集群技术(三)MySQL集群深度解析
什么是MySQL集群
MySQL集群是一个无共享的(shared-nothing)、分布式节点架构的存储方案,其目的是提供容错性和高性能。
数据更新使用读已提交隔离级别(read-committedisolation)来保证所有节点数据的一致性,使用两阶段提交机制(two-phasedcommit)保证所有节点都有相同的数据(如果任何一个写操作失败,则更新失败)。
无共享的对等节点使得某台服务器上的更新操作在其他服务器上立即可见。传播更新使用一种复杂的通信机制,这一机制专用来提供跨网络的高吞吐量。
通过多个MySQL服务器分配负载,从而最大程序地达到高性能,通过在不同位置存储数据保证高可用性和冗余。
架构图
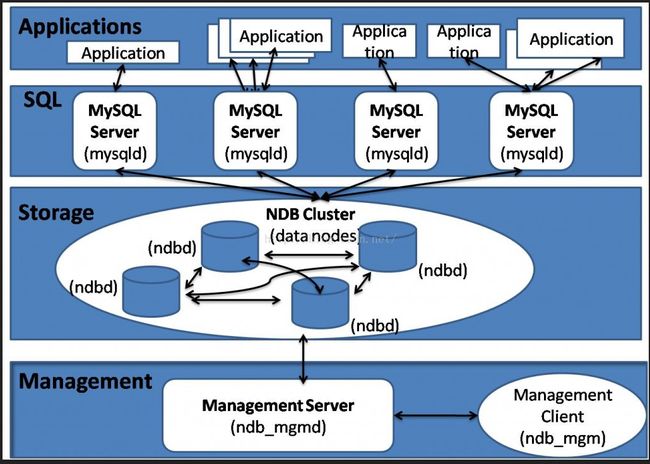
如何存储数据
Mysqlcluster数据节点组内主从同步采用的是同步复制,来保证组内节点数据的一致性。一般通过两阶段提交 协议来实现,一般工作过程如下:
a)Master执行提交语句时,事务被发送到slave,slave开始准备事务的提交。
d)如果Master收到所有 Slave的OK消息,它就会向所有Slave发送提交消息,告诉Slave提交该事务; 如果Master收到来自任何一个Slave的ABORT消息,它就向所有 Slave发送ABORT消息,告诉Slave去中止事务。
e)每个Slave等待来自Master的OK或ABORT消息。
如果Slave收到提交请求,它们就会提交事务,并向Master发送事务已提交 的确认;
如果Slave收到取消请求,它们就会撤销所有改变并释放所占有的资源,从而中止事务,然后向Masterv送事务已中止的确认。
f)当Master收到来自所有Slave的确认后,就会报告该事务被提交(或中止),然后继续进行下一个事务处理。
由于同步复制一共需要4次消息传递,故mysql cluster的数据更新速度比单机mysql要慢。所以mysql cluster要求运行在千兆以上的局域网内,节点可以采用双网卡,节点组之间采用直连方式。
Mysql cluster将所有的索引列都保存在主存中,其他非索引列可以存储在内存中或者通过建立表空间存储到磁盘上。如果数据发生改变(insert,update,delete等),mysql 集群将发生改变的记录写入重做日志,然后通过检查点定期将数据定入磁盘。由于重做日志是异步提交的,所以故障期间可能有少量事务丢失。为了减少事务丢失,mysql集群实现延迟写入(默认延迟两秒,可配置),这样就可以在故障发生时完成检查点写入,而不会丢失最后一个检查点。一般单个数据节点故障不会导致任何数据丢失,因为集群内部采用同步数据复制。
MySQL集群的横向扩展
1.添加数据节点组来扩展写操作,提高 cluster的存储能力。支持在线扩容,先将新的节点加入到clsuter里,启动后用
ALTER ONLINE TABLE table_name REORGANIZE PARTITION命令进行数据迁移,把数据平均分配到数据节点上。
2.添加Slave仅仅扩展读,而不能做到写操作的横向扩展。
整个系统的平均负载可以描述为:
AverageLoad=∑readload+ ∑writeload / ∑capacity 假设每个服务器每秒有10000的事务量,而Master每秒的写负载为4000个事务,每秒的读负载为6000,结果就是: AverageLoad=6000+4000/10000=100%
现在,添加3个slave,每秒的事务量增加到40000。因为写操作也会被复制,每个写操作执行4次,这样每个slave的写负载就是每秒4000个事务。那么现在的平均负载为:
AverageLoad=6000+4*4000/ 4*10000=55%
MySQL集群的优缺点
优点:
99.999%的高可用性;快速的自动失效切换;灵活的分布式体系结构,没有单点故障;高吞吐量和低延迟;可扩展性强,支持在线扩容
缺点: