利用word2vec对关键词进行聚类<转>
继上次提取关键词之后,项目组长又要求我对关键词进行聚类。说实话,我不太明白对关键词聚类跟新闻推荐有什么联系,不过他说什么我照做就是了。
按照一般的思路,可以用新闻ID向量来表示某个关键词,这就像广告推荐系统里面用用户访问类别向量来表示用户一样,然后就可以用kmeans的方法进行聚类了。不过对于新闻来说存在一个问题,那就量太大,如果给你十万篇新闻,那每一个关键词将需要十万维的向量表示,随着新闻数迅速增加,那维度就更大了,这计算起来难度太大。于是,这个方法思路简单但是不可行。
好在我们有word2vec这个工具,这是google的一个开源工具,能够仅仅根据输入的词的集合计算出词与词直接的距离,既然距离知道了自然也就能聚类了,而且这个工具本身就自带了聚类功能,很是强大。下面正式介绍如何使用该工具进行词的分析,关键词分析和聚类自然也就包含其中了。word2vec官网地址看这里:https://code.google.com/p/word2vec/
1、寻找语料
要分析,第一步肯定是收集数据,这里不可能一下子就得到所有词的集合,最常见的方法是自己写个爬虫去收集网页上的数据。不过,如果不需要实时性,我们可以使用别人提供好的网页数据,例如搜狗2012年6月到7月的新闻数据:http://www.sogou.com/labs/dl/ca.html 直接下载完整版,注册一个帐号,然后用ftp下载,ubuntu下推荐用filezilla
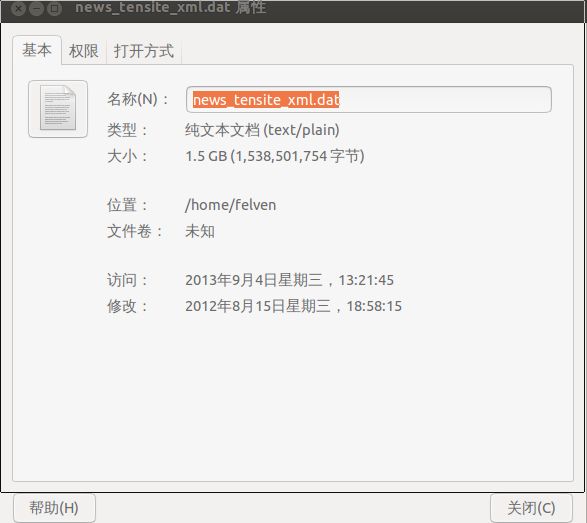
下载得到的数据有1.5G
2、分词
我们得到的1.5的数据是包含一些html标签的,我们只需要新闻内容,也就是content其中的值。首先可以通过简单的命令把非content的标签干掉
- cat news_tensite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<content>" > corpus.txt
得到了corpus.txt文件只含有content标签之间的内容,再对内容进行分词即可,这里推荐使用之前提到过的ANSJ,没听过的看这里: http://blog.csdn.net/zhaoxinfan/article/details/10403917
