GUI系统之SurfaceFlinger(3)Android中的本地窗口FramebufferNativewindow
1.1 Android中的本地窗口
在OpenGL的学习过程中,我们不断提及“本地窗口”(NativeWindow)这一概念。那么对于Android系统来说,它是如何将OpenGL ES本地化的呢,或者说,它提供了什么样的本地窗口?
根据整个Android系统的GUI设计理念,我们不难猜想到至少需要两种本地窗口:
Ø 面向管理者(SurfaceFlinger)
既然SurfaceFlinger扮演了系统中所有UI界面的管理者,那么它无可厚非地需要直接或间接地持有“本地窗口”。从前一小节我们已经知道,这个窗口就是FramebufferNativeWindow
Ø 面向应用程序
我们先给出答案,这类窗口是SurfaceTextureClient
有不少读者可能会觉得困惑,为什么需要两种窗口,同一个系统不是应该只有一种窗口吗?比如这样子:

图 11‑4理想的窗口系统
这个图中,由Window来管理Framebuffer。我们打个比方来说,OpenGL就像是一台通用的打印机一样,只要输入正确的指令,它就能按照要求输出结果;而Window则是“纸”,它是用来承载OpenGL的输出结果的。OpenGL并不介意Window是A4纸或者是A6,甚至是塑料纸也没有关系,对它来说都只是“本地窗口”。
理解了这个图后,我们再来思考下,这样的模型是否能符合Android的要求?假如整个系统仅有一个需要显示UI的程序,我们有理由相信它是可以胜任的。但是如果有N个UI程序的情况呢?Framebuffer显然只有一个,不可能让各个应用程序自己单独管理。
这样子问题就来了,该如何改进呢?下面这个方法如何?

图 11‑5 改进的窗口系统
在这个改进的窗口系统中,我们有了两类本地窗口,即Window-1和Window-2。第一种窗口是能直接显示在终端屏幕上的——它使用了帧缓冲区,而后一种Window实际上是从内存缓冲区分配的空间。当系统中存在多个应用程序时,这能保证它们都可以获得一个“本地窗口”,并且这些窗口最终也能显示到屏幕上——SurfaceFlinger会收集所有程序的显示需求,对它们做统一的图像混合操作(有点类似于AudioFlinger),然后输出到自己的Window-1上。
当然,这个改进的窗口系统有一个前提,即应用程序与SurfaceFlinger都是基于OpenGL ES来实现的。有没有其它选择呢?答案是肯定的,比如应用程序端完全可以采用Skia等第三方的图形库,只要保持它们与SurfaceFlinger间的“协议”不变就可以了,如下所示:

图 11‑6 另一种改进的窗口系统
理论上来说,采用哪一种方式都是可行的。不过对于开发人员,特别是没有OpenGLES项目经验的人而言,前一种系统的门槛相对较高。事实上,Android系统同时提供了这两种实现来供上层选择。正常情况下我们按照SDK向导生成的apk应用,就属于后面的情况;而对于希望使用OpenGLES来完成复杂的界面渲染的应用开发者,也可以使用GLSurfaceView来达到目标。
在接下来的源码分析中,我们将对上面所提出的假设做进一步验证。
1.1.1 FramebufferNativeWindow
先把EGL创建一个Window Surface的函数原型列出如下:
EGLSurface eglCreateWindowSurface( EGLDisplay dpy, EGLConfig config,
NativeWindowType window, const EGLint *attrib_list);
显然不论是哪一种本地窗口,它都必须要与NativeWindowType保持一致,否则就无法正常使用EGL了。先从数据类型的定义来看下这个window参数有什么特别之处:
/*frameworks/native/opengl/include/egl/Eglplatform.h*/
typedef EGLNativeWindowType NativeWindowType;//注意这两种类型其实是一样的
…
#if defined(_WIN32) || defined(__VC32__) &&!defined(__CYGWIN__) && !defined(__SCITECH_SNAP__)
/* Win32 和WinCE系统下的定义 */
…
typedef HWND EGLNativeWindowType;
#elif defined(__WINSCW__) || defined(__SYMBIAN32__) /* Symbian系统*/
…
typedef void * EGLNativeWindowType;
#elif defined(__ANDROID__) || defined(ANDROID) /* Android系统 */
struct ANativeWindow;
…
typedef struct ANativeWindow* EGLNativeWindowType;
…
#elif defined(__unix__) /* Unix系统*/
…
typedef Window EGLNativeWindowType;
#else
#error "Platform notrecognized"
#endif
我们以下表来概括在不同的操作系统平台下EGLNativeWindowType所对应的具体数据类型:
表格 11‑2 不同平台下的EGLNativeWindowType
| 操作系统 |
数据类型 |
| Win32, WinCE |
HWND,即句柄 |
| Symbian |
Void* |
| Android |
ANativeWindow* |
| Unix |
Window |
| 其它 |
暂时不支持 |
由于OpenGL ES并不是只针对某一个操作系统平台设计的,它在很多地方都要考虑兼容性和可移植性,这个EGLNativeWindowType就是其中一个例子。它在不同的系统中对应的是不一样的数据类型,比如Android中就指的是ANativeWindow指针。
ANativeWindow的定义在Window.h中:
/*system/core/include/system/Window.h*/
struct ANativeWindow
{…
const uint32_t flags; //与Surface或updater有关的属性
const int minSwapInterval;//所支持的最小交换间隔时间
const int maxSwapInterval;//所支持的最大交换间隔时间
const float xdpi; //水平方向的密度,以dpi为单位
const float ydpi;//垂直方向的密度,以dpi为单位
intptr_t oem[4];//为OEM定制驱动所保留的空间
int (*setSwapInterval)(struct ANativeWindow*window, int interval);
int (*dequeueBuffer)(struct ANativeWindow*window, struct ANativeWindowBuffer** buffer);
int (*lockBuffer)(struct ANativeWindow*window, struct ANativeWindowBuffer* buffer);
int (*queueBuffer)(struct ANativeWindow* window, struct ANativeWindowBuffer*buffer);
int (*query)(const struct ANativeWindow*window, int what, int* value);
int (*perform)(struct ANativeWindow* window,int operation, ... );
int (*cancelBuffer)(struct ANativeWindow*window, struct ANativeWindowBuffer* buffer);
void* reserved_proc[2];
};
我们在下表中详细解释这个类的成员函数。
表格 11‑3 ANativeWindow类成员函数解析
| Member Function |
Description |
| setSwapInterval |
设置交换间隔时间,后面我们会讲解swap的作用 |
| dequeueBuffer |
EGL通过这个接口来申请一个buffer。以前面我们所举的例子来说,两个本地窗口所提供的buffer分别来自于帧缓冲区和内存空间。单词“dequeue”的字面意思是“出队列”,这从侧面告诉我们,一个Window所包含的buffer很可能不只一份 |
| lockBuffer |
申请到的buffer并没有被锁定,这种情况下是不允许我们去修改其中的内容的。所以我们必须要先调用lockBuffer来获得一个锁 |
| queueBuffer |
当EGL对一块buffer渲染完成后,它调用这个接口来unlock和post buffer |
| query |
用于向本地窗口咨询相关信息 |
| perform |
用于执行本地窗口支持的各种操作,比如: NATIVE_WINDOW_SET_USAGE NATIVE_WINDOW_SET_CROP NATIVE_WINDOW_SET_BUFFER_COUNT NATIVE_WINDOW_SET_BUFFERS_TRANSFORM NATIVE_WINDOW_SET_BUFFERS_TIMESTAMP 等等 |
| cancelBuffer |
这个接口可以用来取消一个已经dequeued的buffer,要特别注意同步的问题 |
从上面对ANativeWindow的描述可以看出,它更像是一份“协议”,规定了一个本地窗口的形态和功能。这对于支持多种本地窗口的系统是必须的,因为只有这样子我们才能针对某种特定的平台窗口,来填充具体的实现。
这个小节中我们先来看下FramebufferNativeWindow是如何履行这份“协议”的。
