Hadoop SequenceFile 文件写入及格式分析
Hadoop SequenceFile 是一个由二进制形式key/value的字节流组成的存储文件,SequenceFile可压缩可切分,非常适合hadoop文件存储特性,SequenceFile的写入由SequenceFile.Writer来实现, 根据压缩类型SequenceFile.Writer又派生出两个子类SequenceFile.BlockCompressWriter和SequenceFile.RecordCompressWriter, 压缩方式由SequenceFile类的内部枚举类CompressionType来表示,定义了三种方式
不采用压缩:
CompressionType.NONE
记录级别的压缩:
CompressionType.RECORD
块级别的压缩:
CompressionType.BLOCK
使用时可以通过参数: io.seqfile.compression.type=[NONE|RECORD|BLOCK] 来指定具体的压缩方式.

写入SequenceFile时通过创建一个SequenceFile.Writer来实现SequenceFile.Writer writer = SequenceFile.createWriter然后调用writer.append(key, value);方法进行数据写入, 根据指定的压缩方式不同,写入时SequenceFile组织内部结构也有所不同.
SequenceFile Header在三种压缩方式都是相同的,在创建SequenceFile.Writer对象时在构造函数中依次调用
initializeFileHeader(); writeFileHeader(); finalizeFileHeader();
来完成文件头的写入.
SequenceFile文件头格式如下:

SequenceFile 内容,根据指定的压缩方式不同,组织结构也有所不同,当压缩方式指定为CompressionType.NONE,CompressionType.RECORD时,文件内容由 同步标记+RECODE 组成,当压缩方式指定为CompressionType.BLOCK时,文件内容由 同步标记+BLOCK 组成
同步标记+RECODE:
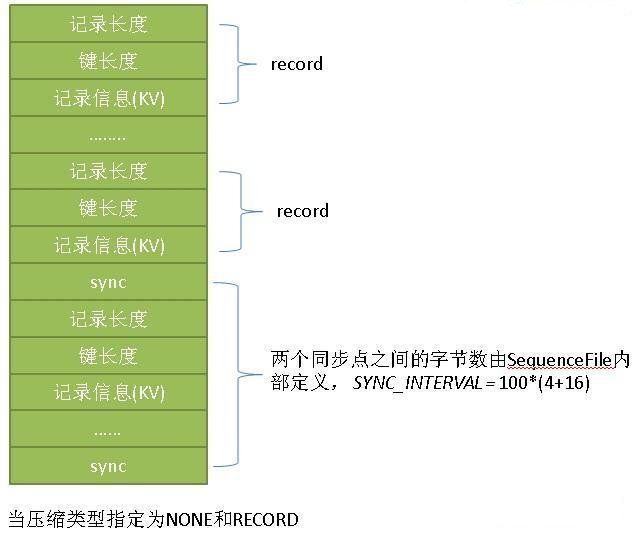
输出流会维护一个上次插入同步点时的记录位置(lastSyncPos,初始为0),每次append(key, value)时都会检查当前输出流pos与上次同步点之间的距离是否大于等于SYNC_INTERVAL, 如果是, 就会插入一个同步点(sync)
CompressionType.NONE 时 记录信息不压缩
CompressionType.RECORD 时 记录信息压缩(单条记录压缩)
同步标记+BLOCK:

BlockCompressWriter内部维护keyBuffer,valBuffer,每次append(key, value)时会把key和value对象序列化到keyBuffer和valBuffer, 并判断keyBuffer和valBuffer相加后的size是否大于等于compressionBlockSize, 如果是则插入一个同步点,并刷出数据流成一个block.
每个block与block之间都会有一个同步点(sync)
一个block内会有多条记录组成,压缩是作用在block之上的,比RECODE方式能获得更好的压缩比
compressionBlockSize可以通过io.seqfile.compress.blocksize=size参数指定,默认值是1000000