PowerHA 简介【转】
转自:http://www.ibm.com/developerworks/cn/aix/library/au-powerhaintro/
简介
随着业务需求日益增加,关键的应用程序必须一直可用,系统必须对故障有容忍能力。但是,这些有容错能力的系统的成本很高。因此,需要通过应用程序提供这些能力,同时这个应用程序还应该是经济有效的。
高可用性解决方案可以确保解决方案的任何组件的故障都不会导致用户无法使用应用程序及其数据。实现这一目标的方法是通过消除单一故障点消除或掩盖计划内和计划外停机。另外,保持应用程序高可用性并不需要特殊的硬件。PowerHA 不执行备份等管理任务、时间同步和任何与应用程序相关的配置。
图 1 是故障转移功能的示意图。当一个服务器停机时,另一个服务器接管。
图 1. 故障转移功能
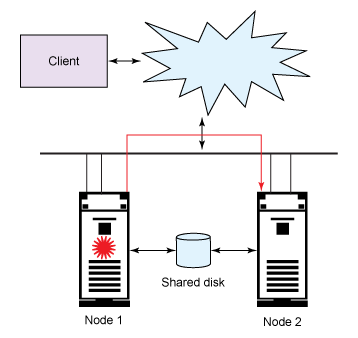
PowerHA 的概述
PowerHA 和 HACMP 这两个词可以互换使用。正如前面提到的,它会消除单一故障点 (SPOF)。下表列出可能存在的 SPOF:
| 集群对象 | 消除 SPOF 的方法 |
|---|---|
| 节点 | 使用多个节点 |
| 电源 | 使用多条电路或不间断电源 |
| 网络适配器 | 使用冗余的网络适配器 |
| 网络 | 使用多个网络连接节点 |
| TCP/IP 子系统 | 使用非 IP 网络连接相邻节点和客户机 |
| 磁盘适配器 | 使用冗余的磁盘适配器或多路径硬件 |
| 磁盘 | 使用多个磁盘以及镜像或 raid |
| 应用程序 | 添加用于接管的节点;配置应用程序监视器 |
| VIO 服务器 | 实现双 VIO 服务器 |
| 站点 | 添加额外站点 |
主要目标是,当两个服务器中的一个发生故障时,让另一个服务器接管。 PowerHA 集群技术通过提供冗余实现故障转移保护,同时通过并发/并行访问支持水平扩展。
PowerHA 术语
PowerHA 使用许多术语。它们可以分为拓扑组件和资源组件两类。
拓扑组件基本上是物理组件。它们包括:
- 节点:System p 服务器可以是单独的分区或 VIOS 客户机
- 网络:IP 网络和非 IP 网络
- 通信接口:令牌环网或以太网适配器
- 通信设备:RS232 或磁盘的心跳机制
资源组件是需要保持高可用性的逻辑实体。它们包括:
- 应用服务器:它涉及应用程序的启动/停止脚本。
- 服务 IP 地址:最终用户一般通过 IP 地址连接应用程序。这个 IP 地址映射到实际运行应用程序的节点。因为 IP 地址需要保持高可用性,所以它属于资源组。
- 文件系统:许多应用程序需要挂载文件系统。
- 卷组:许多应用程序需要高可用的卷组。
所有资源一起组成资源组实体。PowerHA 把资源组当作单一单元处理。它会保持资源组高可用性。资源组有与其相关联的策略。这些策略包括:
- 启动策略:这决定资源组应该激活哪个节点。
- 故障转移策略:当发生故障时,这决定故障转移目标节点。
- 故障恢复策略:这决定资源组是否执行故障恢复。
当发生故障时,PowerHA 寻找这些策略并执行相应的操作。
PowerHA 的子系统
图 2. PowerHA 的子系统
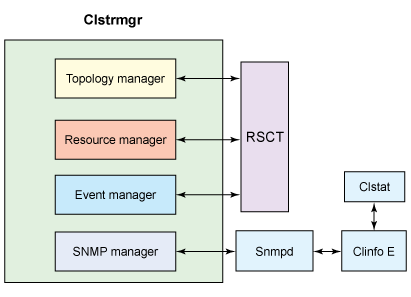
上图说明 PowerHA 由许多软件组件组成:
- 集群管理器 clstrmgr 是核心进程,它监视集群成员关系。集群管理器包含管理拓扑组件的拓扑管理器、管理资源组的资源管理器、通过 RMC 设施起作用的事件管理器和事件脚本以及对故障做出反应的 RSCT。
