Linux进程管理(2):进程创建的copy_process和进程销毁
4. copy_process: 进程描述符的处理
copy_process函数也在./linux/kernel/fork.c中。它会用当前进程的一个副本来创建新进程并分配pid,但不会实际启动这个新进程。它会复制寄存器中的值、所有与进程环境相关的部分,每个clone标志。新进程的实际启动由调用者来完成。
下面看copy_process的实现。
(2)标志合法性检查。对clone_flags所传递的标志组合进行合法性检查。当出现以下三种情况时,返回出错代号:
1)CLONE_NEWNS和CLONE_FS同时被设置。前者标志表示子进程需要自己的命名空间,而后者标志则代表子进程共享父进程的根目录和当前工作目录,两者不可兼容。在传统的Unix系统中,整个系统只有一个已经安装的文件系统树。每个进程从系统的根文件系统开始,通过合法的路径可以访问任何文件。在2.6版本中的内核中,每个进程都可以拥有属于自己的已安装文件系统树,也被称为命名空间。通常大多数进程都共享init进程所使用的已安装文件系统树,只有在clone_flags中设置了CLONE_NEWNS标志时,才会为此新进程开辟一个新的命名空间。
2)CLONE_THREAD被设置,但CLONE_SIGHAND未被设置。如果子进程和父进程属于同一个线程组(CLONE_THREAD被设置),那么子进程必须共享父进程的信号(CLONE_SIGHAND被设置)。
3)CLONE_SIGHAND被设置,但CLONE_VM未被设置。如果子进程共享父进程的信号,那么必须同时共享父进程的内存描述符和所有的页表(CLONE_VM被设置)。
(3)安全性检查。通过调用security_task_create()和后面的security_task_alloc()执行所有附加的安全性检查。询问 Linux Security Module (LSM) 看当前任务是否可以创建一个新任务。LSM是SELinux的核心。
(4)复制进程描述符。通过dup_task_struct()为子进程分配一个内核栈、thread_info结构和task_struct结构。注意,这里将当前进程描述符指针作为参数传递到此函数中。函数代码如下:
上面已经说明过orig是传进来的current宏,指向当前进程描述符的指针。arch_dup_task_struct直接将orig指向的当前进程描述符内容复制到当前里程描述符tsk。接着,用atomic_set将子进程描述符的使用计数器设置为2,表示该进程描述符正在被使用并且处于活动状态。最后返回指向刚刚创建的子进程描述符内存区的指针。
通过dup_task_struct可以看到,当这个函数成功操作之后,子进程和父进程的描述符中的内容是完全相同的。在稍后的copy_process代码中,我们将会看到子进程逐步与父进程区分开来。
(5)一些初始化。通过诸如ftrace_graph_init_task,rt_mutex_init_task完成某些数据结构的初始化。调用copy_creds()复制证书(应该是复制权限及身份信息)。
(6)检测系统中进程的总数量是否超过了max_threads所规定的进程最大数。
(7)复制标志。通过copy_flags,将从do_fork()传递来的的clone_flags和pid分别赋值给子进程描述符中的对应字段。
(8)初始化子进程描述符。初始化其中的各个字段,使得子进程和父进程逐渐区别出来。这部分工作包含初始化子进程中的children和sibling等队列头、初始化自旋锁和信号处理、初始化进程统计信息、初始化POSIX时钟、初始化调度相关的统计信息、初始化审计信息。它在copy_process函数中占据了相当长的一段的代码,不过考虑到task_struct结构本身的复杂性,也就不足为奇了。
(9)调度器设置。调用sched_fork函数执行调度器相关的设置,为这个新进程分配CPU,使得子进程的进程状态为TASK_RUNNING。并禁止内核抢占。并且,为了不对其他进程的调度产生影响,此时子进程共享父进程的时间片。
(10)复制进程的所有信息。根据clone_flags的具体取值来为子进程拷贝或共享父进程的某些数据结构。比如copy_semundo()、复制开放文件描述符(copy_files)、复制符号信息(copy_sighand 和 copy_signal)、复制进程内存(copy_mm)以及最终复制线程(copy_thread)。
(11)复制线程。通过copy_threads()函数更新子进程的内核栈和寄存器中的值。在之前的dup_task_struct()中只是为子进程创建一个内核栈,至此才是真正的赋予它有意义的值。
当父进程发出clone系统调用时,内核会将那个时候CPU中寄存器的值保存在父进程的内核栈中。这里就是使用父进程内核栈中的值来更新子进程寄存器中的值。特别的,内核将子进程eax寄存器中的值强制赋值为0,这也就是为什么使用fork()时子进程返回值是0。而在do_fork函数中则返回的是子进程的pid,这一点在上述内容中我们已经有所分析。另外,子进程的对应的thread_info结构中的esp字段会被初始化为子进程内核栈的基址。
(12)分配pid。用alloc_pid函数为这个新进程分配一个pid,Linux系统内的pid是循环使用的,采用位图方式来管理。简单的说,就是用每一位(bit)来标示该位所对应的pid是否被使用。分配完毕后,判断pid是否分配成功。成功则赋给p->pid。
(13)更新属性和进程数量。根据clone_flags的值继续更新子进程的某些属性。将 nr_threads加一,表明新进程已经被加入到进程集合中。将total_forks加一,以记录被创建进程数量。
(14)如果上述过程中某一步出现了错误,则通过goto语句跳到相应的错误代码处;如果成功执行完毕,则返回子进程的描述符p。
至此,copy_process()的大致执行过程分析完毕。
