大数据之使用hadoop对海量数据进行统计并排序
不得不说,Hadoop确实是处理海量离线数据的利器,当然,凡是一个东西有优点必定也有缺点,hadoop的缺点也很多,比如对流式计 算,实时计算,DAG具有依赖关系的计算,支持都不友好,所以,由此诞生了很多新的分布式计算框 架,Storm,Spark,Tez,impala,drill,等等,他们都是针对特定问题提出一种解决方案,新框架的的兴起,并不意味者他们就可以替 代hadoop,一手独大,HDFS和MapReduce依旧是很优秀的,特别是对离线海量数据的处理。
hadoop在如下的几种应用场景里,用的还是非常广泛的,1,搜索引擎建索引,2,topK热关键词统计,3,海量日志的数据分析等等。
散仙,今天的这个例子的场景要对几亿的单词或短语做统计和并按词频排序,当然这些需求都是类似WordCount问题,如果你把Hadoop 自带的WordCount的例子,给搞懂了,基本上做一些IP,热词的统计与分析就很很容易了,WordCount问题,确实是一个非常具有代表性的例 子。
下面进入正题,先来分析下散仙这个例子的需求,总共需要二步来完成,第一步就是对短语的统计,第二步就是对结果集的排序。所 以如果使用MapReduce来完成的话,就得需要2个作业来完成这件事情,第一个作业来统计词频,第二个来负责进行排序,当然这两者之间是有依赖关系 的,第二个作业的执行,需要依赖第一个作业的结果,这就是典型的M,R,R的问题并且作业之间具有依赖关系,这种问题使用MapReduce来完成,效率 可能有点低,如果使用支持DAG作业的Tez来做这件事情,那么就很简单了。不过本篇散仙,要演示的例子还是基于MapReduce来完成的,有兴趣的朋 友,可以研究一下使用Tez。
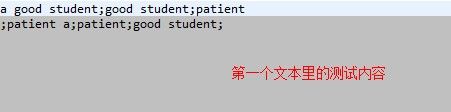
对于第一个作业,我们只需要改写wordcount的例子,即可,因为散仙的需求里面涉及短语的统计,所以定义的格式为,短语和短语之间使用分号隔开,(默认的格式是按单词统计的,以空格为分割符)在map时只需要,按分号打散成数组,进行处理即可,测试的数据内容如下:

map里面的核心代码如下:
/**
* 统计词频的map端
* 代码
*
* **/
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
String [] data=value.toString().split(";");//按每行的分号拆分短语
for(String s:data){
if(s.trim().length()>0){//忽略空字符
word.set(s);
context.write(word, one);
}
}
}
reduce端的核心代码如下:
/**
* reduce端的
* 代码
* **/
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();//累加词频
}
result.set(sum);
context.write(new Text(key.toString()+"::"), result);//为方便短语排序,以双冒号分隔符间隔
}
}
main函数里面的代码如下:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
运行结果,如下所示:
a good student:: 1 good student:: 3 patient:: 2 patient a:: 1
下面,散仙来分析下排序作业的代码,如上图所示hadoop默认的排序,是基于key排序的,如果是字符类型的则基于字典表 排序,如果是数值类型的则基于数字大小排序,两种方式都是按默认的升序排列的,如果想要降序输出,就需要我们自己写个排序组件了,散仙会在下面的代码给出 例子,因为我们是要基于词频排序的,所以需要反转K,V来实现对词频的排序,map端代码如下:
/**
* 排序作业
* map的实现
*
* **/
@Override
protected void map(LongWritable key, Text value,Context context)throws IOException, InterruptedException {
String s[]=value.toString().split("::");//按两个冒号拆分每行数据
word.set(s[0]);//
one.set(Integer.parseInt(s[1].trim()));//
context.write(one, word);//注意,此部分,需要反转K,V顺序
}
reduce端代码如下:
/***
*
* 排序作业的
* reduce代码
* **/
@Override
protected void reduce(IntWritable arg0, Iterable<Text> arg1, Context arg2)
throws IOException, InterruptedException {
for(Text t:arg1){
result.set(t.toString());
arg2.write(result, arg0);
}
}
下面,我们再来看下排序组件的代码:
/***
* 按词频降序排序
* 的类
*
* **/
public static class DescSort extends WritableComparator{
public DescSort() {
super(IntWritable.class,true);//注册排序组件
}
@Override
public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3,
int arg4, int arg5) {
return -super.compare(arg0, arg1, arg2, arg3, arg4, arg5);//注意使用负号来完成降序
}
@Override
public int compare(Object a, Object b) {
return -super.compare(a, b);//注意使用负号来完成降序
}
}
main方法里面的实现代码如下所示:
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job=new Job(conf, "sort");
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(SortIntValueMapper.class);
job.setReducerClass(SortIntValueReducer.class) ;
job.setSortComparatorClass(DescSort.class);//加入排序组件
job.setInputFormatClass(org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
输出结果,如下所示:
good student 3 patient 2 a good student 1 patient a 1
至此,我们可以成功实现,统计并排序的业务,当然这种类型的需求非常多而且常见,如对某个海量日志IP的分析,散仙上面的例 子使用的只是测试的数据,而真实数据是对几亿或几十亿的短语构建语料库使用,配置集群方面,可以根据自己的需求,配置集群的节点个数以及 map,reduce的个数,而代码,只需要我们写好,提交给hadoop集群执行即可。
最后在简单总结一下,数据处理过程中,格式是需要提前定制好的,也就是说你得很清楚的你的格式代表什么意思,另外一点,关于 hadoop的中文编码问题,这个是内部固定的UTF-8格式,如果你是GBK的文件编码,则需要自己单独在map或reduce过程中处理一下,否则输 出的结果可能是乱码,最好的方法就是统一成UTF-8格式,否则,很容易出现一些编码问题的。