Hduoj1251【字典树】
/*统计难题
Time Limit : 4000/2000ms (Java/Other) Memory Limit : 131070/65535K (Java/Other)
Total Submission(s) : 3 Accepted Submission(s) : 1
Font: Times New Roman | Verdana | Georgia
Font Size: ← →
Problem Description
Ignatius最近遇到一个难题,老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计出以某个字符串为前缀的单词数量
(单词本身也是自己的前缀).
Input
输入数据的第一部分是一张单词表,每行一个单词,单词的长度不超过10,它们代表的是老师交给Ignatius统计的单词,一个空行代表单词表的结束.
第二部分是一连串的提问,每行一个提问,每个提问都是一个字符串.
注意:本题只有一组测试数据,处理到文件结束.
Output
对于每个提问,给出以该字符串为前缀的单词的数量.
Sample Input
banana
band
bee
absolute
acm
ba
b
band
abc
Sample Output
2
3
1
0
Author
Ignatius.L
*/
#include<stdio.h>
#include<string.h>
#include<malloc.h>
typedef struct Trie
{
Trie * next[26];
int num;
}Trie;
Trie root;
void creatTrie(char *str)
{
Trie *p = &root, *q;
int i , id, l, j;
l = strlen(str);
for(i = 0; i < l; ++i)
{
id = str[i] - 'a';//第一个字母的编号
if(p->next[id] == NULL)//第一次出现
{
q = (Trie *)malloc(sizeof(root));
q->num = 1; //出现次数初始化为1
for(j = 0; j < 26; ++j)//并将后面未出现的标记
q->next[j] = NULL;
p->next[id] = q;//将该字母连接上树
p = p->next[id];//继续判断下个位置
}
else//若已经出现过
{
p->next[id]->num++;//则字符串出现次数加1
p = p->next[id];//并继续下移
}
}
}
int find(char *str)
{
int i, j, id;
Trie *p = &root;
j = strlen(str);
for(i = 0; i < j; ++i)
{
id = str[i] - 'a';
if(p->next[id] == NULL)//若中途没找到字母,则直接返回0
return 0;
else
p = p->next[id];
}
return p->num;//若成功找到所有字母则输出该字符串的前缀个数
}
int main()
{
int i, j, k;
char s[11];
for(i = 0; i < 26; ++i)
root.next[i] = NULL;
while(1)
{
gets(s);
if(s[0] == '\0')
break;
creatTrie(s);
}
while(scanf("%s", s) != EOF)
{
printf("%d\n", find(s));
}
return 0;
}
题意:给出n个单词作为词典,然后在输入单词,查找词典中有多少个单词有该单词前缀。
思路:该题用常规方法要超时,所以只能用字典树,而且还是字典树的模板题。
体会:由于字典树所需空间较大,一般都用指针去完成,动态分配内存。
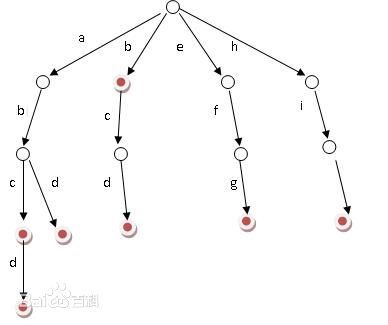
附上字典树的原理图