copy_process()执行完后返回do_fork(),do_fork()执行完毕后,虽然子进程处于可运行状态,但是它并没有立刻运行。至于子进程何时执行这完全取决于调度程序,也就是schedule()的事了。
5. 进程调度
创建好的进程最后被插入到运行队列中,它会通过 Linux 调度程序来调度。Linux调度程序维护了针对每个优先级别的一组列表,其中保存了 task_struct 引用。当正在运行的进程时间片用完时,时钟tick产生中断,调用kernel/sched.c:scheduler_tick()进程调度器的中断处理,中断返回后就会调用schedule()。运行队列中的任务通过 schedule 函数(在 ./linux/kernel/sched.c 内)来调用,它根据加载及进程执行历史决定最佳进程。这里并不涉及此函数的分析。
6. 进程销毁
进程销毁可以通过几个事件驱动 、通过正常的进程结束(当一个C程序从main函数返回时startup routine调用exit)、通过信号或是通过显式地对 exit 函数的调用。不管进程如何退出,进程的结束都要借助对内核函数 do_exit(在 ./linux/kernel/exit.c 内)的调用。函数的层次结构如下图:
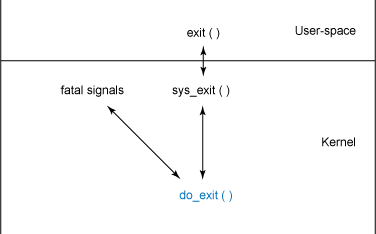
图2 进程销毁的函数层次结构
(2)清除所有信号处理函数。exit_signals函数会设置PF_EXITING标志来表明进程正在退出,并清除所有信息处理函数。内核的其他方面会利用PF_EXITING来防止在进程被删除时还试图处理此进程。
(3)清除一系列的进程资源。比如比如 exit_mm删除内存页、exit_files关闭所有打开的文件描述符,这会清理I/O缓存,如果缓存中有数据,就会将它们写入相应的文件,以防止文件数据的丢失。exit_fs清除当前目录关联的inode、exit_thread清除线程信息、等等。
(4)发出退出通知。调用exit_notify执行一系列通知。例如通知父进程我正在退出。如下:
注意在最初父进程创建子进程时,如果调用了waitpid()等待子进程结束(表示它关心子进程的状态),子进程结束时父进程会处理它发来的SIGCHILD信号。如果不调用wait(表示它不关心子进程的死活状态),则不会处理子进程的SIGCHILD信号。参看./linux/kernel/signal.c:do_notify_parent(),代码如下:
可见子进程在结束前不一定都需要经过一个EXIT_ZOMBIE过程。如果父进程调用了waitpid等待子进程,则会显示处理它发来的SIGCHILD信号,子进程结束时会自我清理(在do_exit中自己用release_task清理);如果父进程没有调用waitpid等待子进程,则不会处理SIGCHLD信号,子进程不会马上被清理,而是变成EXIT_ZOMBIE状态,成为著名的僵尸进程。还有一种特殊情形,如果子进程退出时父进程恰好正在睡眠(sleep),导致没来得急处理SIGCHLD,子进程也会成为僵尸,只要父进程在醒来后能调用waitpid,也能清理僵尸子进程,因为wait系统调用内部有清理僵尸子进程的代码。因此,如果父进程一直没有调用waitpid,那么僵尸子进程就只能等到父进程退出时被init接管了。init进程会负责清理这些僵尸进程(init肯定会调用wait)。
我们可以写个简单的程序来验证,父进程创建10个子进程,子进程sleep一段时间后退出。第一种情况,父进程只对1~9号子进程调用waitpid(),1~9号子进程都正常结束,而在父进程结束前,pids[0]为EXIT_ZOMBIE。第二种情况,父进程创建10个子进程后,sleep()一段时间,在这段时间内_exit()的子进程都成为EXIT_ZOMBIE。父进程sleep()结束后,依次调用waitpid(),子进程马上变为EXIT_DEAD被清理。
为了更好地理解怎么清理僵尸进程,我们简要地分析一下wait系统调用。wait族的系统调用如waitpid,wait4等,最后都会进入./linux/kernel/exit.c:do_wait()内核例程,而后函数链为do_wait()--->do_wait_thread()--->wait_consider_task(),在这里,如果子进程在exit_notify中设置的tsk->exit_state为EXIT_DEAD,就返回0,即wait系统调用返回,说明子进程不是僵尸进程,会自己用release_task进行回收。如果它的exit_state是EXIT_ZOMBIE,进入wait_task_zombie()。在这里使用xchg尝试把它的exit_state设置为EXIT_DEAD,可见父进程的wait4调用会把子进程由EXIT_ZOMBIE设置为EXIT_DEAD。最后wait_task_zombie()在末尾调用release_task()清理这个僵尸进程。
(5)设置销毁标志并调度新的进程。在do_exit的最后,用exit_io_context清除IO上下文、preempt_disable禁用抢占,设置进程状态为TASK_DEAD,然后调用./linux/kernel/sched.c:schedule()来选择一个将要执行的新进程。注意进程在退出并回收之后,其位于调度器的进程列表中的进程描述符(PCB)并没有立即释放,必须在设置task_struct的state为TASK_DEAD之后,由schedule()中的finish_task_switch()--->put_task_struct()把它的PCB重新放回到free list(可用列表)中,这时PCB才算释放,然后切换到新的进程。
copy_process函数也在./linux/kernel/fork.c中。它会用当前进程的一个副本来创建新进程并分配pid,但不会实际启动这个新进程。它会复制寄存器中的值、所有与进程环境相关的部分,每个clone标志。新进程的实际启动由调用者来完成。
对于每一个进程而言,内核为其单独分配了一个内存区域,这个区域存储的是内核栈和该进程所对应的一个小型进程描述符thread_info结构。在./linux/arch/x86/include/asm/thread_info.h中,如下:
struct thread_info {
struct task_struct *task; /* 主进程描述符 */
struct exec_domain *exec_domain; /* 执行域 */
__u32 flags; /* 低级别标志 */
__u32 status; /* 线程同步标志 */
__u32 cpu; /* 当前CPU */
int preempt_count; /* 0 => 可抢占, <0 => BUG */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
unsigned long previous_esp; /* 先前栈的ESP,以防嵌入的(IRQ)栈 */
__u8 supervisor_stack[0];
#endif
int uaccess_err;
};
/* ... */
/* 怎样从C获取当前栈指针 */
register unsigned long current_stack_pointer asm("esp") __used;
/* 怎样从C获取当前线程信息结构 */
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
} 之所以将线程信息结构称之为小型的进程描述符,是因为在这个结构中并没有直接包含与进程相关的字段,而是通过task字段指向具体某个进程描述符。通常这块内存区域的大小是8KB,也就是两个页的大小(有时候也使用一个页来存储,即4KB)。一个进程的内核栈和thread_info结构之间的逻辑关系如下图所示:
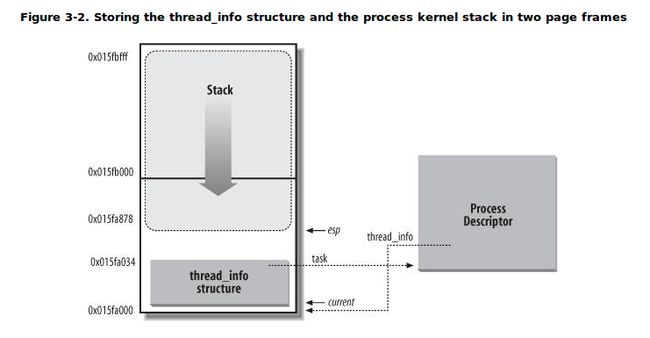
图1 进程内核栈和thread_info结构的存储
从上图可知,内核栈是从该内存区域的顶层向下(从高地址到低地址)增长的,而thread_info结构则是从该区域的开始处向上(从低地址到高地址)增长。内核栈的栈顶地址存储在esp寄存器中。所以,当进程从用户态切换到内核态后,esp寄存器指向这个区域的末端。从代码的角度来看,内核栈和thread_info结构是被定义在./linux/include/linux/sched.h中的一个联合体当中的:
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
}; 其中,THREAD_SIZE的值取8192时,stack数组的大小为2048;THREAD_SIZE的值取4096时,stack数组的大小为 1024。现在我们应该思考,为何要将内核栈和thread_info(其实也就相当于task_struct,只不过使用thread_info结构更节省空间)紧密的放在一起?最主要的原因就是内核可以很容易的通过esp寄存器的值获得当前正在运行进程的thread_info结构的地址,进而获得当前进程描述符的地址。在上面的current_thread_info函数中,定义current_stack_pointer的这条内联汇编语句会从esp寄存器中获取内核栈顶地址,和~(THREAD_SIZE - 1)做与操作将屏蔽掉低13位(或12位,当THREAD_SIZE为4096时),此时所指的地址就是这片内存区域的起始地址,也就刚好是thread_info结构的地址。但是,thread_info结构的地址并不会对我们直接有用。我们通常可以轻松的通过 current宏获得当前进程的task_struct结构,前面已经列出过get_current()函数的代码。current宏返回的是thread_info结构task字段,而task正好指向与thread_info结构关联的那个进程描述符。得到 current后,我们就可以获得当前正在运行进程的描述符中任何一个字段了,比如我们通常所做的current->pid。
下面看copy_process的实现。
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) && !(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way of the above,
* thread groups also imply shared VM. Blocking this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) && !(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on exit since they are
* not reaped by their parent (swapper). To solve this and to avoid
* multi-rooted process trees, prevent global and container-inits
* from creating siblings.
*/
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes) >=
p->signal->rlim[RLIMIT_NPROC].rlim_cur) {
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE) &&
p->real_cred->user != INIT_USER)
goto bad_fork_free;
}
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
/*
* If multiple threads are within copy_process(), then this check
* triggers too late. This doesn't hurt, the check is only there
* to stop root fork bombs.
