HTTP协议 (三) 压缩
之前写过一个篇 【HTTP协议详解】 ,这次继续介绍HTTP协议中的压缩。
本文会使用Fiddler来查看HTTP request和Response, 如果不熟悉这个工具,可以先参考[Fiddler教程]
HTTP压缩是指: Web服务器和浏览器之间压缩传输的”文本内容“的方法。 HTTP采用通用的压缩算法,比如gzip来压缩HTML,Javascript, CSS文件。 能大大减少网络传输的数据量,提高了用户显示网页的速度。当然,同时会增加一点点服务器的开销。 本文从HTTP协议的角度,来理解HTTP压缩这个概念。
阅读目录
- HTTP内容编码和HTTP压缩的区别
- HTTP压缩的过程
- 实例:用Fiddler观察HTTP压缩
- 内容编码类型
- 压缩的好处
- gzip的缺点
- gzip是如何压缩的
- HTTP Response能压缩,HTTP Request也是可以压缩的
HTTP内容编码和HTTP压缩的区别
HTTP压缩,在HTTP协议中,其实是内容编码的一种。
在http协议中,可以对内容(也就是body部分)进行编码, 可以采用gzip这样的编码。 从而达到压缩的目的。 也可以使用其他的编码把内容搅乱或加密,以此来防止未授权的第三方看到文档的内容。
所以我们说HTTP压缩,其实就是HTTP内容编码的一种。 所以大家不要把HTTP压缩和HTTP内容编码两个概念混淆了。
HTTP压缩的过程
1. 浏览器发送Http request 给Web服务器, request 中有Accept-Encoding: gzip, deflate。 (告诉服务器, 浏览器支持gzip压缩)
2. Web服务器接到request后, 生成原始的Response, 其中有原始的Content-Type和Content-Length。
3. Web服务器通过Gzip,来对Response进行编码, 编码后header中有Content-Type和Content-Length(压缩后的大小), 并且增加了Content-Encoding:gzip. 然后把Response发送给浏览器。
4. 浏览器接到Response后,根据Content-Encoding:gzip来对Response 进行解码。 获取到原始response后, 然后显示出网页。
如下图:
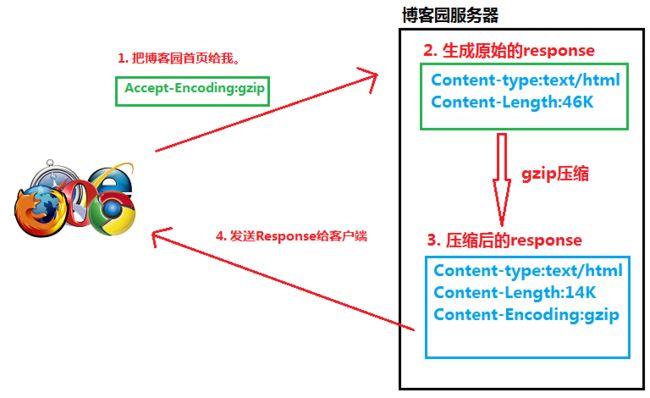
实例:Fiddler观察HTTP压缩
眼见为实, 我们看一个实际的例子, 我发现博客园就使用了gzip压缩。
使用Fiddler可以清楚地看到。


在Fiddler中,每次都要手动去decode. 太麻烦。 点击工具栏上的"Decode"按钮,就可以自动decode了。
内容编码类型
HTTP定义了一些标准的内容编码类型,并允许用扩展的形式添加更多的编码。
Content-Encoding header 就用这些标准化的代号来说明编码时使用的算法
Content-Encoding值
gzip 表明实体采用GNU zip编码
compress 表明实体采用Unix的文件压缩程序
deflate 表明实体是用zlib的格式压缩的
identity 表明没有对实体进行编码。当没有Content-Encoding header时, 就默认为这种情况
gzip, compress, 以及deflate编码都是无损压缩算法,用于减少传输报文的大小,不会导致信息损失。 其中gzip通常效率最高, 使用最为广泛。
压缩的好处
http压缩对纯文本可以压缩至原内容的40%, 从而节省了60%的数据传输。
实例: 博客园首页压缩前是:46124 bytes. 压缩后是:16368bytes. 只有原先的35%。 节省了65%的数据传输,从而大大提高了性能
有图为证。


Gzip的缺点
JPEG这类文件用gzip压缩的不够好。
Gzip是如何压缩的
简单来说, Gzip压缩是在一个文本文件中找出类似的字符串, 并临时替换他们,使整个文件变小。这种形式的压缩对Web来说非常适合, 因为HTML和CSS文件通常包含大量的重复的字符串,例如空格,标签。
HTTP Response能压缩,HTTP Request也是可以压缩的
浏览器是不会对Request压缩的。 但是 一些HTTP程序在发送Request时,会对其进行编码。 如下图。
