如何构建高效的storm计算模型
计算机制简介
Storm采用流式计算的模型,和shell类似让数据在一个个“管道”中进行处理。
- Spout负责从数据源拉取数据,相当于整个系统的生产者。
- Bolt负责消费数据并将tuple发送给下一个计算单元。Bolt可以接受多个spout和bolt的数据。
- 每个spout,bolt可以设置并行度excuter相当于多进程,每个excuter可以设置多个task
- shuffle grouping,它随机将tuple发给任何一个task;fields grouping,相同field值的tuple发送给同一个task。
数据完整性
当spout发送一个数据的时候为每一个tuple产生一个唯一的message id。当数据被完整处理的时候bolt会产生一个应答ack(成功)或fail(失败),如果数据超过(默认30s)则视为超时然后丢弃掉(可以通过操纵fail方法重新发送数据,不过这带来很高的计算成本)。同时受spout发射tuple最大数的限制bole的处理速度会影响spout的发射速度。因此如果保证数据被快速消费掉成为影响流式计算速度的关键所在。
stom计算模型
一个简单的storm计算模型基本包括3部分:从数据源拉取数据,关联离线的维表,将结果写入数据库。
我们假设需要统计一个购物网站商品分类目的点击人数次数,而且这个网站数据量非常大。大致步骤如下:
A. FF负责产生商品点击数据
B. 关联商品类目
C.将结果写入hbase
商品id:auc_id 用户id:user_id
A.拉取数据
你的任务跑的很快,资源占用也少但是数据为啥数据也这么少呢?不好,数据全堆积在FF数据源了。ok,加大spout的task数,并行度为1。但是为啥数据还是这么少,来看看我们的代码。
public void nextTuple() {
while (true) {
LogData log = null;
try {
log = queue.take();
} catch (InterruptedException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
return;
}
if(log.getType() == null)
continue;
collector.emit(streamId, new Values(log.getData(), uid));
}
}
问题的关键在于take为阻塞方法,而storm的多线程由同一个excuter来控制,相当于一个循环在多个task之间切换。当一个task阻塞的时候其他task也无法执行,但大部分线程是可以拿到数据的,整体相当于只有单线程在执行。解决办法是改用无阻塞的poll方法从队列中拿到数据。
如果增加并行度呢?改成多 excuter单task之后即使单个task的take 方法阻塞也不会对其他task产生影响,而且效率也比多task高。但随之引来一个新问题:由于task的阻塞导致任务超时失败率增加部分数据被丢弃,因此乖乖改成无阻塞的poll方法吧。
如果还想快一点呢?那就直接去掉应答,因为应答本身也消耗资源,但是统计不到失败率的,慎用。
conf.setNumAckers(0);
总结起来就是拉数据提高并行度,task数设为1,取数据采用无阻塞方法,数据量大去掉应答。
B. 关联商品类目
离线商品表?听起来很大的样子。这时候我们需要一个缓存,LRUCache是个不错的选择,他是一个双向链表的数据结构,查询次数越高会靠前,查询次数低会排在后面,甚至舍弃。商品表太大导入hbase很慢?分表吧。我们需要做的就是将商品表哈希到n个小表然后批量导入。查询的的时候如果没有命中缓存则将auc_id哈希到对应的商品表进行查询。
这时候你会发现查询商品表,累加,然后将结果存入hbase是一个很长的过程,而这很可能造成你的处理超时然后数据被丢掉。这里我们引入BlockingQueue,如果BlockingQueue是空的,取数操作会阻断进入等待状态,直到有值才被唤醒,存数时如果队列是满的,则阻断进入等待状态,直到BlockingQueue里有空间时才会被唤醒。我们将user_id哈希到n个BlockingQueue(为最大利用cpu n为cpu数),将用户数据插入到对应的BlockingQueue后直接应答,这样storm就可以快速进行下一步处理。同时该BlockingQueue对应的线程负责消费数据,所有线程共享LRUCach商品表缓存。
C.将结果写入hbase
这时我们需要一个队列存储结果,ConcurrentHashMap是一个线程安全的无阻塞数组。前面说到数据是分散到不同的线程进行计算的。每个线程将结果插入到同一个ConcurrentHashMap(插入读写无阻塞),然后通过ScheduledThreadPoolExecutor定时将输入批量导入到hbase。
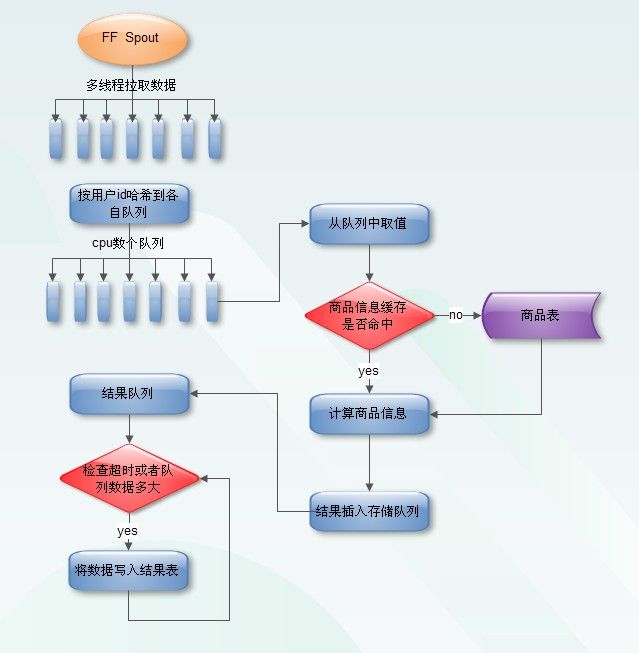
D.计算点击人数
这里讨论另外一个问题大数据去重,比较简单的方法是直接建立user_id缓存,但是这样很耗资源。通过bloomfilter可以损失很小的准确性的情况下完成去重。具体参考http://blog.csdn.net/jiaomeng/article/details/1495500