TI C674x和OMAP-L1x DSP系统框架以及编程优化指南
本文介绍了TI C674x和OMAP-L1x DSP的基本系统框图,从软件架构(如ARM核上运行的Linux、WinCE和Vxworks操作系统,底层DSP端的DSP/BIOS,上层的codec engine framework)到DSP芯片内的存储配置,功能单元、数据通路、交叉通道、寻址模式、汇编格式、指令加载和执行、常见的指令等。然后介绍了C674x DSP上的编程规范,需要注意的关于延迟槽(delay slot)和C编程的寄存器参数传递和参数返回规则以及整个的开发流程。最好是针对C674x DSP的常见的优化技巧,包括循环展开,如何优化软件流水,采用SPLOOP(Software Pipelined Loop (SPLOOP) Buffer)来优化循环的迭代间隔以及采用数据打包技术等。
TI C674x和OMAP-L1x SOC基本介绍
功耗7mw~490mw,处理能力最高到2400MIPS(MMACs),在OMAP-L1x处理器的ARM和可以运行包括Linux,WinCE和Vxworks等操作系统。
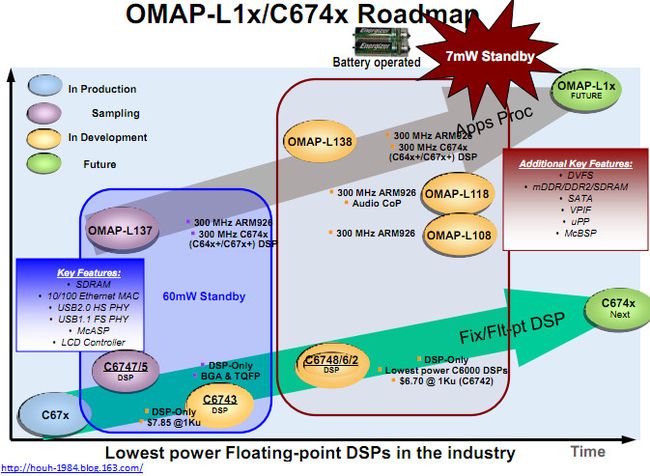
图1. TI-C674x DSP和OMAP-L1x SOC的演进图

图2. OMAP-L137的系统框图
软件框架:
OMAP-L137有ARM核可以运行OS,因而左侧是一个典型的ARM体系框架,底层的各种驱动,如CMEM/USB/EMAC/McASP/MMC/SPI/I2C/UART等,接着是Linux kernel API,上层会运行Codec Engine已实现与DSP端的通信,DSP端则运行信号处理算法,其工具链为CCS IDE开发环境和CGTools编译器,封装有DSP/BIOS实时操作系统,上层也是codec engine框架来实现算法封装。对于单DSP的软件框架,则是以上架构的融合,底层的驱动,中间的DSP/BIOS,上层的Codec engine。

图3. OMAP-L137的软件系统框图
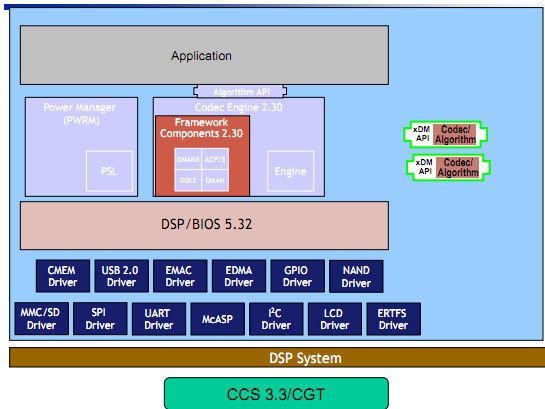
图4. C6747/C6748的软件框架
C674x DSP简介
C674x高性能DSP采用VLIW(Advanced Very Long Instruction Word),包含有64个32-bit通用寄存器,8个功能单元,2个定点ALUs,4个定点和浮点混合ALUs,2个定点和浮点乘法器,每个周期最多可以运行8个32-bit的指令,数据的加载位宽为32或者64-bit每个周期。其L1/L2存储包括直接映射的32KB的L1P程序cache(cache line 16Bytes),32KB的2-way L1D数据 Cache (cache line 64Bytes),L1D配置为Read allocate, write back,256KB可配置的L2 cache(cache line 128Bytes),L2 cache为4-way,LRU的替换法则,Read/write allocate, write back;最多可配置成64KB的L2 Cache。16个不同通道的EDMA控制器。4个memory bank,需要注意的是从同周期内从同一个memory bank读取数据是要stall的。
图5. C674x DSP的片内架构图
C674x的功能单元和数据通路
2个数据通路,8个功能单元,2个寄存器堆,每个堆有32个32-bit寄存器,2个交叉通路,浮点的40-bit的ALU,可以完成比特统计和归一化操作, 乘法器能完成定点和浮点操作。

图6. 数据位宽和数据通路示意图
增强的Advanced VLIW (VelociTI?)
指令加载包固定为8条32-bit指令,指令执行包包含1~8条指令。即指令加载包长度和指令执行包可以不一致,允许指令执行的跨越加载包,也允许单一加载包包含若干个周期内完成执行的指令。指令间是否并行将在编译和汇编阶段决定,这种改进将大大降低代码大小,减少程序的加载次数,进而降低功耗。
DSP指令支持的数据类型
32-bit, 40-bit, 64-bit 整型, 32-bit单精度的浮点float,64-bit双精度浮点(double)以及打包的8-bit或者16-bit整型,如 4个8-bit组成32-bit寄存器,2个16-bit的构成一个32-bit寄存器以及4个16-bit的构成两个32-bit寄存器。一般采用寄存器对来保持40bit或者64-bit的数值,如A1:A0/B3:B2等。
汇编指令格式

图7. 汇编指令格式
标记Label 并行指令符号|| 条件执行寄存器[A0] 功能单元 指令操作数 ;注释
寻址模式
间接寻址:
*R表明R寄存器内是内存地址;*R++(d) 表明寻址后进行地址更新,*++R(d) 表明寻址前进行地址更新,*+R(d)表明用更新的地址寻址但并不更新地址指针。
循环寻址:用于寻址在一定地址范围内的数据,用AMR寄存器来控制,只有A4~A7以及B4~B7寄存器可以用于循环寻址。
常见指令
ADDA以及SUBA用于地址计算,ADDAB(字节), ADDAH(半字) , ADDAW(字), ADDAD(双字),SUBAB, SUBAH, SUBAW,但是没有SUBAD。
跳转指令:
[A0] B .S1 LOOP
BDEC (.unit) src, dst ;带减的跳转,即更新计数器
CALLP (.unit) Label, A3/B3;函数调用
Move指令用于加载常量数据:mvk,mvkl,mvkh
整数算术运算:
ADD .L1 A3, A7, A7 ; A3+A7->A7
ADDU ; unsigned (32-bit or 40-bit)
SADD ; with saturation
ABS .L1 SRC, DST ; 32-bit or 40-bit
ADDK .S1 K, SRC ; SRC += K (signed 16-bit)
SUB ; Subtraction
SUBU ; unsigned (32-bit or 40-bit)
SSUB ; with saturation
ADDSUB src1, src2, dst_o:dst_e
SADDSUB src1, src2, dst_o:dst_e ; w/ saturation
dst_o = src1 + src2
dst_e = src1 – src2
整数乘法运算
MPY, MPYH ; signed 16-bit, low and high
MPYSU, MPYUS; 16-bit, mixed signed and unsigned
MPYU, MPYHU, MPYHUS, MPYHSU ; Higher half, unisgned
MPYHL, MPYHLU, MPYHULS, MPYHSLU ; High and Low
MPYLH, MPYLHU, MPYLSHU, MPYLUHS ; Low and High
MPYI, MPYID ; 32-bit, lower 32-bit results or all
MPYIH, MPYHI, MPYIL, MPYLI; 32-bit and 16-bit
MPYIHR, MPYHIR, MPYILR, MPYLIR; w/shift and Round
MPY32, MPY32U, MP32SU, MPY32US, MPYLIR; 32-bit faster Plus the versions that have saturation.
比较指令
CMPEQ ; Equal
CMPLT, CMPLTU ; Les than
CMPGT, CMPGTU ; Great than
打包的并行指令
ADD2 ; Packed 16-bit
SADD2 ; with saturation
SADDU2 ; with saturation
SADDU4 ; with saturation
SADDSU2 ; signed with unsigned, with saturation
SADDUS2 ; unsigned with signed, with saturation
ADD4 ; Packed 16-bit
ABS2 ; Packed 16-bit
ADDSUB2 src1, src2, dst_o:dst_e ; packed
SADDSUB2 src1, src2, dst_o:dst_e ;
SHR2 ; Shift right, arithmetic
MPYU4 ; Multiplication, unsigned, four pairs
比特位域操作CLR和SET、EXT
CLR (.unit) src2, csta, cstb, dst 或者CLR (.unit) src2, src1, dst
SET (.unit) src2, csta, cstb, dst 或者SET (.unit) src2, src1, dst
EXT (.unit) src2, csta, cstb, dst 或者EXT (.unit) src2, src1, dst
DEAL 以及 SHFL用于比特的交织和解交织
复数乘法指令
CMPY src1, src2, dst_o:dst_e
CMPYR src1, src2, dst_o:dst_e ;带饱和和舍入运算
点积运算DOTP2
浮点指令
ABSSP
ADDSP
SUBSP
RCPSP ; Reciprocal
ABSDP
ADDDP
SUBDP
RCPDP ; Reciprocal
SAT
SPINT
SPDP
SPTRUNC
DPINT
DPSP
DPTRUNC
指令加载包
P比特表明是否与下一条指令并行,所有的并行指令在一起组成一个执行指令包,当跳转到一个执行指令包的中间时,所有的低地址的指令将会被忽略掉,即不执行。

图8. 指令加载包实例(Fetch packet)
紧凑的16-bit指令格式
编译器来决定是否使用紧凑模式,紧凑模式的限制包括,没有专门的预测位域,3-bit的寄存器地址,非常有限的3个操作数的指令,是32-bit指令的一个子集。
流水线与延时槽(delay slot)
流水线包括指令加载Fetch,指令译码以及指令执行3个阶段。
延时槽是指你在读取结果寄存器时需要等待的周期数,如对于单周期的指令,该等待时间为0个周期。常见的多周期的指令包括数据加载LDB/LDH/LDW/LDDW/LDNDW等、乘法MPYSPDP MPYDP、点积、跳转指令等。
指令并行的限制
- 相同的功能单元不能再同一个周期内写入相同的寄存器;.M单元只有32-bit位宽的写端口
- 交叉通路的限制:在一个执行程序包内,每个数据通路两个功能单元可以访问从另一个寄存器堆的相同的操作数。当从另外一侧读取一个刚刚更新的寄存器时会有一个周期的延迟,即交叉通道的延迟。
- 寄存器的读写:每个周期不能同时写入一个目标寄存器,每个周期对同一个寄存器的读取不能超过4次;
- 数据加载和存储:一个周期内的两个加载和存储不能使用相同一侧的源和目标寄存器组,非对齐的数据存储和加载每个周期只能一次;
- Others
函数调用约束规范
返回值保存在A4 (或者A5:A4),返回地址在B3,传入参数列表 A4, B4, A6, B6, A8, B8, A10, B10, A12, B12(如果参数需要64-bit或者40-bit精度的话将采用寄存器对),其他的参数保存到堆栈,被调用函数内部可以不保存的使用如下寄存器: A0 – A9, B0 – B9, A16 – A31, B16 – B31。
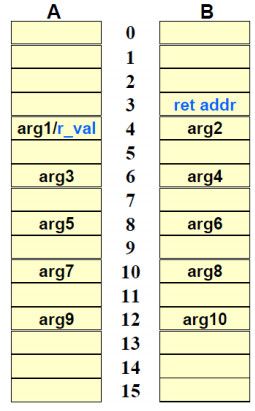
图9. 函数参数和返回寄存器对应关系
C674x的编程流程
首先是规划好算法,由于C674x支持定点和浮点操作,因而非常方便验证算法性能,然后开发C/C++的代码并用CCS自带的profiler工具进行性能评估,接下来是针对hotspot进行的refine,即考虑编译器的优化选项,重新组织代码以及intrinsic来优化代码。如果C代码还是不能满足性能,那么还需要线性汇编以及并行的汇编等。
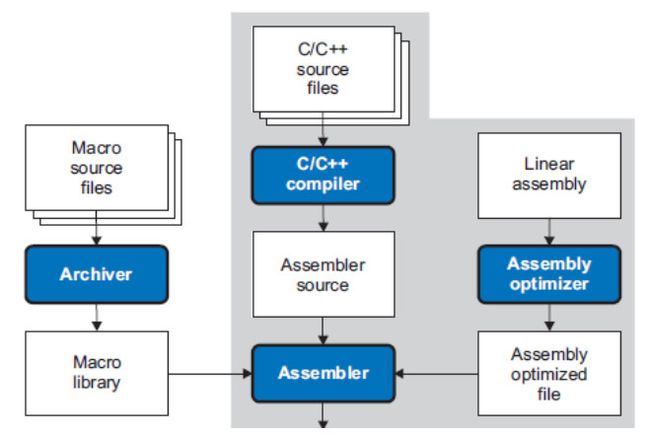
图10. 代码生成流程
Linker生成的各个段定义
.text code代码
.data 初始化数据
.bss 为没有初始化的数据预留空间
.usect 创建未初始化的段
.sect 创建初始化的段
.args 命令行参数段
.sysmem 系统堆段
.const 常量数据段
汇编指示字
.asg "A4", RETVAL
.define "string", SYM ; similar to .asg
