard stream是指stdin,stdout,stderr,以前说过,fopen打开一个stream时返回FILE*,至此,下面不提。
接下来是关于buffering缓冲技术的。 fully buffered,line buffered和unbuffered三种。来看三种缓冲使用的地方:
当stream涉及终端时,常用行缓冲;标准错误要尽快显示出来,是不带缓冲的;其它的一般是全缓冲。
然后是一系列的open,read,write函数,下面只给定义,具体用法以后用到时再细查:
(1) open & close a stream
#include <stdio.h> FILE *fopen(const char *restrict pathname, const char *restrict type); FILE *freopen(const char *restrict pathname, const char *restrict type, FILE *restrict fp); FILE *fdopen(int fd, const char *type); //All three return: file pointer if OK, NULL on error
#include <stdio.h> int fclose(FILE *fp); //Returns: 0 if OK, EOF on error
(2)read & write a stream
每次读一个character:
#include <stdio.h> int getc(FILE *fp); int fgetc(FILE *fp); int getchar(void); /*All three return: next character if OK, EOF on end of file or error*/在大多数实现中,为每个stream在FILE对象中维护两个标志:出错标志和文件结束标志:
#include <stdio.h>
int ferror(FILE *fp);
int feof(FILE *fp);
/*Both return: nonzero (true) if condition is true, 0 (false) otherwise*/
void clearerr(FILE *fp);将刚读到的字符压回去:
#include <stdio.h> int ungetc(int c, FILE *fp); /*Returns: c if OK, EOF on error*/输出字符:
#include <stdio.h> int putc(int c, FILE *fp); int fputc(int c, FILE *fp); int putchar(int c); /*All three return: c if OK, EOF on error*/读一行:
#include <stdio.h> char *fgets(char *restrict buf, int n, FILE *restrict fp); char *gets(char *buf ); /*Both return: buf if OK, NULL on end of file or error*/写一行:
#include <stdio.h> int fputs(const char *restrict str, FILE *restrict fp); int puts(const char *str); /*Both return: non-negative value if OK, EOF on error*/还记得前面说的吧,着重在fgetc,fputc,其它字符相关的都可以实现为macro;尽量使用fgets和fputs,而避免使用gets(缓冲区溢出)和puts(多加了一个换行符)。
5.8 标准I/O的效率
我们通过图5-6来比较标准I/O和以前实例中系统调用的效率问题,看图;
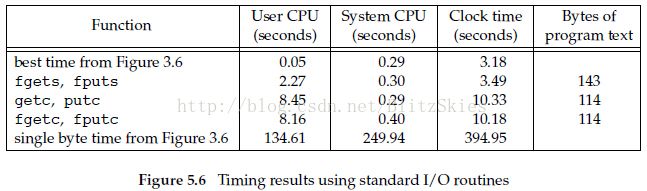
user CPU是进程在用户态执行的时间,system CPU是进程在内核态执行的时间,clock time是进程从开始到结束的总时间。这三者之间没有必然联系。一般来说clock time大于前两者之和,但也有不是这样的情况,比如说fork了子进程的话,clock time可能比前两者之和小,因为父子进程同时执行导致clock time缩短,但system CPU是两者线性相加的。
我们来看上面的图,第一行best time from figure 3.6,user CPU都远大于第一行,因为unbuffered read循环次数远小于下面几行;system CPU几乎相等,但第一行稍小,因为第一行执行的是系统调用;clock time主要受前面user CPU的影响,等待I/O读完导致时间变慢。
还有一点有意思的,速度上一次读一行是一次读一个的两倍,本应该速度相近但为什么会差别那么多呢?因为读一行的版本用memccpy实现,该函数直接用汇编编写,所以快一些。
接下来的几个知识点大致说一下:
binary I/O:一次读写一个完整的结构,比如说一个结构数组。如果用getc,putc,每次循环处理一个字节,麻烦;如果用fgets,fputs,由于fputs遇到null停止,而一个结构中可能有null,所以也不好。如果在异构网络中,二进制I/O必须遵循同一规范才可以相互读写。
positioning a stream:定位流主要用ftell, fseek, fgetpos等等。
formatted I/O(格式化I/O):也就是printf,scanf一类的函数,这些用到再查吧!
临时文件:有创建临时文件的函数。
memory streams(内存流):就是我们自己可以把数据写进内存里,更方便!
好啦,这就是标准I/O库的快速概述,它的效率不高是一个不足之处,比如:
每次调用fgets和fputs时,通常要复制两次数据,一次是内核与标准I/O缓冲区之间,一次是标准I/O缓冲区与用户程序的行缓冲之间。快速I/O库解决了这个问题,它使读一行返回指向该行的指针而不是复制该行到缓冲区。当然还有更高级的技术,这里就不列举了。