*/
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
p->did_exec = 0;
delayacct_tsk_init(p); /* Must remain after dup_task_struct() */
copy_flags(clone_flags, p);
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = cputime_zero;
p->stime = cputime_zero;
p->gtime = cputime_zero;
p->utimescaled = cputime_zero;
p->stimescaled = cputime_zero;
p->prev_utime = cputime_zero;
p->prev_stime = cputime_zero;
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p);
p->lock_depth = -1; /* -1 = no lock */
do_posix_clock_monotonic_gettime(&p->start_time);
p->real_start_time = p->start_time;
monotonic_to_bootbased(&p->real_start_time);
p->io_context = NULL;
p->audit_context = NULL;
cgroup_fork(p);
#ifdef CONFIG_NUMA
p->mempolicy = mpol_dup(p->mempolicy);
if (IS_ERR(p->mempolicy)) {
retval = PTR_ERR(p->mempolicy);
p->mempolicy = NULL;
goto bad_fork_cleanup_cgroup;
}
mpol_fix_fork_child_flag(p);
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
p->irq_events = 0;
#ifdef __ARCH_WANT_INTERRUPTS_ON_CTXSW
p->hardirqs_enabled = 1;
#else
p->hardirqs_enabled = 0;
#endif
p->hardirq_enable_ip = 0;
p->hardirq_enable_event = 0;
p->hardirq_disable_ip = _THIS_IP_;
p->hardirq_disable_event = 0;
p->softirqs_enabled = 1;
p->softirq_enable_ip = _THIS_IP_;
p->softirq_enable_event = 0;
p->softirq_disable_ip = 0;
p->softirq_disable_event = 0;
p->hardirq_context = 0;
p->softirq_context = 0;
#endif
#ifdef CONFIG_LOCKDEP
p->lockdep_depth = 0; /* no locks held yet */
p->curr_chain_key = 0;
p->lockdep_recursion = 0;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
p->blocked_on = NULL; /* not blocked yet */
#endif
p->bts = NULL;
/* Perform scheduler related setup. Assign this task to a CPU. */
sched_fork(p, clone_flags);
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
if ((retval = audit_alloc(p)))
goto bad_fork_cleanup_policy;
/* copy all the process information */
if ((retval = copy_semundo(clone_flags, p)))
goto bad_fork_cleanup_audit;
if ((retval = copy_files(clone_flags, p)))
goto bad_fork_cleanup_semundo;
if ((retval = copy_fs(clone_flags, p)))
goto bad_fork_cleanup_files;
if ((retval = copy_sighand(clone_flags, p)))
goto bad_fork_cleanup_fs;
if ((retval = copy_signal(clone_flags, p)))
goto bad_fork_cleanup_sighand;
if ((retval = copy_mm(clone_flags, p)))
goto bad_fork_cleanup_signal;
if ((retval = copy_namespaces(clone_flags, p)))
goto bad_fork_cleanup_mm;
if ((retval = copy_io(clone_flags, p)))
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
if (clone_flags & CLONE_NEWPID) {
retval = pid_ns_prepare_proc(p->nsproxy->pid_ns);
if (retval < 0)
goto bad_fork_free_pid;
}
}
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
if (current->nsproxy != p->nsproxy) {
retval = ns_cgroup_clone(p, pid);
if (retval)
goto bad_fork_free_pid;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID) ? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID) ? child_tidptr: NULL;
#ifdef CONFIG_FUTEX
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
#endif
/*
* sigaltstack should be cleared when sharing the same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK)) == CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing should be turned off in the child regardless
* of CLONE_PTRACE.
*/
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
clear_all_latency_tracing(p);
/* ok, now we should be set up.. */
p->exit_signal = (clone_flags & CLONE_THREAD) ? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
/*
* Ok, make it visible to the rest of the system.
* We dont wake it up yet.
*/
p->group_leader = p;
INIT_LIST_HEAD(&p->thread_group);
/* Now that the task is set up, run cgroup callbacks if
* necessary. We need to run them before the task is visible
* on the tasklist. */
cgroup_fork_callbacks(p);
cgroup_callbacks_done = 1;
/* Need tasklist lock for parent etc handling! */
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD)) {
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(¤t->sighand->siglock);
/*
* Process group and session signals need to be delivered to just the
* parent before the fork or both the parent and the child after the
* fork. Restart if a signal comes in before we add the new process to
* it's process group.
* A fatal signal pending means that current will exit, so the new
* thread can't slip out of an OOM kill (or normal SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