FramebufferNativeWindow本身代码并不多,下面分别选取其构造函数及dequeue()两个函数来分析,其它部分的实现都是类似的,大家可以自行阅读。
(1) FramebufferNativeWindow构造函数
基于FramebufferNativeWindow的功能,可以大概推测出它的构造函数里应该至少完成如下的初始化操作:
Ø 加载GRALLOC_HARDWARE_MODULE_ID模块,详细流程我们在Gralloc小节已经解释过了
Ø 分别打开fb和gralloc设备。我们在Gralloc小节也已经分析过了,打开后的设备由全局变量fbDev和grDev管理
Ø 根据设备的属性来给FramebufferNativeWindow赋初值
Ø 根据FramebufferNativeWindow的实现来填充ANativeWindow中的“协议”
Ø 其它一些必要的初始化
下面从源码入手看下每个步骤具体是怎样实现的。
/*frameworks/native/libs/ui/FramebufferNativeWindow.cpp*/
FramebufferNativeWindow::FramebufferNativeWindow()
: BASE(), fbDev(0),grDev(0), mUpdateOnDemand(false)
{
hw_module_t const* module;
if (hw_get_module(GRALLOC_HARDWARE_MODULE_ID, &module) == 0) {…
int err;
int i;
err = framebuffer_open(module, &fbDev);
err = gralloc_open(module, &grDev);
/*上面这部分我们在前几个小节已经分析过了,不清楚的可以回头看下*/
…
mNumBuffers = NUM_FRAME_BUFFERS; //buffer个数,目前为2
mNumFreeBuffers =NUM_FRAME_BUFFERS; //可用的buffer个数,初始时所有buffer可用
mBufferHead =mNumBuffers-1;
…
for (i = 0; i <mNumBuffers; i++) //给每个buffer初始化
{
buffers[i] = new NativeBuffer(fbDev->width,fbDev->height, fbDev->format, GRALLOC_USAGE_HW_FB);
}// NativeBuffer是什么?
for (i = 0; i <mNumBuffers; i++) //给每个buffer分配空间
{
err =grDev->alloc(grDev, fbDev->width, fbDev->height, fbDev->format,
GRALLOC_USAGE_HW_FB, &buffers[i]->handle,&buffers[i]->stride);
…
}
/*为本地窗口赋属性值*/
const_cast<uint32_t&>(ANativeWindow::flags) = fbDev->flags;
const_cast<float&>(ANativeWindow::xdpi)= fbDev->xdpi;
const_cast<float&>(ANativeWindow::ydpi) = fbDev->ydpi;
const_cast<int&>(ANativeWindow::minSwapInterval) =fbDev->minSwapInterval;
const_cast<int&>(ANativeWindow::maxSwapInterval) =fbDev->maxSwapInterval;
} else {
ALOGE("Couldn'tget gralloc module");
}
/*以下履行窗口“协议”*/
ANativeWindow::setSwapInterval = setSwapInterval;
ANativeWindow::dequeueBuffer = dequeueBuffer;
ANativeWindow::lockBuffer= lockBuffer;
ANativeWindow::queueBuffer= queueBuffer;
ANativeWindow::query =query;
ANativeWindow::perform =perform;
}
这个函数逻辑上很简单,开头一部分我们已经分析过了,就不再赘述。需要注意的是FramebufferNativeWindow是如何分配buffer的,换句话说,后面的dequeue所获得的缓冲区是从何而来。
成员变量mNumBuffers代表了FramebufferNativeWindow所管理的buffer总数,NUM_FRAME_BUFFERS当前定义为2。有人可能会觉得奇怪,既然FramebufferNativeWindow对应的是真实的物理屏幕,那么为什么需要两个buffer呢?