下面是调用ANSJ进行分词的程序:
- import java.util.HashSet;
- import java.util.List;
- import java.util.Set;
- import java.io.BufferedReader;
- import java.io.BufferedWriter;
- import java.io.File;
- import java.io.FileInputStream;
- import java.io.FileReader;
- import java.io.FileWriter;
- import java.io.IOException;
- import java.io.InputStreamReader;
- import java.io.PrintWriter;
- import java.io.StringReader;
- import java.util.Iterator;
- import love.cq.util.IOUtil;
- import org.ansj.app.newWord.LearnTool;
- import org.ansj.domain.Term;
- import org.ansj.recognition.NatureRecognition;
- import org.ansj.splitWord.Analysis;
- import org.ansj.splitWord.analysis.NlpAnalysis;
- import org.ansj.splitWord.analysis.ToAnalysis;
- import org.ansj.util.*;
- import org.ansj.recognition.*;
- public class test {
- public static final String TAG_START_CONTENT = "<content>";
- public static final String TAG_END_CONTENT = "</content>";
- public static void main(String[] args) {
- String temp = null ;
- BufferedReader reader = null;
- PrintWriter pw = null;
- try {
- reader = IOUtil.getReader("corpus.txt", "UTF-8") ;
- ToAnalysis.parse("test 123 孙") ;
- pw = new PrintWriter("resultbig.txt");
- long start = System.currentTimeMillis() ;
- int allCount =0 ;
- int termcnt = 0;
- Set<String> set = new HashSet<String>();
- while((temp=reader.readLine())!=null){
- temp = temp.trim();
- if (temp.startsWith(TAG_START_CONTENT)) {
- int end = temp.indexOf(TAG_END_CONTENT);
- String content = temp.substring(TAG_START_CONTENT.length(), end);
- //System.out.println(content);
- if (content.length() > 0) {
- allCount += content.length() ;
- List<Term> result = ToAnalysis.parse(content);
- for (Term term: result) {
- String item = term.getName().trim();
- if (item.length() > 0) {
- termcnt++;
- pw.print(item.trim() + " ");
- set.add(item);