- clinfo 进程提供用于在集群管理器和应用程序之间进行通信的 API。clinfo 还提供远程监视功能,可以在集群状态发生变化时运行脚本。
- 在 PowerHA 5 中,clcomdES 使集群管理器能够以安全的方式进行通信,不需要使用 rsh 和 /.rhost 文件。
配置两节点集群
开始研究配置之前,先讨论一下 PowerHA 的连网和存储考虑事项。
连网
PowerHA 使用网络探测和诊断故障以及为客户机提供高可用性的应用程序访问能力。
节点之间的通信也要通过网络。PowerHA 直接探测三类故障:网络、NIC 和节点故障。它通过使用 RSCT 守护进程执行探测和诊断。RSCT 实际上探测跨所有网络发送的心跳数据包是否丢失并判断准确的丢失(网络、NIC 或节点故障)。
图 3 说明所有 NIC 传输并接收心跳数据包,这有助于判断故障。
图 3. 根据心跳数据包形成的集群
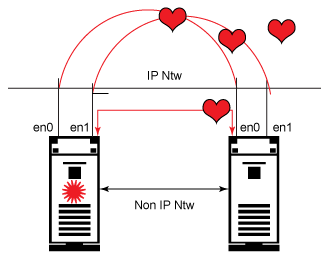
如果心跳数据包的传输停止了,那么两个节点都会认为对方停机了,因此都尝试让资源组上线。这会导致大规模的数据破坏。
为了避免此问题,PowerHA 使用两种网络:
- IP 网络:例如以太网、Ether channel 等
- 非 IP 网络:例如 RS232(为了确保即使在发生网络故障的情况下 PowerHA 也能够区分网络故障和节点故障,需要非 IP 网络)
IP 地址接管 (IPAT)
大多数应用程序都要求 IP 是高度可用的。为了确保这一点,我们把服务 IP 地址包含在资源组中。把服务 IP 地址从一个 NIC 转移到另一个上的过程称为 IP 地址接管。有两种实现 IPAT 的方法:
- 通过别名实现 IPAT:PowerHA 使用 AIX IP 别名特性把服务 IP 地址添加到 NIC 中
- 通过替换实现 IPAT:PowerHA 把接口 IP 地址替换为服务 IP
存储
存储设备大致分为两类:
- 私有的存储:只由一个节点拥有
- 共享的存储:由集群中的多个节点拥有
所有应用程序的数据驻留在共享的存储设备中。为了避免数据不一致,可以按以下方式进行共享存储保护:
- 基于保留/释放的共享存储保护:用于标准的卷组
- 基于 RSCT 的共享存储保护:用于增强型并发卷组
HACMP 5.x 支持基于 RSCT 的共享存储保护,当以非并发模式使用增强型并发卷组时,这种保护方式依靠 AIXs RSCT 组件控制共享存储的所有权。
配置
在开始配置之前,必须适当地计划集群。可以使用在线计划工作表 (OLPW) 制定计划。下面解释一个两节点集群的配置。在此示例中,两个节点都有三个以太网适配器和两个共享磁盘。
步骤 1:安装文件集
在安装 AIX 之后,第一步是安装所需的文件集。安装以下文件集。可以在 AIX 基本版 CD 上找到 RSCT 和 BOS 文件集。安装 HACMP 文件集需要购买 PowerHA 许可证。
| RSCT 文件集 rsct.compat.basic.hacmp rsct.compat.clients.hacmp rsct.basic.hacmp rsct.basic.rte rsct.opt.storagerm rsct.crypt.des rsct.crypt.3des rsct.crypt.aes256 |
BOS 文件集 bos.data bos.adt.libm bos.adt.syscalls bos.clvm.enh bos.net.nfs.server |
