HBase 写优化之 BulkLoad 实现数据快速入库
HBase 写优化之 BulkLoad 实现数据快速入库
目录[-]
1、为何要 BulkLoad 导入?传统的 HTableOutputFormat 写 HBase 有什么问题?
我们先看下 HBase 的写流程:
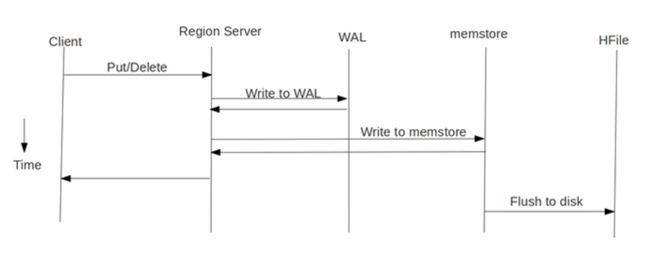
通常 MapReduce 在写HBase时使用的是 TableOutputFormat 方式,在reduce中直接生成put对象写入HBase,该方式在大数据量写入时效率低下(HBase会block写入,频繁进行flush,split,compact等大量IO操作),并对HBase节点的稳定性造成一定的影响(GC时间过长,响应变慢,导致节点超时退出,并引起一系列连锁反应),而HBase支持 bulk load 的入库方式,它是利用hbase的数据信息按照特定格式存储在hdfs内这一原理,直接在HDFS中生成持久化的HFile数据格式文件,然后上传至合适位置,即完成巨量数据快速入库的办法。配合mapreduce完成,高效便捷,而且不占用region资源,增添负载,在大数据量写入时能极大的提高写入效率,并降低对HBase节点的写入压力。
通过使用先生成HFile,然后再BulkLoad到Hbase的方式来替代之前直接调用HTableOutputFormat的方法有如下的好处:
(1)消除了对HBase集群的插入压力
(2)提高了Job的运行速度,降低了Job的执行时间
目前此种方式仅仅适用于只有一个列族的情况,在新版 HBase 中,单列族的限制会消除。
2、bulkload 流程与实践
bulkload 方式需要两个Job配合完成:(1)第一个Job还是运行原来业务处理逻辑,处理的结果不直接调用HTableOutputFormat写入到HBase,而是先写入到HDFS上的一个中间目录下(如 middata)
(2)第二个Job以第一个Job的输出(middata)做为输入,然后将其格式化HBase的底层存储文件HFile
(3)调用BulkLoad将第二个Job生成的HFile导入到对应的HBase表中
下面给出相应的范例代码:
importjava.io.IOException;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.hbase.HBaseConfiguration;
importorg.apache.hadoop.hbase.KeyValue;
importorg.apache.hadoop.hbase.client.HTable;
importorg.apache.hadoop.hbase.client.Put;
importorg.apache.hadoop.hbase.io.ImmutableBytesWritable;
importorg.apache.hadoop.hbase.mapreduce.HFileOutputFormat;
importorg.apache.hadoop.hbase.mapreduce.KeyValueSortReducer;
importorg.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
importorg.apache.hadoop.hbase.util.Bytes;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.LongWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.Mapper;
importorg.apache.hadoop.mapreduce.Reducer;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.input.TextInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
importorg.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
importorg.apache.hadoop.util.GenericOptionsParser;
publicclass GeneratePutHFileAndBulkLoadToHBase {
publicstatic class WordCountMapper extendsMapper<LongWritable, Text, Text, IntWritable>
{
privateText wordText=newText();
privateIntWritable one=newIntWritable(1);
@Override
protectedvoid map(LongWritable key, Text value, Context context)
throwsIOException, InterruptedException {
// TODO Auto-generated method stub
String line=value.toString();
String[] wordArray=line.split(" ");
for(String word:wordArray)
{
wordText.set(word);
context.write(wordText, one);
}
}
}
publicstatic class WordCountReducer extendsReducer<Text, IntWritable, Text, IntWritable>
{
privateIntWritable result=newIntWritable();
protectedvoid reduce(Text key, Iterable<IntWritable> valueList,
Context context)
throwsIOException, InterruptedException {
// TODO Auto-generated method stub
intsum=0;
for(IntWritable value:valueList)
{
sum+=value.get();
}
result.set(sum);
context.write(key, result);
}
}
publicstatic class ConvertWordCountOutToHFileMapper extendsMapper<LongWritable, Text, ImmutableBytesWritable, Put>
{
@Override
protectedvoid map(LongWritable key, Text value, Context context)
throwsIOException, InterruptedException {
// TODO Auto-generated method stub
String wordCountStr=value.toString();
String[] wordCountArray=wordCountStr.split("\t");
String word=wordCountArray[0];