假设我们需要绘制这样一个画面,包括两个三角形和三个圆形,最终结果如下图所示:

图 11‑7 希望在屏幕上显示的完整结果
先来看只有一个buffer的情况,这意味着我们是直接以屏幕为画板来实时做画的——我们画什么,屏幕上就显示什么。以绘制上图中的每一个三角形或圆形都需要0.5秒为例,那么总计耗时应该是0.5*5=2.5秒。换句话说,用户在不同时间点所看到的屏幕是这样子的:
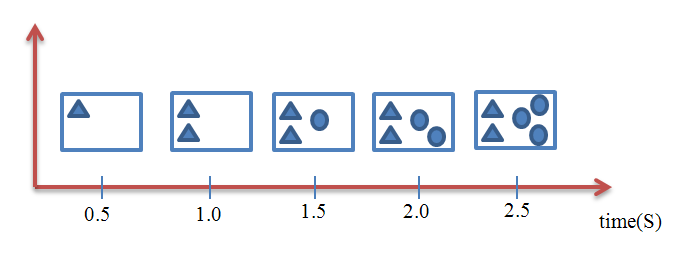
图 11‑8 只有一个buffer的情况
对于用户来说,他将看到一个不断刷新的画面。通俗来讲,就是画面很“卡”。对于图像刷新很频繁的情况,比如游戏场景,用户的体验就会更差。那么有什么解决的办法呢?我们知道,出现这种现象的原因就是程序直接以屏幕为绘图板,把还没有准备就绪的图像直接呈现给了用户。换句话说,如果可以等待整幅图绘制完成以后再刷新到屏幕上,那么对于用户来说,他在任何时候看到的都是正确而完整的图像,问题也就解决了。下图解释了当采用两个缓冲区时的情况:
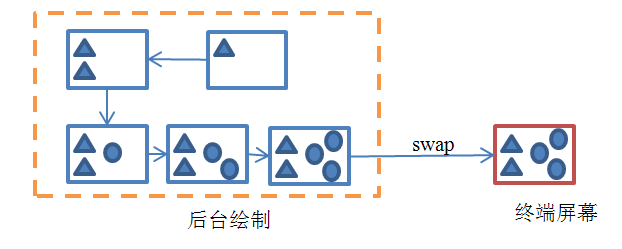
图 11‑9 采用两个缓冲区的情况
上图中所述的就是通常所称的“双缓冲”(Double-Buffering)技术。除此以外,其实还有三缓冲(TripleBuffering)、四缓冲(Quad Buffering)等等,我们将它们统称为“多缓冲”(MultipleBuffering)机制。
理解了为什么需要双缓冲以后,我们再回过头来看FramebufferNativeWindow的构造函数。接下来就要解决另一个问题,即两个缓冲区空间是从哪里分配的?根据前几个小节的知识,应该是要向HAL层的Gralloc申请。两个缓冲区以全局变量buffers[NUM_FRAME_BUFFERS]来记录,每个数据元素是一个NativeBuffer,这个类定义如下:
class NativeBuffer : public ANativeObjectBase< ANativeWindowBuffer,
NativeBuffer,LightRefBase<NativeBuffer> >
{…
所以这个“本地缓冲区”继承了ANativeWindowBuffer的特性,后者的定义在/system/core/include/system/Window.h中:
typedef struct ANativeWindowBuffer
{…
int width; //宽
int height;//高
…
buffer_handle_t handle;/*代表内存块的句柄,比如ashmem机制。
可以参考本书的共享内存章节*/
…
} ANativeWindowBuffer_t;
第一个for循环里先给各buffer创建相应的实例(new NativeBuffer),其中的属性值都来源于fbDev,比如宽、高、格式等等。紧随其后的就是调用Gralloc设备的alloc()方法:
err = grDev->alloc(grDev, fbDev->width,fbDev->height, fbDev->format,
GRALLOC_USAGE_HW_FB, &buffers[i]->handle, &buffers[i]->stride);
注意第5个参数,它代表所要申请的缓冲区的用途,定义在hardware/libhardware/include/hardware/Gralloc.h中,目前已经支持几十种,比如:
Ø GRALLOC_USAGE_HW_TEXTURE
缓冲区将用于OpenGL ES Texture
Ø GRALLOC_USAGE_HW_RENDER
缓冲区将用于OpenGL ES的渲染
Ø GRALLOC_USAGE_HW_2D
缓冲区会提供给2D 硬件图形设备
Ø GRALLOC_USAGE_HW_COMPOSER
缓冲区用于HWComposer HAL模块
Ø GRALLOC_USAGE_HW_FB
缓冲区用于framebuffer设备
Ø GRALLOC_USAGE_HW_VIDEO_ENCODER
缓冲区用于硬件视频编码器
等等。。。
这里是要用于在终端屏幕上显示的,所以申请的usage类型是GRALLOC_USAGE_HW_FB,对应的Gralloc中的实现是[email protected];假如是其它用途的申请,则对应[email protected]。不过,如果底层只允许一个buffer(不支持page-flipping的情况),那么gralloc_alloc_framebuffer也同样可能只返回一个ashmem中申请的“内存空间”,真正的“帧缓冲区”要在post时才会被用到。
另外,当前可用(free)的buffer数量由mNumFreeBuffers管理,这个变量的初始值也是NUM_FRAME_BUFFERS,即总共有2个可用缓冲区。在程序后续的运行过程中,始终由mBufferHead来指向下一个将被申请的buffer(注意,不是下一个可用buffer)。也就是说每当用户向FramebufferNativeWindow申请一个buffer时(dequeueBuffer),这个mBufferHead就会增加1;一旦它的值超过NUM_FRAME_BUFFERS,则还会变成0,如此就实现了循环管理,后面dequeueBuffer时我们再详细解释。