HACMP 5.5 文件集 cluster.adt.es cluster.es.assist cluster.es.cspoc cluster.es.plugins cluster.assist.license cluster.doc.en_US.assist cluster.doc.en_US.es cluster.es.worksheets cluster.license cluster.man.en_US.assist cluster.man.en_US.es cluster.es.client cluster.es.server cluster.es.nfs cluster.es.cfs |
安装文件集之后,重新引导分区。
步骤 2:设置路径
接下来,需要设置路径。为此,在 /.profile 文件中添加以下代码:
export PATH=$PATH:/usr/es/sbin/cluster:/usr/es/sbin/cluster/utilities |
步骤 3:网络配置
按以下步骤在以太网适配器上配置 IP 地址:
#smitty tcpip -> Minimum Configuration and Startup -> Choose Ethernet network interface |
有三个以太网适配器。其中两个配置私有 IP 地址,另一个配置公共 IP 地址。
在这里,输入 en0 的相关字段的值,这个以太网适配器将配置公共 IP 地址。
图 1. 公共 IP 地址的配置
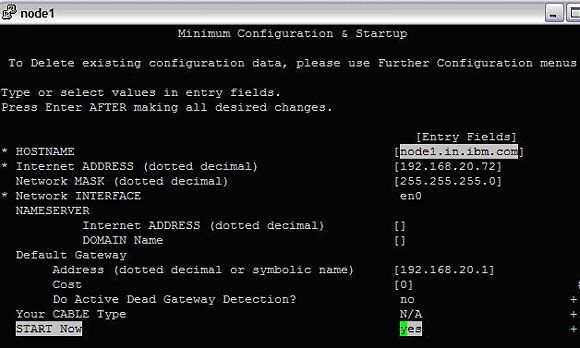
这会配置 IP 地址并在其上启动 TCP/IP 服务。
以相似方式在 en1 和 en2 上配置私有 IP 地址。
图 2. 私有 IP 地址的配置
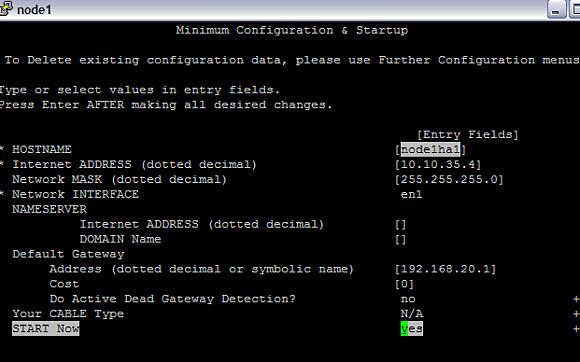
这为 en2 配置私有 IP 10.10.210.21 并启动 TCP/IP 服务。
接下来,需要在 /etc/hosts 文件中添加 IP 地址(包括 node1 和 node2 的 IP 地址以及服务 IP db2live)和标签。其内容应该像下面这样:
# Internet Address Hostname # Comments 127.0.0.1 loopback localhost # loopback (lo0) name/address 192.168.20.72 node1.in.ibm.com node1 192.168.20.201 node2.in.ibm.com node2 10.10.35.5 node2ha1 10.10.210.11 node2ha2 10.10.35.4 node1ha1 10.10.210.21 node1ha2 192.168.22.39 db2live |
注意,为了进行名称解析,应该包含每个机器的所有三个端口和相关标签。
在 node2 上执行相似的操作。为 en0 配置公共 IP,为 en1 和 en2 配置私有 IP,编辑 /etc/hosts 文件。
为了测试这些配置,可以从每个机器对各个 IP 地址执行 ping 操作。
步骤 4:存储配置
为了创建通过 FC 磁盘的心跳,需要一个共享的存储。需要从 SAN 分配磁盘。当两个节点能够看到相同的磁盘之后(可以使用 LUN 号来确认),配置通过磁盘的心跳。
为了避免以太网网络/交换机/协议造成单点故障,这种方法不使用以太网。
第一步是确定在所有节点上都可用的主号码。
图 3. 确定可用的主号码

选择一个惟一的数字。在这里,我们选择 100。
