mahout 实现canopy
环境:
mahout-0.8
hadoop-1.1.2
ubuntu-12.04
理论这里就不说了,直接上实例:
下面举一个例子。
数据准备:
canopy.dat文件,COPY到HDFS上,文件内容如下:
8.1 8.1 7.1 7.1 6.2 6.2 7.1 7.1 2.1 2.1 1.1 1.1 0.1 0.1 3.0 3.0
算法简单说明,步骤如下:
(1) 将所有数据放进list中,选择两个距离,T1,T2,T1>T2
(2)While(list不为空)
{
随机选择一个节点做canopy的中心;并从list删除该点;
遍历list:
对于任何一条记录,计算其到各个canopy的距离;
如果距离<T2,则给此数据打上强标记,并从list删除这条记录;
如果距离<T1,则给此数据打上弱标记;
如果到任何canopy中心的聚类都>T1,那么将这条记录作为一个新的canopy的中心,并从list中删除这个元素;
}
预期的结果应该是:
Canopy 1 (8.1,8.1) :[ (8.1,8.1), (7.1,7.1), (6.2,6.2) ,(7.1,7.1) ] Canopy 2 (2.1,2.1) :[ (2.1,2.1), (1.1,1.1) ,(0.1,0.1), (3.0,3.0) ] Canopy 3 (0.1,0.1) :[ (0.1,0.1)]
下面开始用Mahout实现
# 1.将数据文件转换成向量
mahout用InputDriver数据转换时候,需要数据默认用空格分隔
mahout org.apache.mahout.clustering.conversion.InputDriver -i /user/hdfs/canopy/in/canopy.dat -o /user/hdfs/canopy/vecfile -v org.apache.mahout.math.RandomAccessSparseVector
# 2. 调用命令
mahout canopy -i /user/hdfs/canopy/vecfile -o /user/hdfs/canopy/out/result -t1 8 -t2 4 -ow -cl
参数说明:
| CanopyDriver.main(args); |
|
| --input (-i) |
输入路径 |
| --output(-o) |
输出路径 |
| --distanceMeasure(-dm) |
距离度量类的权限命名,如:”org.apache.mahout.common.distance.CosineDistanceMeasure” |
| --t1 (-t1) |
t1值 (t1>t2) |
| --t2 (-t2) |
t2值 |
| --t3 (-t3) |
t3值,默认t3=t1 |
| --t4(-t4) |
t4值,默认t4=t2 |
| --overwrite (-ow) |
是否覆盖上次操作的结果 |
| --clustering (-cl) |
是否执行聚类操作,即划分数据 |
| --method (-method) |
默认,mapreduce。还可选sequential,执行单机模式 |
# 3.查看结果
mahout seqdumper -i /user/hdfs/canopy/out/result/clusters-0-final/part-r-00000 -o /home/hadoop/output/result #关联各个点 mahout clusterdump -i /user/hdfs/canopy/out/result/clusters-0-final/part-r-00000 -o /home/hadoop/output/result -p /user/hdfs/canopy/out/result/clusteredPoints
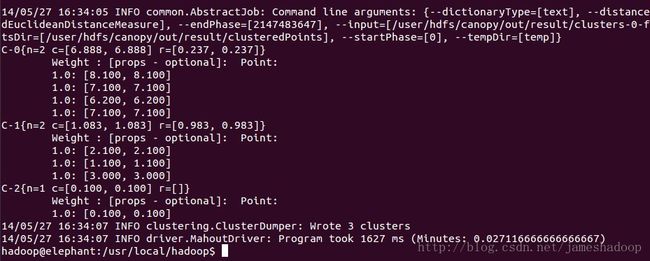
C-0{n=2 c=[6.888, 6.888] r=[0.237, 0.237]}
Weight : [props - optional]: Point:
1.0: [8.100, 8.100]
1.0: [7.100, 7.100]
1.0: [6.200, 6.200]
1.0: [7.100, 7.100]
C-1{n=2 c=[1.083, 1.083] r=[0.983, 0.983]}
Weight : [props - optional]: Point:
1.0: [2.100, 2.100]
1.0: [1.100, 1.100]
1.0: [3.000, 3.000]
C-2{n=1 c=[0.100, 0.100] r=[]}
Weight : [props - optional]: Point:
1.0: [0.100, 0.100]