- }
- }
- pw.println();
- }
- }
- }
- long end = System.currentTimeMillis() ;
- System.out.println("共" + termcnt + "个term," + set.size() + "个不同的词,共 "
- +allCount+" 个字符,每秒处理了:"+(allCount*1000.0/(end-start)));
- } catch (IOException e) {
- e.printStackTrace();
- } finally {
- if (null != reader) {
- try {
- reader.close();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- if (null != pw) {
- pw.close();
- }
- }
- }
- }
经过对新闻内容分词之后,得到的输出文件resultbig.txt有2.2G,其中的格式如下:
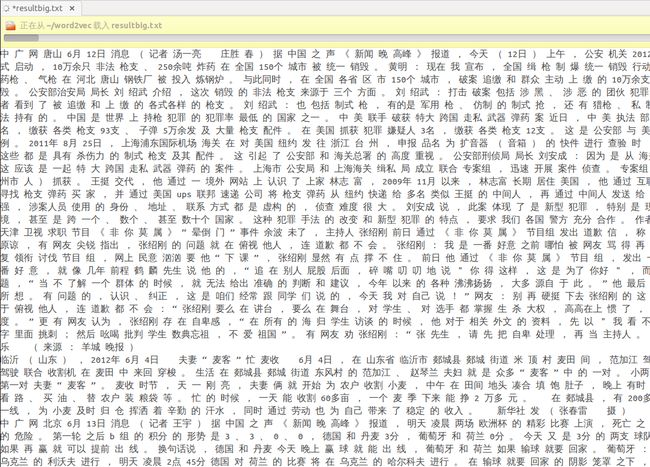
这个文件就是word2vec工具的输入文件
3、本地运行word2vec进行分析
首先要做的肯定是从官网上下载word2vec的源码:http://word2vec.googlecode.com/svn/trunk/ ,然后把其中makefile文件的.txt后缀去掉,在终端下执行make操作,这时能发现word2vec文件夹下多了好几个东西。接下来就是输入resultbig.txt进行分析了:
- ./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -binary 1
这里我们指定输出为vectors.bin文件,显然输出到文件便于以后重复利用,省得每次都要计算一遍,要知道处理这2.2G的词集合需要接近半个小时的时间:
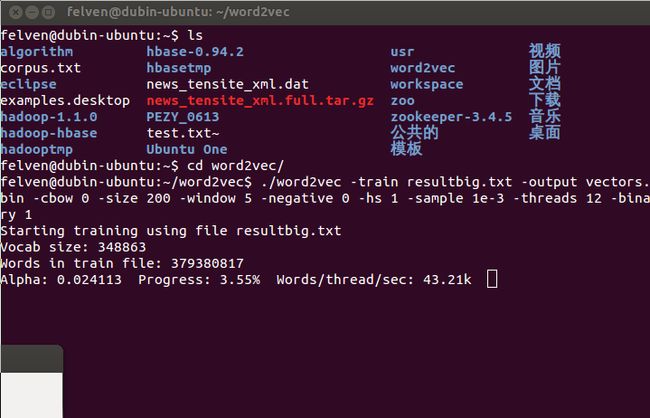
下面再输入计算距离的命令即可计算与每个词最接近的词了:
- ./distance vectors.bin
这里列出一些有意思的输出:
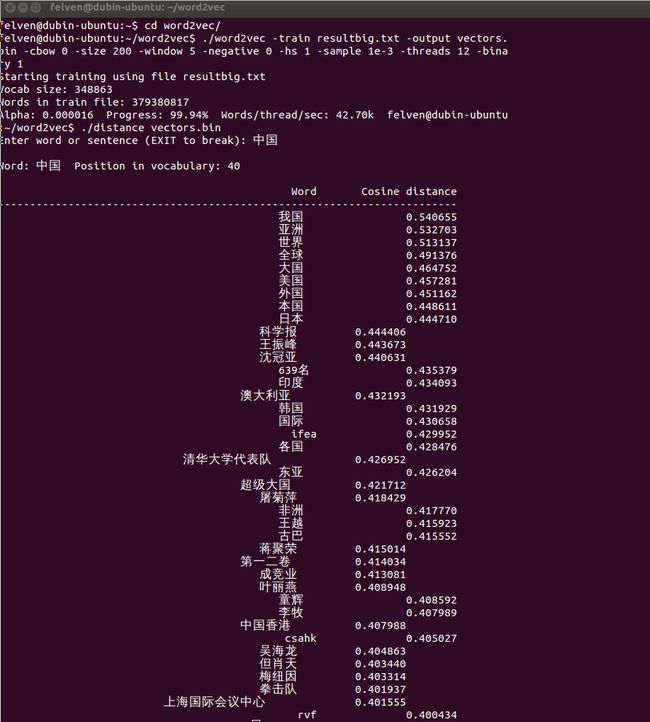
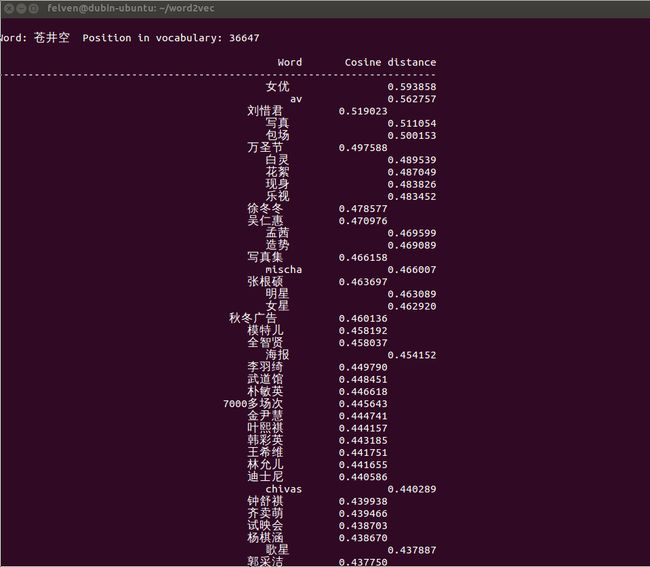
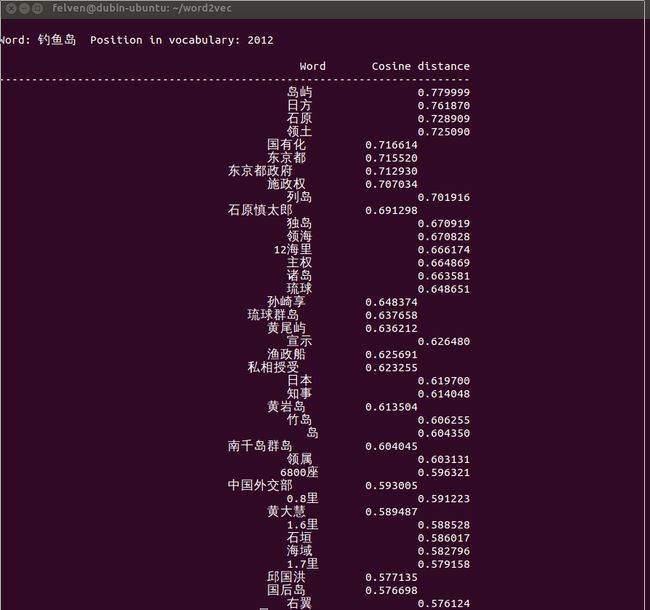
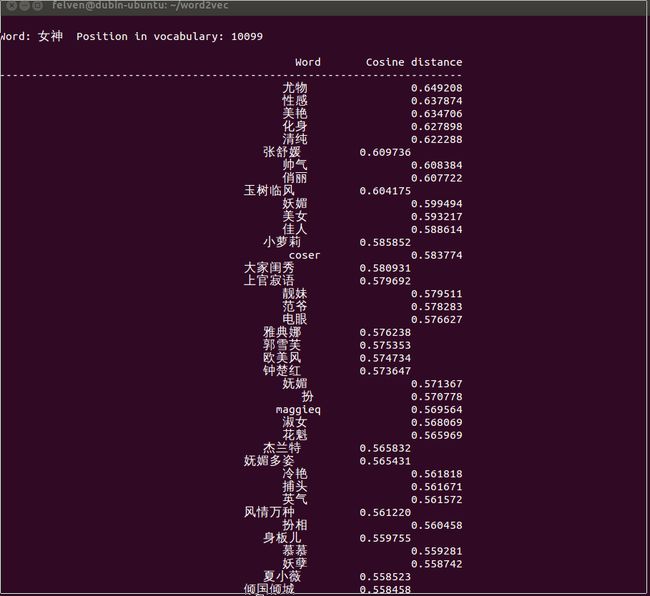
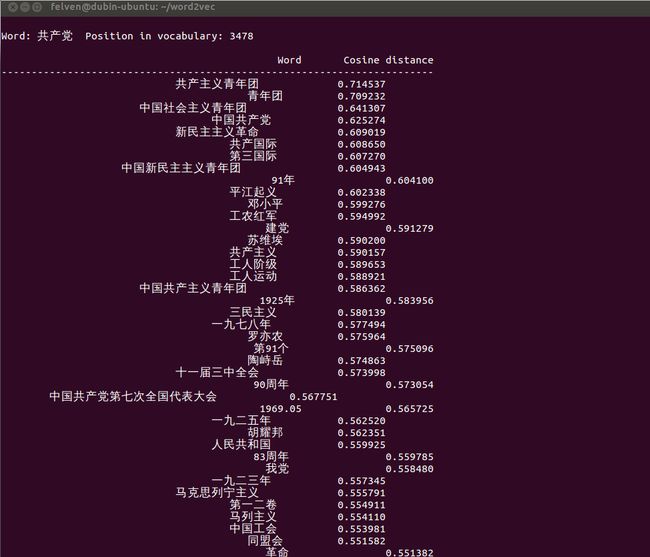

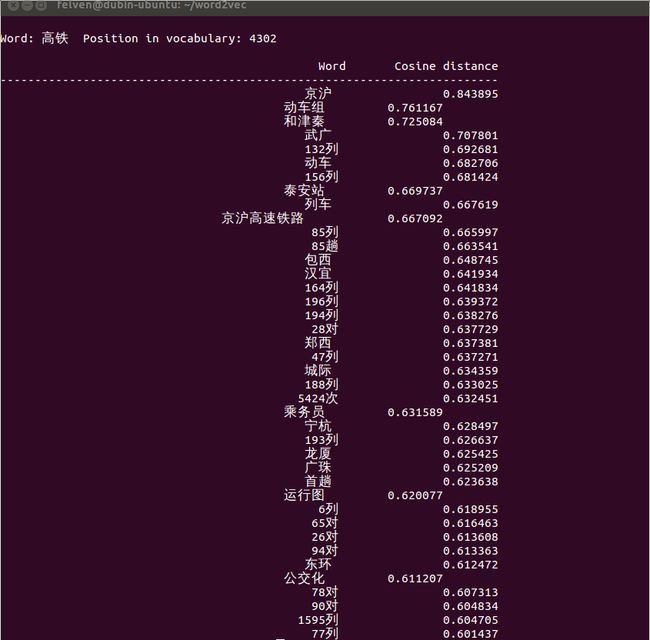
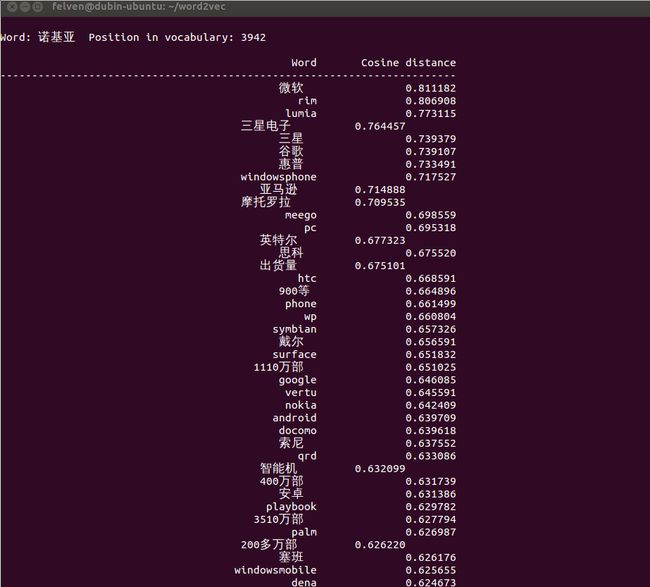
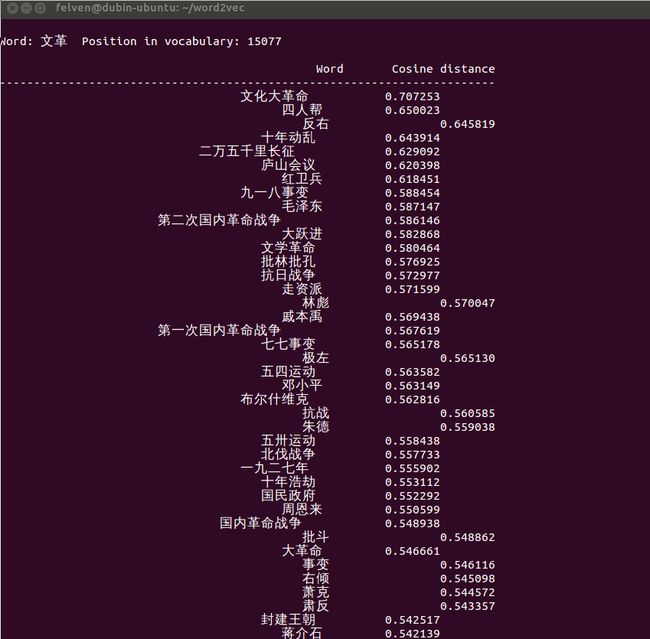
怎么样,是不是觉得还挺靠谱的?补充一点,由于word2vec计算的是余弦值,距离范围为0-1之间,值越大代表这两个词关联度越高,所以越排在上面的词与输入的词越紧密。
至于聚类,只需要另一个命令即可:
- ./word2vec -train resultbig.txt -output classes.txt -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -classes 500
按类别排序:
- sort classes.txt -k 2 -n > classes.sorted.txt
后记:如果想要了解word2vec的实现原理,应该读一读官网后面的三篇参考文献。显然,最主要的应该是这篇: Distributed Representations of Words and Phrases and their Compositionality
这篇文章的基础是 Natural Language Processing (almost) from Scratch 其中第四部分提到了把deep learning用在NLP上。
最后感谢晓阳童鞋向我提到这个工具,不愧是立志要成为NLP专家的人。
附:一个在线测试的网站,貌似是一位清华教授做的:http://cikuapi.com/index.php