phoenix实战(hadoop2、hbase0.96)
版本:
phoenix:2.2.2,可以下载源码(https://github.com/forcedotcom/phoenix/tree/port-0.96)自己编译,或者从这里下载(http://download.csdn.net/detail/fansy1990/7146479、http://download.csdn.net/detail/fansy1990/7146501)。
hadoopp:hadoop2.2.0
hbase:hbase-0.96.2-hadoop2。
首先把hbase和hadoop2 配置好,hadoop2就不多少了,配置的是伪分布式的yarn方式。hbase配置的是伪分布式,并且使用自带的zookeeper(默认端口2181)。
hbase的配置文件如下:
hbase-site.xml:
- <configuration>
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://node31:9000/hbase</value>
- </property>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>node31</value>
- </property>
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/var/zookeeper</value>
- </property>
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
1. 把$PHOENIX_HOME/target/phoenix-2.2.0-SNAPSHOT.jar 文件拷贝到$HBASE_HOME/lib/下面,重启hbase。
2. 把 $HBASE_HOME/conf/hbase-site.xml文件拷贝到$PHOENIX_HOME/bin/下面,替换原来的文件。
三种操作方式:
1. sqlline方式:
进入$PHOENIX_HOME/bin 输入:./sqlline.sh node31:2181 ,其中node31:2181是zookeeper的地址;然后就是命令行了,如下:

2. psql方式:
2.1 新建表:
命令:./psql.sh node31:2181 ../examples/stock_symbol.sql , 其中 ../examples/stock_symbol.sql是建表的sql语句,如下:
- CREATE TABLE IF NOT EXISTS WEB_STAT (
- HOST CHAR(2) NOT NULL,
- DOMAIN VARCHAR NOT NULL,
- FEATURE VARCHAR NOT NULL,
- DATE DATE NOT NULL,
- USAGE.CORE BIGINT,
- USAGE.DB BIGINT,
- STATS.ACTIVE_VISITOR INTEGER
- CONSTRAINT PK PRIMARY KEY (HOST, DOMAIN, FEATURE, DATE)
- );
命令:./psql.sh -t WEB_STAT node31:2181 ../examples/web_stat.csv , 其中 -t 后面是表名, ../examples/web_stat.csv 是csv数据(注意数据的分隔符需要是逗号)。
首先使用sqlline查看:
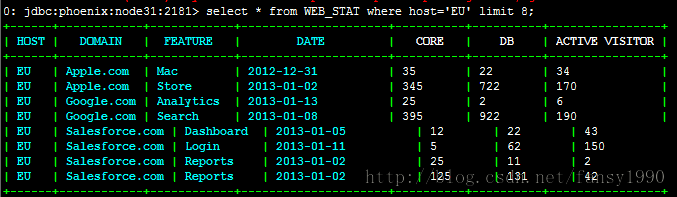
从上面的数据可以看到倒数第一、二条数据的primary key是一样的,primary key是作为hbase的row key的,应该是不一样的。所以这样肯定是有问题的,看原始数据:

可以看到这两个记录是不相同的,所以是可以插入的,不过只是在sqlline中并没有全部显示DATE的全部而已。
在Hbase中查看表数据:

这里可以看到在建表语句中使用USAGE.CORE就说明USAGE是一个family,而CORE则是它的一个列。
2.3 查询:命令:./psql.sh -t WEB_STAT node31:2181 ../examples/web_stat_queries.sql (或者./psql.sh -t WEB_STAT node31:2181 ../examples/web_stat_queries.sql > result.txt ,这样是把查询的数据保存到文件而已)
查询的结果如下:
- DOMAIN AVERAGE_CPU_USAGE AVERAGE_DB_USAGE
- ---------- ----------------- ----------------
- Salesforce.com 260.7272 257.6363
- Google.com 212.875 213.75
- Apple.com 114.1111 119.5555
- Time: 0.087 sec(s)
- DAY TOTAL_CPU_USAGE MIN_CPU_USAGE MAX_CPU_USAGE
- ------------------- --------------- ------------- -------------
- 2013-01-01 00:00:00 35 35 35
- 2013-01-02 00:00:00 150 25 125
- 2013-01-03 00:00:00 88 88 88
- 2013-01-04 00:00:00 26 3 23
- 2013-01-05 00:00:00 550 75 475
- 2013-01-06 00:00:00 12 12 12
- 2013-01-08 00:00:00 345 345 345
- 2013-01-09 00:00:00 390 35 355
- 2013-01-10 00:00:00 345 345 345
- 2013-01-11 00:00:00 335 335 335
- 2013-01-12 00:00:00 5 5 5
- 2013-01-13 00:00:00 355 355 355
- 2013-01-14 00:00:00 5 5 5
- 2013-01-15 00:00:00 720 65 655
- 2013-01-16 00:00:00 785 785 785
- 2013-01-17 00:00:00 1590 355 1235
- Time: 0.246 sec(s)
- HOST TOTAL_ACTIVE_VISITORS
- ---- ---------------------
- EU 150
- NA 1
- Time: 0.37 sec(s)
3. csv-bulk-loader.sh方式:
首先把phoenix jar包拷贝的hadoop lib目录:cp /opt/phoenix-port-0.96/target/phoenix-2.2.0-SNAPSHOT.jar /opt/hadoop2/share/hadoop/common/lib/
这种方式的使用参数:
- Usage: csv-bulk-loader <option value>
- Note: phoenix-[version].jar needs to be on Hadoop classpath on each node
- <option> <value>
- -i CSV data file path in hdfs (mandatory)
- -s Phoenix schema name (mandatory if not default)
- -t Phoenix table name (mandatory)
- -sql Phoenix create table sql file path (mandatory)
- -zk Zookeeper IP:<port> (mandatory)
- -mr MapReduce Job Tracker IP:<port> (mandatory)
- -hd HDFS NameNode IP:<port> (mandatory)
- -o Output directory path in hdfs (optional)
- -idx Phoenix index table name (optional, not yet supported)
- -error Ignore error while reading rows from CSV? (1-YES | 0-NO, default-1) (optional)
- -help Print all options (optional)
另外经过试验,./psql.sh -t WEB_STAT node31:2181 hdfs://node31:9000/input/web_stat.csv 这种方式也是不行的,所以数据暂时不能从hdfs到hbase了。
不过,看到 java -cp "$phoenix_client_jar" com.salesforce.phoenix.map.reduce.CSVBulkLoader "$@" 这个,那么或许可以修改 CSVBulkLoader的源码,然后让其支持这个操作,同时-sql,应该也是可选项来的,而不应该是必选项。这两天试着改改好了。(虽说,phoenix高版本肯定是已经做了这个,不过如果个人修改的话,应该也可以增加点编程能力)
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990