一个本地窗口包含了很多属性值,比如各种标志(flags)、横纵坐标的密度值等等。这些数值都可以从fb设备上取到,我们需要将它赋予刚生成的FramebufferNativeWindow实例。
最后,就是履行ANativeWindow的协议了。FramebufferNativeWindow会将其成员函数填充到ANativeWindow中的函数指针中,比如:
ANativeWindow::setSwapInterval = setSwapInterval;
ANativeWindow::dequeueBuffer = dequeueBuffer;
这样子OpenGL ES才能通过一个ANativeWindow来正确地与本地窗口建立连接,下面我们就详细分析下其中的dequeueBuffer。
(2)dequeueBuffer
这个函数很短,只有二十几行,不过是FramebufferNativeWindow中的核心。OpenGL ES就是通过它来分配一个用于渲染的缓冲区的,与之相对应的是queueBuffer。
int FramebufferNativeWindow::dequeueBuffer(ANativeWindow* window,ANativeWindowBuffer** buffer)
{
FramebufferNativeWindow*self = getSelf(window); /*Step1*/
Mutex::Autolock_l(self->mutex); /*Step2*/
…
/*Step3. 计算mBufferHead */
int index =self->mBufferHead++;
if (self->mBufferHead>= self->mNumBuffers)
self->mBufferHead =0;
/*Step4. 当前没有可用缓冲区*/
while (!self->mNumFreeBuffers){
self->mCondition.wait(self->mutex);
}
/*Step5. 有人释放了缓冲区*/
self->mNumFreeBuffers--;
self->mCurrentBufferIndex = index;
*buffer =self->buffers[index].get();
return 0;
}
Step1@ FramebufferNativeWindow::dequeueBuffer, 这里先将入参中ANativeWindow 类型的变量window强制转化为FramebufferNativeWindow。因为前者是后者的父类,所以这样的转化当然是有效的。不过细心的读者可能会发现,为什么函数入参中还要特别传入一个ANativeWindow对象的内存地址,直接使用FramebufferNativeWindow的this指针不行吗?这个问题我还没有确定真正的原因是什么,一个猜测是为了兼容各种平台的需求。大家应该注意到了ANativeWindow是一个Struct数据类型,在C语言中Struct是没有成员函数的,所以我们通常是用函数指针的形式来模拟一个成员函数,比如这个dequeueBuffer在ANativeWindow的定义就是一个函数指针。而且我们没有办法确定最终填充到ANativeWindow中函数指针的实现是否有this指针,所以在参数中带入一个window变量就是必要的了。
Step2@ FramebufferNativeWindow::dequeueBuffer,获得一个Mutex锁。因为接下来的操作涉及到互斥区,自然需要有一个保护措施。这里采用的是Autolock,意味着dequeueBuffer函数结束后会自动释放Mutex。
Step3@ FramebufferNativeWindow::dequeueBuffer,前面我们介绍过mBufferHead变量,这里来看下对它的实际使用。首先index得到的是mBufferHead所代表的当前位置,然后mBufferHead增加1。由于我们是循环利用两个缓冲区的,所以如果这个变量的值超过mNumBuffers,那么就需要把它置0。也就是说在这个场景下mBufferHead的值永远只能是0或者1。
Step4@ FramebufferNativeWindow::dequeueBuffer,mBufferHead并不代表它所指向的缓冲区是可用的。假如当前的mNumFreeBuffers表明已经没有多余的缓冲区空间,那么我们就需要等待有人释放buffer。这里使用到了Condition这一同步机制,如果有不清楚的请参考本书进程章节的详细描述。可以肯定的是这里调用了mCondition.wait,那么必然有其它地方要唤醒它——具体的就是在queueBuffer()中,大家可以自己验证下是否如此。
Step5@ FramebufferNativeWindow::dequeueBuffer,一旦成功获得buffer后,要把可用的buffer计数减1(mNumFreeBuffers--),因为mBufferHead前面已经自增过了,这里就不用再特别处理。
这样子我们就完成了对Android系统中本地窗口FramebufferNativeWindow的分析,接下来就讲解另一个重要的Native Window。