intcount=Integer.valueOf(wordCountArray[1]);
//创建HBase中的RowKey
byte[] rowKey=Bytes.toBytes(word);
ImmutableBytesWritable rowKeyWritable=newImmutableBytesWritable(rowKey);
byte[] family=Bytes.toBytes("cf");
byte[] qualifier=Bytes.toBytes("count");
byte[] hbaseValue=Bytes.toBytes(count);
// Put 用于列簇下的多列提交,若只有一个列,则可以使用 KeyValue 格式
// KeyValue keyValue = new KeyValue(rowKey, family, qualifier, hbaseValue);
Put put=newPut(rowKey);
put.add(family, qualifier, hbaseValue);
context.write(rowKeyWritable, put);
}
}
publicstatic void main(String[] args) throwsException {
// TODO Auto-generated method stub
Configuration hadoopConfiguration=newConfiguration();
String[] dfsArgs = newGenericOptionsParser(hadoopConfiguration, args).getRemainingArgs();
//第一个Job就是普通MR,输出到指定的目录
Job job=newJob(hadoopConfiguration, "wordCountJob");
job.setJarByClass(GeneratePutHFileAndBulkLoadToHBase.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,newPath(dfsArgs[0]));
FileOutputFormat.setOutputPath(job,newPath(dfsArgs[1]));
//提交第一个Job
intwordCountJobResult=job.waitForCompletion(true)?0:1;
//第二个Job以第一个Job的输出做为输入,只需要编写Mapper类,在Mapper类中对一个job的输出进行分析,并转换为HBase需要的KeyValue的方式。
Job convertWordCountJobOutputToHFileJob=newJob(hadoopConfiguration, "wordCount_bulkload");
convertWordCountJobOutputToHFileJob.setJarByClass(GeneratePutHFileAndBulkLoadToHBase.class);
convertWordCountJobOutputToHFileJob.setMapperClass(ConvertWordCountOutToHFileMapper.class);
//ReducerClass 无需指定,框架会自行根据 MapOutputValueClass 来决定是使用 KeyValueSortReducer 还是 PutSortReducer
//convertWordCountJobOutputToHFileJob.setReducerClass(KeyValueSortReducer.class);
convertWordCountJobOutputToHFileJob.setMapOutputKeyClass(ImmutableBytesWritable.class);
convertWordCountJobOutputToHFileJob.setMapOutputValueClass(Put.class);
//以第一个Job的输出做为第二个Job的输入
FileInputFormat.addInputPath(convertWordCountJobOutputToHFileJob,newPath(dfsArgs[1]));
FileOutputFormat.setOutputPath(convertWordCountJobOutputToHFileJob,newPath(dfsArgs[2]));
//创建HBase的配置对象
Configuration hbaseConfiguration=HBaseConfiguration.create();
//创建目标表对象
HTable wordCountTable =newHTable(hbaseConfiguration, "word_count");
HFileOutputFormat.configureIncrementalLoad(convertWordCountJobOutputToHFileJob,wordCountTable);
//提交第二个job
intconvertWordCountJobOutputToHFileJobResult=convertWordCountJobOutputToHFileJob.waitForCompletion(true)?0:1;
//当第二个job结束之后,调用BulkLoad方式来将MR结果批量入库
LoadIncrementalHFiles loader = newLoadIncrementalHFiles(hbaseConfiguration);
//第一个参数为第二个Job的输出目录即保存HFile的目录,第二个参数为目标表
loader.doBulkLoad(newPath(dfsArgs[2]), wordCountTable);
//最后调用System.exit进行退出
System.exit(convertWordCountJobOutputToHFileJobResult);
}
}
|
|
如原始的输入数据的目录为:/rawdata/test/wordcount/20131212
|
最终生成的HFile保存的目录为:/resultdata/test/wordcount/20131212
运行上面的Job的方式如下:
hadoop jar test.jar /rawdata/test/wordcount/20131212 /middata/test/wordcount/20131212 /resultdata/test/wordcount/20131212
3、说明与注意事项:
(1)HFile方式在所有的加载方案里面是最快的,不过有个前提——数据是第一次导入,表是空的。如果表中已经有了数据。HFile再导入到hbase的表中会触发split操作。
(2)最终输出结果,无论是map还是reduce,输出部分key和value的类型必须是: < ImmutableBytesWritable, KeyValue>或者< ImmutableBytesWritable, Put>。
否则报这样的错误:
|
1
2
3
|
java.lang.IllegalArgumentException: Can't read partitions file
...
