在Solr4.10配置IKAnalyzer 同义词、扩展词库、停顿词详解
在Solr4.10配置IKAnalyzer同义词、扩展词库、停顿词详解
在配置IKAnalyzer 同义词,扩展词,停顿词时,出现了很麻烦的事情,搞了一段时间,因为现在直接从官网上下载下来的IKAnalyzer是能够直接的进行中文的分词,但是进行useSmart参数控制,及同义词,扩展词,停顿词的配置则需要对IKAnalyzer的jar包进行修改才可以使用。
IKAnalyzer的默认分词模式为细粒度分词,但有的时候我们想要却是智能分词,比如结合扩展词进行智能分词,我个人在实际环境中发现,不管启用智能分词,停止词和同义词都是起作用的,因此我目前的结论是启用智能分词只对扩展词起作用,其实这样做也是符合实际业务需要的。
我使用的IKAnalyzer的jar包是IK-Analyzer-4.7.1-0.0.1-SNAPSHOT.jar,对原来的官网的jar包进行了修改和补充。
如下图:

上面标出的都是进行修改过的,IKTokenizerFactory及IKTokenizerFactory111是新增的,还修改了一些其他的类,这里没有标注出来。
schema.xml中中文分词配置如下

IKAnalyzer.cfg.xml内容如下:

扩展词,停止词配置路径如下:

注意:是在classes路径下,有的说放到lib下和IK Analyzer的jar包放到一起也可以,但是那样的话我在进行中文分词的时候没有问题,但是配置停止词和扩展词的时候只对英文有效,如果是中文的话有问题,报MalformedInputException Input length = 1 这样的错误,原因是编码的问题,一直不知道怎么解决。
synonyms.txt在{solr_home}/{core}/conf文件下
我们在扩展词中加入NC63这个词汇之后,我们在分析页面输入NC63来看看不启用智能分词和启用智能分词的差别。
如下图,我们在索引和搜索输入框中都输入“NC63的补丁”,因为在对数据库里的数据进行索引的时候,使用的是IK默认的细粒度分词,因此“NC63的补丁”被分解成nc63、nc、63、的、补丁;而进行搜索的时候,启用了智能分词,因为我们在扩展词中添加了NC63,所以NC63作为整体的词进行搜索而没有被拆分开细粒度的词,“NC63的补丁”被分解成nc63、的、补丁。
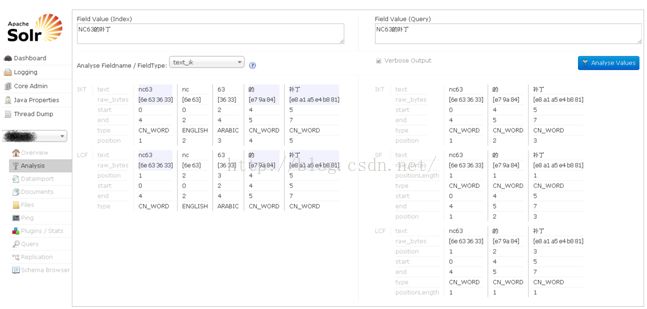
在实际业务中进行搜索的时候,有些单独的字可能没有实际的意义,因此也没有必要根据这些没有意义的字词到索引库里去匹配,比如上图中将“NC63的补丁”拆分之后的“的”字是没有实际搜索意义的,我们可以将这个“的”字加入到停止词库里将其过滤掉,我们再输入“NC63的补丁”后经过中文分词后的结果如下图。

大家可以参考
《在Solr4.10配置IKAnalyzer 同义词、扩展词库、停顿词详解》
《跟益达学Solr5之使用IK分词器》