if (clone_flags & CLONE_THREAD) {
atomic_inc(¤t->signal->count);
atomic_inc(¤t->signal->live);
p->group_leader = current->group_leader;
list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group);
}
if (likely(p->pid)) {
list_add_tail(&p->sibling, &p->real_parent->children);
tracehook_finish_clone(p, clone_flags, trace);
if (thread_group_leader(p)) {
if (clone_flags & CLONE_NEWPID)
p->nsproxy->pid_ns->child_reaper = p;
p->signal->leader_pid = pid;
tty_kref_put(p->signal->tty);
p->signal->tty = tty_kref_get(current->signal->tty);
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__get_cpu_var(process_counts)++;
}
attach_pid(p, PIDTYPE_PID, pid);
nr_threads++;
}
total_forks++;
spin_unlock(¤t->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
perf_event_fork(p);
return p;
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
put_io_context(p->io_context);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
__cleanup_signal(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_policy:
perf_event_free_task(p);
#ifdef CONFIG_NUMA
mpol_put(p->mempolicy);
bad_fork_cleanup_cgroup:
#endif
cgroup_exit(p, cgroup_callbacks_done);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
} (1)定义返回值亦是retval和新的进程描述符task_struct结构p。
(2)标志合法性检查。对clone_flags所传递的标志组合进行合法性检查。当出现以下三种情况时,返回出错代号:
1)CLONE_NEWNS和CLONE_FS同时被设置。前者标志表示子进程需要自己的命名空间,而后者标志则代表子进程共享父进程的根目录和当前工作目录,两者不可兼容。在传统的Unix系统中,整个系统只有一个已经安装的文件系统树。每个进程从系统的根文件系统开始,通过合法的路径可以访问任何文件。在2.6版本中的内核中,每个进程都可以拥有属于自己的已安装文件系统树,也被称为命名空间。通常大多数进程都共享init进程所使用的已安装文件系统树,只有在clone_flags中设置了CLONE_NEWNS标志时,才会为此新进程开辟一个新的命名空间。
2)CLONE_THREAD被设置,但CLONE_SIGHAND未被设置。如果子进程和父进程属于同一个线程组(CLONE_THREAD被设置),那么子进程必须共享父进程的信号(CLONE_SIGHAND被设置)。
3)CLONE_SIGHAND被设置,但CLONE_VM未被设置。如果子进程共享父进程的信号,那么必须同时共享父进程的内存描述符和所有的页表(CLONE_VM被设置)。
(3)安全性检查。通过调用security_task_create()和后面的security_task_alloc()执行所有附加的安全性检查。询问 Linux Security Module (LSM) 看当前任务是否可以创建一个新任务。LSM是SELinux的核心。
(4)复制进程描述符。通过dup_task_struct()为子进程分配一个内核栈、thread_info结构和task_struct结构。注意,这里将当前进程描述符指针作为参数传递到此函数中。函数代码如下:
int __attribute__((weak)) arch_dup_task_struct(struct task_struct *dst,
struct task_struct *src)
{
*dst = *src;
return 0;
}
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int err;
prepare_to_copy(orig);
tsk = alloc_task_struct();
if (!tsk)
return NULL;
ti = alloc_thread_info(tsk);
if (!ti) {
free_task_struct(tsk);
return NULL;
}
err = arch_dup_task_struct(tsk, orig);
if (err)
goto out;
tsk->stack = ti;
err = prop_local_init_single(&tsk->dirties);
if (err)
goto out;
setup_thread_stack(tsk, orig);
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* 用于溢出检测 */
#ifdef CONFIG_CC_STACKPROTECTOR
tsk->stack_canary = get_random_int();
#endif
/* One for us, one for whoever does the "release_task()" (usually parent) */
atomic_set(&tsk->usage,2);
atomic_set(&tsk->fs_excl, 0);
#ifdef CONFIG_BLK_DEV_IO_TRACE
tsk->btrace_seq = 0;
#endif
tsk->splice_pipe = NULL;
account_kernel_stack(ti, 1);
return tsk;
out:
free_thread_info(ti);
free_task_struct(tsk);
return NULL;
} 首先,该函数分别定义了指向task_struct和thread_info结构体的指针。接着,prepare_to_copy为正式的分配进程描述符做一些准备工作。主要是将一些必要的寄存器的值保存到父进程的thread_info结构中。这些值会在稍后被复制到子进程的thread_info结构中。执行alloc_task_struct宏,该宏负责为子进程的进程描述符分配空间,将该片内存的首地址赋值给tsk,随后检查这片内存是否分配正确。执行alloc_thread_info宏,为子进程获取一块空闲的内存区,用来存放子进程的内核栈和thread_info结构,并将此会内存区的首地址赋值给ti变量,随后检查是否分配正确。
上面已经说明过orig是传进来的current宏,指向当前进程描述符的指针。arch_dup_task_struct直接将orig指向的当前进程描述符内容复制到当前里程描述符tsk。接着,用atomic_set将子进程描述符的使用计数器设置为2,表示该进程描述符正在被使用并且处于活动状态。最后返回指向刚刚创建的子进程描述符内存区的指针。
通过dup_task_struct可以看到,当这个函数成功操作之后,子进程和父进程的描述符中的内容是完全相同的。在稍后的copy_process代码中,我们将会看到子进程逐步与父进程区分开来。
(5)一些初始化。通过诸如ftrace_graph_init_task,rt_mutex_init_task完成某些数据结构的初始化。调用copy_creds()复制证书(应该是复制权限及身份信息)。
(6)检测系统中进程的总数量是否超过了max_threads所规定的进程最大数。
(7)复制标志。通过copy_flags,将从do_fork()传递来的的clone_flags和pid分别赋值给子进程描述符中的对应字段。
(8)初始化子进程描述符。初始化其中的各个字段,使得子进程和父进程逐渐区别出来。这部分工作包含初始化子进程中的children和sibling等队列头、初始化自旋锁和信号处理、初始化进程统计信息、初始化POSIX时钟、初始化调度相关的统计信息、初始化审计信息。它在copy_process函数中占据了相当长的一段的代码,不过考虑到task_struct结构本身的复杂性,也就不足为奇了。
(9)调度器设置。调用sched_fork函数执行调度器相关的设置,为这个新进程分配CPU,使得子进程的进程状态为TASK_RUNNING。并禁止内核抢占。并且,为了不对其他进程的调度产生影响,此时子进程共享父进程的时间片。
(10)复制进程的所有信息。根据clone_flags的具体取值来为子进程拷贝或共享父进程的某些数据结构。比如copy_semundo()、复制开放文件描述符(copy_files)、复制符号信息(copy_sighand 和 copy_signal)、复制进程内存(copy_mm)以及最终复制线程(copy_thread)。
(11)复制线程。通过copy_threads()函数更新子进程的内核栈和寄存器中的值。在之前的dup_task_struct()中只是为子进程创建一个内核栈,至此才是真正的赋予它有意义的值。