在 node1 上
- 在具有增强并发功能的共享磁盘 "hdisk1" 上创建卷组 "hbvg"。
#smitty mkvg
图 4. 创建卷组
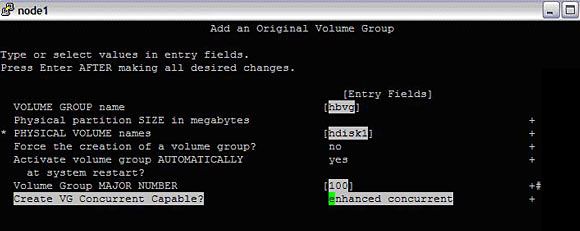
创建 hbvg 之后,需要禁用 autovaryon 标志。为此,运行以下命令:
#chvg -an hbvg
- 接下来,在卷组 "hbvg" 中创建逻辑卷。输入一个逻辑卷名称,比如 hbloglv,选择 1 作为逻辑分区号,选择 jfslog 作为类型,把 scheduling 设置为 sequential。其他选项保持默认值。按回车。
#smitty mklv
图 5. 创建逻辑卷
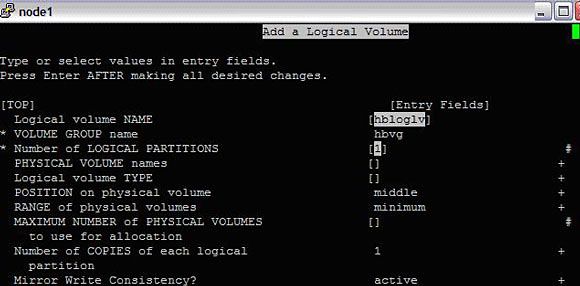
创建逻辑卷之后,初始化 logform。
#logform /dev/hbloglv
重复这个过程创建另一个逻辑卷,其类型为 jfs,名称为 hblv,其他设置相同。
- 接下来,创建一个文件系统。为此,运行以下命令:
#smitty crfs ->Add a Journaled File System -> Add a Journaled File System on a Previously Defined Logical Volume -> Add a Standard Journaled File System
在这里,输入逻辑卷名称 "hblv",选择 "hbloglv" 作为用于日志的逻辑卷,选择挂载点 /hb_fs。
图 6. 在逻辑卷中创建文件系统
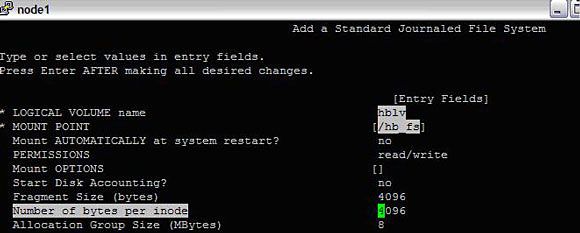
创建文件系统之后,尝试挂载文件系统。在转到 node2 之前,卸载 /hb_fs 并对 hbvg 执行 varyoffvg。
在 node2 上
- 使用 PVID 找到共享的磁盘。用相同的主号码从共享磁盘 (hdisk1) 导入卷组(在这里主号码是 100):
#importvg -V 100 -y hbvg hdisk1
- 对卷组执行 varyonvg,禁用在挂载时自动启动。
#varyonvg hbvg #chvg -an hbvg
现在,应该能够挂载文件系统了。完成之后,卸载文件系统并对 hbvg 执行 varyoffvg。
- 检查通过 FC 的心跳:
在两个节点上打开两个不同的会话。在 node1 上,运行以下命令,其中的 hdisk1 是共享磁盘。
#/usr/sbin/rsct/bin/dhb_read -p hdisk1 -r
在 node2 上:
/usr/sbin/rsct/bin/dhb_read -p hdisk1 -t
基本上,一个节点向磁盘发送心跳消息,另一个节点会探测到它。在正常情况下,报告链接操作之后,两个节点应该会返回到命令行。
与应用程序相关的配置
如果要让任何应用程序(例如 DB2 服务器)高度可用,需要执行与应用程序相关的配置。这超出了本文的范围。
与 HACMP 相关的配置
- 网络接管:
在两个节点上:
- 运行
grep -i community /etc/snmpdv3.conf | grep public,确保有一个与 COMMUNITY public public noAuthNoPriv 0.0.0.0 0.0.0.0 相似的非注释行。 - 接下来,需要在 /etc/rhosts 文件中添加 NIC 节点的所有 IP 地址。