.eval expression, SYM ; doing arithmetic
.unasg
.undefine
.copy "filename"
.include "filename"
.byte 32
.half
.int 1, 2, 3
.long
.float
.double
条件汇编
.break
.if (expression)
.else
.elseif (expression)
.endif
.loop
.endloop
.break
汇编中的宏定义
macname .macro [param1, param2, …]
.endm
.mexit ; goto .endm
.mlib filename ; Macro libaray
C674x的优化指南
使用CCS Profiler确定瓶颈,然后采用编译器选项优化、加入intrinsic以及使用线性汇编优化等。
-
Loop unroll,使用#pragma关键字指定优化的循环信息和循环展开信息
#pragma UNROLL(4) 指定循环展开4次,编译器自己会处理循环次数不是4的整数倍的情况,但是最好指明循环次数是4的整数倍,即用MUST_ITERATE
#pragma MUST_ITERATE(min_trip_counter, max_trip_counter, trip_counter_factor)
在线性汇编里采用.trip min_trip_counter, max_trip_counter, trip_counter_factor
-
优化软件流水的迭代间隔
Software pipeline软件流水是一种排序循环内的指令以能在一次执行中并行处理多个迭代的技术,能更为有效的使用资源,尤其对于VLIW的具有多功能单元的架构,通过挖掘多次迭代间的并行性,减少迭代中的因为数据相关导致的依赖,一般都是针对最内层循环进行的优化。软件流水阶段分为进入循环核前的prolog,循环核loop kernel,循环核结束后的epilog几个过程。
C674x的DSP的软件流水还有一个循环缓冲区,即Software Pipelined Loop (SPLOOP) Buffer。它是一个能存储若干条SPLOOP指令的片内存储空间,最多达14个执行包,即最多112条指令。由于是片内的存储空间,因而不会发生cache miss的情况。一般用SPLOOP(知道循环最小运行次数,但不知循环体是否超过4个周期,因为ILC加载和使用需要4个周期的间隔), SPLOOPD(知道循环最小运行次数,也知道循环体超过4个周期), SPLOOPW(不知道循环次数的任何信息)表明buffer的起始,SPKERNEL 和 SPKERNELR表明结束,而 SPMASK and SPMASKR用来区分是SPLOOP内的存储还是在普通memory内的指令。下面是SPLOOP的循环汇编结构
<initialization code>
SPLOOP or SPLOOPD
<inner loop code>
SPKERNEL
SPLOOP的硬件支持包括如下缓冲区和寄存器
Loop buffer
Loop buffer count register (LBC) ——执行SPLOOP, SPLOOPD, on SPLOOPW时清零,每个运行周期后+1,用户不可见;
Inner loop count register (ILC) – 用于循环计数的专用寄存器 ,SPLOOP 和SPLOOPD使用的向下计数器,递减;加载ILC和使用它需要4个周期的延迟;
Reload inner loop count register (RILC) – 支持循环嵌套
Task state register (TSR)
Interrupt task state register (ITSR)
NMI/Exception task state register (NTSR)
SPLOOP的一些限制:每次迭代支持最多的长度为48个周期的动态运行长度,最多14个周期的迭代间隔,SPLOOP内不能有跳转和CALL子程序。
- 多使用打包指令,尤其是对于操作数是8-bit或者16-bit的时候,考虑如addsub2、dotpu4、mpy2、subasbs4等指令。
http://houh-1984.blog.163.com/
本文介绍了TI C674x和OMAP-L1x DSP的基本系统框图,从软件架构(如ARM核上运行的Linux、WinCE和Vxworks操作系统,底层DSP端的DSP/BIOS,上层的codec engine framework)到DSP芯片内的存储配置,功能单元、数据通路、交叉通道、寻址模式、汇编格式、指令加载和执行、常见的指令等。然后介绍了C674x DSP上的编程规范,需要注意的关于延迟槽(delay slot)和C编程的寄存器参数传递和参数返回规则以及整个的开发流程。最好是针对C674x DSP的常见的优化技巧,包括循环展开,如何优化软件流水,采用SPLOOP(Software Pipelined Loop (SPLOOP) Buffer)来优化循环的迭代间隔以及采用数据打包技术等。