当父进程发出clone系统调用时,内核会将那个时候CPU中寄存器的值保存在父进程的内核栈中。这里就是使用父进程内核栈中的值来更新子进程寄存器中的值。特别的,内核将子进程eax寄存器中的值强制赋值为0,这也就是为什么使用fork()时子进程返回值是0。而在do_fork函数中则返回的是子进程的pid,这一点在上述内容中我们已经有所分析。另外,子进程的对应的thread_info结构中的esp字段会被初始化为子进程内核栈的基址。
(12)分配pid。用alloc_pid函数为这个新进程分配一个pid,Linux系统内的pid是循环使用的,采用位图方式来管理。简单的说,就是用每一位(bit)来标示该位所对应的pid是否被使用。分配完毕后,判断pid是否分配成功。成功则赋给p->pid。
(13)更新属性和进程数量。根据clone_flags的值继续更新子进程的某些属性。将 nr_threads加一,表明新进程已经被加入到进程集合中。将total_forks加一,以记录被创建进程数量。
(14)如果上述过程中某一步出现了错误,则通过goto语句跳到相应的错误代码处;如果成功执行完毕,则返回子进程的描述符p。
至此,copy_process()的大致执行过程分析完毕。
copy_process()执行完后返回do_fork(),do_fork()执行完毕后,虽然子进程处于可运行状态,但是它并没有立刻运行。至于子进程何时执行这完全取决于调度程序,也就是schedule()的事了。
5. 进程调度
创建好的进程最后被插入到运行队列中,它会通过 Linux 调度程序来调度。Linux调度程序维护了针对每个优先级别的一组列表,其中保存了 task_struct 引用。当正在运行的进程时间片用完时,时钟tick产生中断,调用kernel/sched.c:scheduler_tick()进程调度器的中断处理,中断返回后就会调用schedule()。运行队列中的任务通过 schedule 函数(在 ./linux/kernel/sched.c 内)来调用,它根据加载及进程执行历史决定最佳进程。这里并不涉及此函数的分析。
6. 进程销毁
进程销毁可以通过几个事件驱动 、通过正常的进程结束(当一个C程序从main函数返回时startup routine调用exit)、通过信号或是通过显式地对 exit 函数的调用。不管进程如何退出,进程的结束都要借助对内核函数 do_exit(在 ./linux/kernel/exit.c 内)的调用。函数的层次结构如下图:
图2 进程销毁的函数层次结构
exit()调用通过0x80中断跳到sys_exit内核例程处,这个例程名称可以在./linux/include/linux/syscalls.h中找到(syscalls.h中导出所有平台无关的系统调用名称),定义为asmlinkage long sys_exit(int error_code); 它会直接调用do_exit。代码如下:
NORET_TYPE void do_exit(long code)
{
struct task_struct *tsk = current;
int group_dead;
profile_task_exit(tsk);
WARN_ON(atomic_read(&tsk->fs_excl));
if (unlikely(in_interrupt()))
panic("Aiee, killing interrupt handler!");
if (unlikely(!tsk->pid))
panic("Attempted to kill the idle task!");
/*
* If do_exit is called because this processes oopsed, it's possible
* that get_fs() was left as KERNEL_DS, so reset it to USER_DS before
* continuing. Amongst other possible reasons, this is to prevent
* mm_release()->clear_child_tid() from writing to a user-controlled
* kernel address.
*/
set_fs(USER_DS);
tracehook_report_exit(&code);
validate_creds_for_do_exit(tsk);
/*
* We're taking recursive faults here in do_exit. Safest is to just
* leave this task alone and wait for reboot.
*/
if (unlikely(tsk->flags & PF_EXITING)) {
printk(KERN_ALERT
"Fixing recursive fault but reboot is needed!\n");
/*
* We can do this unlocked here. The futex code uses
* this flag just to verify whether the pi state
* cleanup has been done or not. In the worst case it
* loops once more. We pretend that the cleanup was
* done as there is no way to return. Either the
* OWNER_DIED bit is set by now or we push the blocked
* task into the wait for ever nirwana as well.
*/
tsk->flags |= PF_EXITPIDONE;
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
exit_irq_thread();
exit_signals(tsk); /* sets PF_EXITING */
/*
* tsk->flags are checked in the futex code to protect against
* an exiting task cleaning up the robust pi futexes.
*/
smp_mb();
spin_unlock_wait(&tsk->pi_lock);
if (unlikely(in_atomic()))
printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n",
current->comm, task_pid_nr(current),
preempt_count());
acct_update_integrals(tsk);
group_dead = atomic_dec_and_test(&tsk->signal->live);
if (group_dead) {
hrtimer_cancel(&tsk->signal->real_timer);
exit_itimers(tsk->signal);
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss, tsk->mm);
}
acct_collect(code, group_dead);
if (group_dead)
tty_audit_exit();
if (unlikely(tsk->audit_context))
audit_free(tsk);
tsk->exit_code = code;
taskstats_exit(tsk, group_dead);
exit_mm(tsk);
if (group_dead)
acct_process();
trace_sched_process_exit(tsk);
exit_sem(tsk);
exit_files(tsk);
exit_fs(tsk);
check_stack_usage();
exit_thread();
cgroup_exit(tsk, 1);
if (group_dead && tsk->signal->leader)
disassociate_ctty(1);
module_put(task_thread_info(tsk)->exec_domain->module);
proc_exit_connector(tsk);
/*
* Flush inherited counters to the parent - before the parent
* gets woken up by child-exit notifications.
*/
perf_event_exit_task(tsk);
exit_notify(tsk, group_dead);
#ifdef CONFIG_NUMA
mpol_put(tsk->mempolicy);
tsk->mempolicy = NULL;
#endif
#ifdef CONFIG_FUTEX
if (unlikely(current->pi_state_cache))
kfree(current->pi_state_cache);
#endif
/*
* Make sure we are holding no locks:
*/
debug_check_no_locks_held(tsk);
/*
* We can do this unlocked here. The futex code uses this flag
* just to verify whether the pi state cleanup has been done
* or not. In the worst case it loops once more.