# cat /usr/es/sbin/cluster/etc/rhosts 192.168.20.72 192.168.20.201 10.10.35.5 10.10.210.11 10.10.35.4 10.10.210.21 192.168.22.39
- 运行
配置 PowerHA 集群
在 node1 上:
- 首先定义一个集群:
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration --> Configure an HACMP Cluster --> Add/Change/Show an HACMP Cluster
图 7. 定义集群
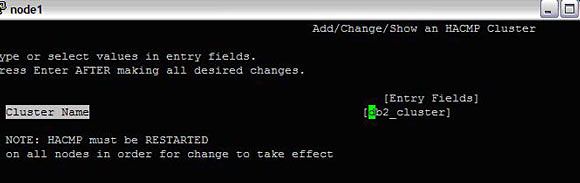
按回车。现在,集群定义好了。
- 在定义的集群中添加节点。
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration --> Configure HACMP Nodes --> Add a Node to the HACMP Cluster
图 8. 在集群中添加节点

以相似方式在集群中添加另一个节点。
现在,我们已经定义了集群并在其中添加了节点。接下来,让两个节点相互通信。
- 添加网络。我们将添加两种网络,IP(以太网)和非 IP (diskhb)。
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Configure HACMP Networks --> Add a Network to the HACMP Cluster
从列表中选择 "ether"。
图 9. 在集群中添加网络
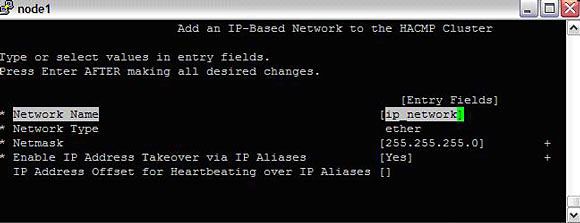
添加这个网络之后,返回到 "Add a network to the HACMP cluster" 并添加 diskhb 网络。
- 下一步是确定每个节点的哪个物理设备连接每个网络。
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Configure HACMP Communication Interfaces/Devices --> Add Communication Interfaces/Devices -->Add Pre-defined Communication Interfaces and Devices--> Communication Interfaces
选择上一步中添加的网络 (IP_network) 并输入与下面相似的配置:
图 10. 在集群中添加通信设备
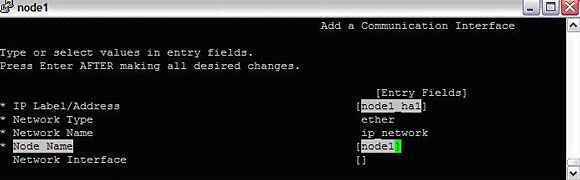
应该会出现一个警告,它指出特定网络上通信端口数量不足。
需要重复这些步骤,给各个网络分配用于 HACMP 的不同适配器;所以可以忽略警告,等到给网络分配了所有适配器之后,警告就会消失了。无论如何,对所有接口重复这些步骤。
注意,对于磁盘通信(磁盘心跳),步骤略有差异。
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Configure HACMP Communication Interfaces/Devices --> Add Communication Devices
选择 shared_diskhb 或相关名称并填写详细信息:
图 11. 在集群中添加通信接口
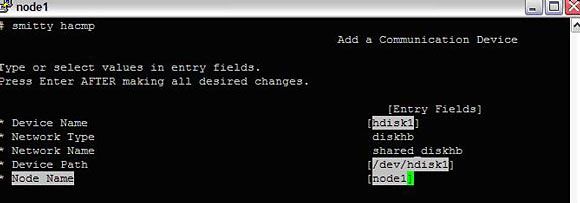
集群中的每个节点还需要有一个持久的节点 IP 地址。通过以下操作把每个节点与它的持久 IP 关联起来:
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Configure HACMP Persistent Node IP Label/Addresses
添加所有详细信息:
图 12. 在集群中添加持久 IP 地址
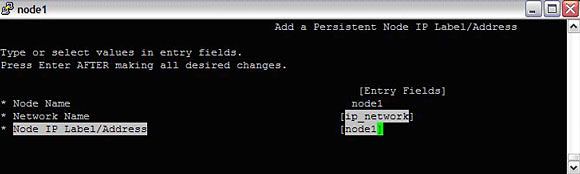
检查点:
添加所有东西之后,应该检查它们是否都是正确的。
#smitty hacmp --> Extended Configuration --> Extended Topology Configuration--> Show HACMP Topology -->Show Cluster Topology
这会列出所有网络、接口和设备。检查它们是否正确。
- 添加资源组:
到目前为止,我们已经定义了集群,在其中添加了节点,还配置了 IP 和非 IP 网络。下一步是配置资源组。正如前面指出的,资源组是资源的集合。应用服务器(例如 DB2 服务器)是需要保持高可用性的资源之一。
在资源组中添加应用服务器:
#smitty hacmp --> Extended Configuration-->Extended Resource Configuration-->HACMP Extended Resources Configuration--> Configure HACMP Application Servers-->Add an Application Server
图 13. 添加资源 - 应用服务器
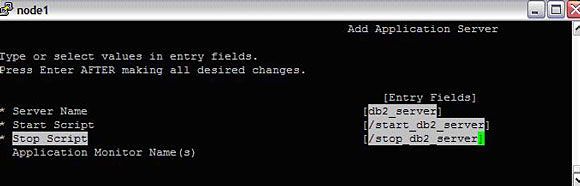
这指定服务器名称以及启动/停止应用服务器所需的启动和停止脚本。对于 DB2、WebSphere、SAP、Oracle、TSM、ECM、LDAP、IBM HTTP 等应用程序,产品附带启动/停止脚本。对于其他应用程序,管理员应该自己编写启动/停止应用程序的脚本。
要在资源组中添加的下一个资源是服务 IP。最终用户只通过这个 IP 连接应用程序。因此,服务 IP 应该保持高可用性。
#smitty hacmp --> Extended Configuration-->Extended Resource Configuration-->HACMP Extended Resources Configuration-->Configure HACMP Service IP Labels/Addresses--> Add a Service IP Label/Address
选择 "Configurable on Multiple Nodes",然后选择 "IP_network"。这里选择 db2live 作为服务 IP。
图 14. 添加资源 - 服务 IP
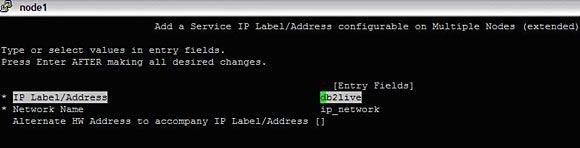
既然已经添加了资源,现在创建资源组 (RG)、定义 RG 策略并在其中添加所有资源。
#smitty hacmp --> Extended Configuration-->HACMP Extended Resource Group Configuration--> Add a Resource Group
图 15. 创建资源组
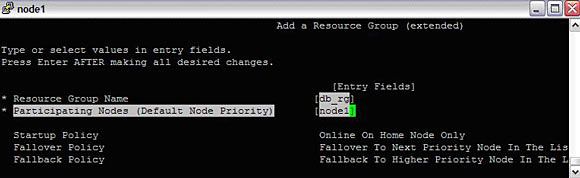
创建 RG 之后,可以修改它的属性:
#smitty hacmp --> Extended Configuration-->HACMP Extended Resource Group Configuration-->Change/Show Resources and Attributes for a Resource Group
选择 db2_rg 并根据需要配置它:
图 16. 定义资源组的各个属性
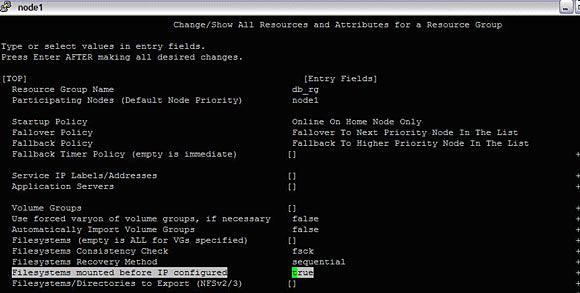
- 检查并同步
在主节点(在这里是 node1)上完成所有配置之后,需要让集群中的所有其他节点与它同步。方法如下:
#smitty hacmp--> Extended Configuration--> Extended Verification and Synchronization
Image 17. 检查并同步集群
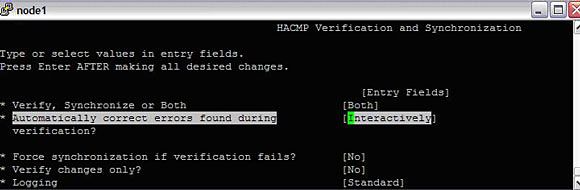
这先检查本地节点的状态和配置,然后把配置传播到集群中的其他节点(如果可以到达它们的话)。对于任何错误(和顺利完成的步骤),应该会显示大量详细信息。
完成之后,集群就准备好了。可以通过手工转移 RG 测试它。方法如下:
#smitty hacmp--> System Management (C-SPOC)--> HACMP Resource Group and Application Management--> Move a Resource Group to Another Node / Site--> Move Resource Groups to Another Node
选择 "node2" 并按回车。应该会看到在 node1 上运行停止脚本,在 node2 上运行启动脚本。几秒之后,RG 会在 node2 上上线。
参考资料
学习
- 阅读 High Availability Cluster Multi-Processing (HACMP) 产品文档。
- developerWorks 技术活动和网络广播:随时关注 developerWorks 技术活动和网络广播。
- 观看 developerWorks 演示中心,包括面向初学者的产品安装和设置演示,以及为经验丰富的开发人员提供的高级功能。
- AIX and UNIX 专区:developerWorks 的“AIX and UNIX 专区”提供了大量与 AIX 系统管理的所有方面相关的信息,您可以利用它们来扩展自己的 UNIX 技能。
- AIX and UNIX 新手入门:访问“AIX and UNIX 新手入门”页面可了解更多关于 AIX 和 UNIX 的内容。
- AIX and UNIX 专题汇总:AIX and UNIX 专区已经为您推出了很多的技术专题,为您总结了很多热门的知识点。我们在后面还会继续推出很多相关的热门专题给您,为了方便您的访问,我们在这里为您把本专区的所有专题进行汇总,让您更方便的找到您需要的内容。
- AIX and UNIX 下载中心:在这里你可以下载到可以运行在 AIX 或者是 UNIX 系统上的 IBM 服务器软件以及工具,让您可以提前免费试用他们的强大功能。
- IBM Systems Magazine for AIX 中文版:本杂志的内容更加关注于趋势和企业级架构应用方面的内容,同时对于新兴的技术、产品、应用方式等也有很深入的探讨。IBM Systems Magazine 的内容都是由十分资深的业内人士撰写的,包括 IBM 的合作伙伴、IBM 的主机工程师以及高级管理人员。所以,从这些内容中,您可以了解到更高层次的应用理念,让您在选择和应用 IBM 系统时有一个更好的认识。