Caused by: java.io.IOException: wrong key
class
: org.apache.hadoop.io.*** is not
class
org.apache.hadoop.hbase.io.ImmutableBytesWritable
|
|
1
2
3
4
5
6
7
|
if
(KeyValue.
class
.equals(job.getMapOutputValueClass())) {
job.setReducerClass(KeyValueSortReducer.
class
);
}
else
if
(Put.
class
.equals(job.getMapOutputValueClass())) {
job.setReducerClass(PutSortReducer.
class
);
}
else
{
LOG.warn(
"Unknown map output value type:"
+ job.getMapOutputValueClass());
}
|
(5) MR例子中最后生成HFile存储在HDFS上,输出路径下的子目录是各个列族。如果对HFile进行入库HBase,相当于move HFile到HBase的Region中,HFile子目录的列族内容没有了。
(6)最后一个 Reduce 没有 setNumReduceTasks 是因为,该设置由框架根据region个数自动配置的。
(7)下边配置部分,注释掉的其实写不写都无所谓,因为看源码就知道configureIncrementalLoad方法已经把固定的配置全配置完了,不固定的部分才需要手动配置。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
public
class
HFileOutput {
//job 配置
public
static
Job configureJob(Configuration conf)
throws
IOException {
Job job =
new
Job(configuration,
"countUnite1"
);
job.setJarByClass(HFileOutput.
class
);
//job.setNumReduceTasks(2);
//job.setOutputKeyClass(ImmutableBytesWritable.class);
//job.setOutputValueClass(KeyValue.class);
//job.setOutputFormatClass(HFileOutputFormat.class);
Scan scan =
new
Scan();
scan.setCaching(
10
);
scan.addFamily(INPUT_FAMILY);
TableMapReduceUtil.initTableMapperJob(inputTable, scan,
HFileOutputMapper.
class
, ImmutableBytesWritable.
class
, LongWritable.
class
, job);
//这里如果不定义reducer部分,会自动识别定义成KeyValueSortReducer.class 和PutSortReducer.class
job.setReducerClass(HFileOutputRedcuer.
class
);
//job.setOutputFormatClass(HFileOutputFormat.class);
HFileOutputFormat.configureIncrementalLoad(job,
new
HTable(
configuration, outputTable));
HFileOutputFormat.setOutputPath(job,
new
Path());
//FileOutputFormat.setOutputPath(job, new Path()); //等同上句
return
job;
}
public
static
class
HFileOutputMapper
extends
TableMapper<ImmutableBytesWritable, LongWritable> {
public
void
map(ImmutableBytesWritable key, Result values,
Context context)
throws
IOException, InterruptedException {
//mapper逻辑部分
context.write(
new
ImmutableBytesWritable(Bytes()), LongWritable());
}
}
public
static
class
HFileOutputRedcuer
extends
Reducer<ImmutableBytesWritable, LongWritable, ImmutableBytesWritable, KeyValue> {
public
void
reduce(ImmutableBytesWritable key, Iterable<LongWritable> values,
Context context)
throws
IOException, InterruptedException {
//reducer逻辑部分
KeyValue kv =
new
KeyValue(row, OUTPUT_FAMILY, tmp[
1
].getBytes(),
Bytes.toBytes(count));
context.write(key, kv);
}
}
}
|
4、Refer:
1、Hbase几种数据入库(load)方式比较
http://blog.csdn.net/kirayuan/article/details/6371635
2、MapReduce生成HFile入库到HBase及源码分析
http://blog.pureisle.net/archives/1950.html
3、MapReduce生成HFile入库到HBase
http://shitouer.cn/2013/02/hbase-hfile-bulk-load/