*/
tsk->flags |= PF_EXITPIDONE;
if (tsk->io_context)
exit_io_context();
if (tsk->splice_pipe)
__free_pipe_info(tsk->splice_pipe);
validate_creds_for_do_exit(tsk);
preempt_disable();
exit_rcu();
/* causes final put_task_struct in finish_task_switch(). */
tsk->state = TASK_DEAD;
schedule();
BUG();
/* Avoid "noreturn function does return". */
for (;;)
cpu_relax(); /* For when BUG is null */
}
EXPORT_SYMBOL_GPL(do_exit); (1)为进程销毁做一系列准备。用set_fs设置USER_DS。注意如果do_exit是因为当前进程出现不可预知的错误而被调用,这时get_fs()有可能得到的仍然是KERNEL_DS状态,因此我们要重置它为USER_DS状态。还有一个可能原因是这可以防止mm_release()->clear_child_tid()写一个被用户控制的内核地址。
(2)清除所有信号处理函数。exit_signals函数会设置PF_EXITING标志来表明进程正在退出,并清除所有信息处理函数。内核的其他方面会利用PF_EXITING来防止在进程被删除时还试图处理此进程。
(3)清除一系列的进程资源。比如比如 exit_mm删除内存页、exit_files关闭所有打开的文件描述符,这会清理I/O缓存,如果缓存中有数据,就会将它们写入相应的文件,以防止文件数据的丢失。exit_fs清除当前目录关联的inode、exit_thread清除线程信息、等等。
(4)发出退出通知。调用exit_notify执行一系列通知。例如通知父进程我正在退出。如下:
static void exit_notify(struct task_struct *tsk, int group_dead)
{
int signal;
void *cookie;
/*
* This does two things:
*
* A. Make init inherit all the child processes
* B. Check to see if any process groups have become orphaned
* as a result of our exiting, and if they have any stopped
* jobs, send them a SIGHUP and then a SIGCONT. (POSIX 3.2.2.2)
*/
forget_original_parent(tsk);
exit_task_namespaces(tsk);
write_lock_irq(&tasklist_lock);
if (group_dead)
kill_orphaned_pgrp(tsk->group_leader, NULL);
/* Let father know we died
*
* Thread signals are configurable, but you aren't going to use
* that to send signals to arbitary processes.
* That stops right now.
*
* If the parent exec id doesn't match the exec id we saved
* when we started then we know the parent has changed security
* domain.
*
* If our self_exec id doesn't match our parent_exec_id then
* we have changed execution domain as these two values started
* the same after a fork.
*/
if (tsk->exit_signal != SIGCHLD && !task_detached(tsk) &&
(tsk->parent_exec_id != tsk->real_parent->self_exec_id ||
tsk->self_exec_id != tsk->parent_exec_id))
tsk->exit_signal = SIGCHLD;
signal = tracehook_notify_death(tsk, &cookie, group_dead);
if (signal >= 0)
signal = do_notify_parent(tsk, signal);
tsk->exit_state = signal == DEATH_REAP ? EXIT_DEAD : EXIT_ZOMBIE;
/* mt-exec, de_thread() is waiting for us */
if (thread_group_leader(tsk) &&
tsk->signal->group_exit_task &&
tsk->signal->notify_count < 0)
wake_up_process(tsk->signal->group_exit_task);
write_unlock_irq(&tasklist_lock);
tracehook_report_death(tsk, signal, cookie, group_dead);
/* If the process is dead, release it - nobody will wait for it */
if (signal == DEATH_REAP)
release_task(tsk);
} exit_notify将当前进程的所有子进程的父进程ID设置为1(init),让init接管所有这些子进程。如果当前进程是某个进程组的组长,其销毁导致进程组变为“无领导状态“,则向每个组内进程发送挂起信号SIGHUP,然后发送SIGCONT。这是遵循POSIX 3.2.2.2标准。接着向自己的父进程发送SIGCHLD信号,然后调用do_notify_parent通知父进程。若返回DEATH_REAP(这个意思是不管是否有其他进程关心本进程的退出信息,自动完成进程退出和PCB销毁),就直接进入EXIT_DEAD状态,如果不是,则就需要变为EXIT_ZOMBIE状态。
注意在最初父进程创建子进程时,如果调用了waitpid()等待子进程结束(表示它关心子进程的状态),子进程结束时父进程会处理它发来的SIGCHILD信号。如果不调用wait(表示它不关心子进程的死活状态),则不会处理子进程的SIGCHILD信号。参看./linux/kernel/signal.c:do_notify_parent(),代码如下:
int do_notify_parent(struct task_struct *tsk, int sig)
{
struct siginfo info;
unsigned long flags;
struct sighand_struct *psig;
int ret = sig;
BUG_ON(sig == -1);
/* do_notify_parent_cldstop should have been called instead. */
BUG_ON(task_is_stopped_or_traced(tsk));
BUG_ON(!task_ptrace(tsk) &&
(tsk->group_leader != tsk || !thread_group_empty(tsk)));
info.si_signo = sig;
info.si_errno = 0;
/*
* we are under tasklist_lock here so our parent is tied to
* us and cannot exit and release its namespace.
