关于位图排序
输入: 一个包含n个正整数的文件,每个正整数小于n,n等于10的7次方(一千万)。并且文件内的正整数没有重复和关联数据。
输出: 输入整数的升序排列
约束: 限制在1M左右内存,充足的磁盘空间
假设整数占32位,1M内存可以存储大概250000个整数,第一个方法就是采用基于磁盘的合并排序算法,第二个办法就是将0-9999999切割成40个区间,分40次扫描(10000000/250000),每次读入250000个在一个区间的整数,并在内存中使用快速排序。书中提出的第三个解决办法是采用bitmap(或者称为bit vector)来表示所有数据集合(注意到条件,数据没有重复),这样就可以一次性将数据读入内存,减少了扫描次数。算法的伪代码如下:
阶段1:初始化一个空集合
for i=[0,n)
bit[i]=0;
阶段2:读入数据i,并设置bit[i]=1
for each i in the input file
bit[i]=1;
阶段3:输出排序的结果
for i=[0,n)
if bit[i]==1
write i on the output file
算法的时间复杂度为O(N)
代码如下:
#define WORD 32 #define SHIFT 5 #define MASK 0x1F #define N 10000000 int a[1+N/WORD]; //置位函数——用"|"操作符,i&MASK相当于mod操作 //m mod n 运算,当n = 2的X次幂的时候,m mod n = m&(n-1) void set(int i) {a[i>>SHIFT]|=(1<<(i&MASK));} //清除位操作,用&~操作符 void clear(int i) {a[i>>SHIFT]&=~(1<<(i&MASK));} //测试位操作用&操作符 int test(int i) {return a[i>>SHIFT]&(1<<(i&MASK));} //---------------------main函数-------------------- int main() { int i; for(i =0 ;i< N;i++) { clear(i);//初始化位图 } while(scanf("%d",&i)!=EOF) { set(i); } for(i =0 ;i< N;i++) { if(test(i)) printf("%d ",i); } return 0; }
======================基于位图的整数序列合并算法=======================
搜索引擎检索时,常常要将两个结果进行组合处理,例如查询“中国北京”,则需要将包含“中国”和“北京”的文档编号序列进行合并的操作。常用的算法有归并,先排序后去重等,但这些算法在大数据量的情况下,如对包含“中国”的10万个文档编号序列和包含“北京”的8万个文档编号序列进行组合时,效率比较低,无法满足搜索引擎高速的检索要求。我们引入了基于二进制数组的算法来解决这个问题。
基于二进制数组的整数序列合并算法是一种高速的多个整数序列组合的算法。它的基本原理是将各整数序列保存在一个二进制的数组当中,然后对这些二进制数组进行并,或的运算。
下面详细介绍一下此算法的处理过程。
1. 将整数序列转为二进制数组。
先申请一个二进制数组,其大小为有可能出现的最大的整数值,如500万,如图所示。
假设有5个整数组成的序列{2,3,200,7000,12000},则我们可以将这个序列保存在二进制数组当中,如图2所示,第n位如果为1,则表示n存在于这个序列中:

2. 对两个序列进行位运算。
如果需要对两个整数序列进行并的操作,那么只需要对它们对应的二进制数组进行“并”的位运算;如果需要对两个整数序列进行或的操作,那么只需要对它们对应的二进制数组进行“或”的位运算;如果需要对两个整数序列进行NOT的操作,那么只需要对它们对应的二进制数组先进行“并”的位运算,再进行“异或”的位运算。
计算机进行位运算的速度是最快的。在实际的程序中,我们可以以long类型为基本的位运算单位,相同位置的long型数据进行两两位运算,以提高速度。
3. 将二进制数组转为结果整数序列。
位运算结束后,需要将这个结果再转为整数序列。这个转换后的整数序列就是我们需要的最终结果。
下面是一次完整的运算过程,我们需要将{2,3,300}和{2,3,200,7000,12000}这两个序列进行并的操作。如图3所示。
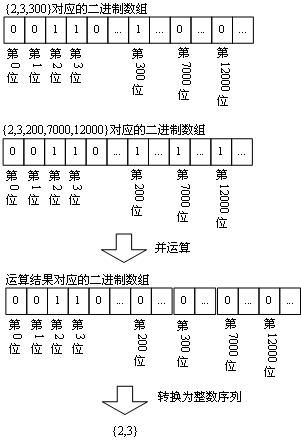
整数序列{2,3}即是我们最终所要的结果。