*
* the only it can is to switch its nsproxy with sys_unshare,
* bu uncharing pid namespaces is not allowed, so we'll always
* see relevant namespace
*
* write_lock() currently calls preempt_disable() which is the
* same as rcu_read_lock(), but according to Oleg, this is not
* correct to rely on this
*/
rcu_read_lock();
info.si_pid = task_pid_nr_ns(tsk, tsk->parent->nsproxy->pid_ns);
info.si_uid = __task_cred(tsk)->uid;
rcu_read_unlock();
info.si_utime = cputime_to_clock_t(cputime_add(tsk->utime,
tsk->signal->utime));
info.si_stime = cputime_to_clock_t(cputime_add(tsk->stime,
tsk->signal->stime));
info.si_status = tsk->exit_code & 0x7f;
if (tsk->exit_code & 0x80)
info.si_code = CLD_DUMPED;
else if (tsk->exit_code & 0x7f)
info.si_code = CLD_KILLED;
else {
info.si_code = CLD_EXITED;
info.si_status = tsk->exit_code >> 8;
}
psig = tsk->parent->sighand;
spin_lock_irqsave(&psig->siglock, flags);
if (!task_ptrace(tsk) && sig == SIGCHLD &&
(psig->action[SIGCHLD-1].sa.sa_handler == SIG_IGN ||
(psig->action[SIGCHLD-1].sa.sa_flags & SA_NOCLDWAIT))) {
/*
* We are exiting and our parent doesn't care. POSIX.1
* defines special semantics for setting SIGCHLD to SIG_IGN
* or setting the SA_NOCLDWAIT flag: we should be reaped
* automatically and not left for our parent's wait4 call.
* Rather than having the parent do it as a magic kind of
* signal handler, we just set this to tell do_exit that we
* can be cleaned up without becoming a zombie. Note that
* we still call __wake_up_parent in this case, because a
* blocked sys_wait4 might now return -ECHILD.
*
* Whether we send SIGCHLD or not for SA_NOCLDWAIT
* is implementation-defined: we do (if you don't want
* it, just use SIG_IGN instead).
*/
ret = tsk->exit_signal = -1;
if (psig->action[SIGCHLD-1].sa.sa_handler == SIG_IGN)
sig = -1;
}
if (valid_signal(sig) && sig > 0)
__group_send_sig_info(sig, &info, tsk->parent);
__wake_up_parent(tsk, tsk->parent);
spin_unlock_irqrestore(&psig->siglock, flags);
return ret;
} 我们可以看到,如果父进程显示指定对子进程的SIGCHLD信号处理为SIG_IGN,或者标志为SA_NOCLDWAIT,则返回的是ret=-1,即DEATH_REAP(这个宏在./linux/include/tracehook.h中定义为-1),这时在exit_notify中子进程马上变为EXIT_DEAD,表示我已退出并且死亡,最后被后面的release_task回收,将不会再有进程等待我。否则返回值与传入的信号值相同,子进程变成EXIT_ZOMBIE,表示已退出但还没死。不管有没有处理SIGCHLD,do_notify_parent最后都会用__wake_up_parent来唤醒正在等待的父进程。
可见子进程在结束前不一定都需要经过一个EXIT_ZOMBIE过程。如果父进程调用了waitpid等待子进程,则会显示处理它发来的SIGCHILD信号,子进程结束时会自我清理(在do_exit中自己用release_task清理);如果父进程没有调用waitpid等待子进程,则不会处理SIGCHLD信号,子进程不会马上被清理,而是变成EXIT_ZOMBIE状态,成为著名的僵尸进程。还有一种特殊情形,如果子进程退出时父进程恰好正在睡眠(sleep),导致没来得急处理SIGCHLD,子进程也会成为僵尸,只要父进程在醒来后能调用waitpid,也能清理僵尸子进程,因为wait系统调用内部有清理僵尸子进程的代码。因此,如果父进程一直没有调用waitpid,那么僵尸子进程就只能等到父进程退出时被init接管了。init进程会负责清理这些僵尸进程(init肯定会调用wait)。
我们可以写个简单的程序来验证,父进程创建10个子进程,子进程sleep一段时间后退出。第一种情况,父进程只对1~9号子进程调用waitpid(),1~9号子进程都正常结束,而在父进程结束前,pids[0]为EXIT_ZOMBIE。第二种情况,父进程创建10个子进程后,sleep()一段时间,在这段时间内_exit()的子进程都成为EXIT_ZOMBIE。父进程sleep()结束后,依次调用waitpid(),子进程马上变为EXIT_DEAD被清理。
为了更好地理解怎么清理僵尸进程,我们简要地分析一下wait系统调用。wait族的系统调用如waitpid,wait4等,最后都会进入./linux/kernel/exit.c:do_wait()内核例程,而后函数链为do_wait()--->do_wait_thread()--->wait_consider_task(),在这里,如果子进程在exit_notify中设置的tsk->exit_state为EXIT_DEAD,就返回0,即wait系统调用返回,说明子进程不是僵尸进程,会自己用release_task进行回收。如果它的exit_state是EXIT_ZOMBIE,进入wait_task_zombie()。在这里使用xchg尝试把它的exit_state设置为EXIT_DEAD,可见父进程的wait4调用会把子进程由EXIT_ZOMBIE设置为EXIT_DEAD。最后wait_task_zombie()在末尾调用release_task()清理这个僵尸进程。
(5)设置销毁标志并调度新的进程。在do_exit的最后,用exit_io_context清除IO上下文、preempt_disable禁用抢占,设置进程状态为TASK_DEAD,然后调用./linux/kernel/sched.c:schedule()来选择一个将要执行的新进程。注意进程在退出并回收之后,其位于调度器的进程列表中的进程描述符(PCB)并没有立即释放,必须在设置task_struct的state为TASK_DEAD之后,由schedule()中的finish_task_switch()--->put_task_struct()把它的PCB重新放回到free list(可用列表)中,这时PCB才算释放,然后切换到新的进程。