【索引分类】B树索引
B树索引(默认类型)
B树索引在Oracle中是一个通用索引。在创建索引时它就是默认的索引类型。B树索引可以是一个列的(简单)索引,也可以是组合/复合(多个列)的索引。B树索引最多可以包括32列。

索引的作用:通过遍历树的方式,迅速定位节点,并确定地址,所以搜索技术最核心的是遍历搜索技术。
场合:非常适合数据重复度低的字段 例如 身份证号码 手机号码 QQ号等字段,常用于主键 唯一约束,一般在在线交易的项目中用到的多些。
原理:一个键值对应一行(rowid) 格式: 【索引头|键值|rowid】
优点:当没有索引的时候,oracle只能全表扫描where qq=40354446这个条件那么这样是灰常灰常耗时的,当数据量很大的时候简直会让人崩溃,那么有个B-tree索引我们就像翻书目录一样,直接定位rowid立刻就找到了我们想要的数据,实质减少了I/O操作就提高速度,它有一个显著特点查询性能与表中数据量无关,例如 查2万行的数据用了3 consistent get,当查询1200万行的数据时才用了4 consistent gets。
当我们的字段中使用了主键or唯一约束时,不用想直接可以用B-tree索引
缺点:不适合键值重复率较高的字段上使用
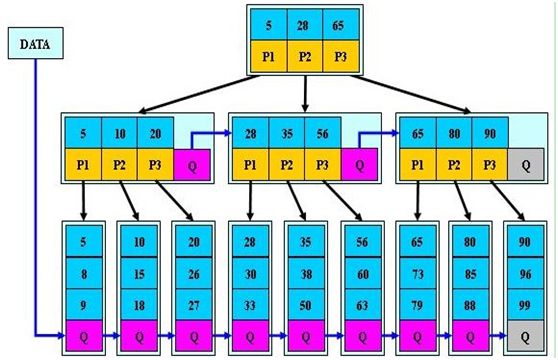
在下图的例子中,B树索引位于雇员表的last_name列上。这个索引的二元高度为3;接下来,Oracle会穿过两个树枝块(branch block),到达包含有ROWID的树叶块。在每个树枝块中,树枝行包含链中下一个块的ID号。
树叶块包含了索引值、ROWID,以及指向前一个和后一个树叶块的指针。Oracle可以从两个方向遍历这个二叉树。B树索引保存了在索引列上有值的每个数据行的ROWID值。Oracle不会对索引列上包含NULL值的行进行索引。如果索引是多个列的组合索引,而其中列上包含NULL值,这一行就会处于包含NULL值的索引列中,且将被处理为空(视为NULL)。

技巧:索引列的值都存储在索引中。因此,可以建立一个组合(复合)索引,这些索引可以直接满足查询,而不用访问表。这就不用从表中检索数据,从而减少了I/O量。
B-tree特点:
适合与大量的增、删、改(OLTP)
不能用包含OR操作符的查询;
适合高基数的列(唯一值多)典型的树状结构;
每个结点都是数据块;
大多都是物理上一层、两层或三层不定,逻辑上三层;
叶子块数据是排序的,从左向右递增;
在分支块和根块中放的是索引的范围;
【实验】
alter system flush shared_pool; 清空共享池
alter system flush buffer_cache; 清空数据库缓冲区,都是为了实验需要
创建leo_t1 leo_t2 表
leo_t1 表的object_id列的数据是没有重复值的,我们抽取了10行数据就可以看出来了。
LS@LEO> create table leo_t1 as selectobject_id,object_name from dba_objects;
LS@LEO> select count(*) from leo_t1;
COUNT(*)
----------
9872
LS@LEO> select * from leo_t1 where rownum <= 10;
OBJECT_ID OBJECT_NAME
---------- -----------
20ICOL$
44I_USER1
28CON$
15UNDO$
29C_COBJ#
3I_OBJ#
25PROXY_ROLE_DATA$
39I_IND1
51I_CDEF2
26I_PROXY_ROLE_DATA$_1
leo_t2 表的object_id列我们是做了取余操作,值就只有0,1两种,因此重复率较高,如此设置为了说明重复率对B树索引的影响
LS@LEO> create table leo_t2 as selectmod(object_id,2) object_ID ,object_name from dba_objects;
LS@LEO> select count(*) from leo_t2;
COUNT(*)
----------
9873
LS@LEO> select * from leo_t2 where rownum <=10;
OBJECT_ID OBJECT_NAME
---------- -----------
0ICOL$
0I_USER1
0CON$
1UNDO$
1C_COBJ#
1I_OBJ#
1PROXY_ROLE_DATA$
1I_IND1
1 I_CDEF2
0I_PROXY_ROLE_DATA$_1
LS@LEO> create index leo_t1_index onleo_t1(object_id); 创建B-tree索引,说明 默认创建的都是B-tree索引
Index created.
LS@LEO> create index leo_t2_index onleo_t2(object_ID); 创建B-tree索引
Index created.
让我们看一下leo_t1与leo_t2的重复情况
LS@LEO> select count(distinct(object_id)) fromleo_t1; 让我们看一下leo_t1与leo_t2的重复情况,leo_t1没有重复值,leo_t2有很多
COUNT(DISTINCT(OBJECT_ID))
--------------------------
9872
LS@LEO> select count(distinct(object_ID)) fromleo_t2;
COUNT(DISTINCT(OBJECT_ID))
--------------------------
2
收集2个表统计信息
LS@LEO> executedbms_stats.gather_table_stats(ownname=>'LS',tabname=>'LEO_T1',method_opt=>'forall indexed columns size 2',cascade=>TRUE);
LS@LEO> executedbms_stats.gather_table_stats(ownname=>'LS',tabname=>'LEO_T2',method_opt=>'forall indexed columns size 2',cascade=>TRUE);
参数详解:
method_opt=>'for all indexed columns size2' size_clause=integer 整型 ,范围 1~254 ,使用柱状图[histogram analyze ]分析列数据的分布情况
cascade=>TRUE 收集表的统计信息的同时收集B-tree索引的统计信息
显示执行计划和统计信息+设置autotrace简介
序号 命令 解释
1 SETAUTOTRACE OFF 此为默认值,即关闭Autotrace
2 SET AUTOTRACE ON EXPLAIN 只显示执行计划
3 SETAUTOTRACE ON STATISTICS 只显示执行的统计信息
4 SETAUTOTRACE ON 包含2,3两项内容
5 SET AUTOTRACE TRACEONLY 与ON相似,但不显示语句的执行结果
结果键值少的情况
set autotrace trace exp stat; (SET AUTOTRACE OFF 关闭执行计划和统计信息)
LS@LEO> select * from leo_t1 where object_id=1;
no rows selected
Execution Plan 执行计划
----------------------------------------------------------
Plan hash value: 3712193284
--------------------------------------------------------------------------------------------
| Id |Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 1 | 21 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| LEO_T1 | 1 | 21 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN索引扫描 | LEO_T1_INDEX | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operationid):
---------------------------------------------------
2 -access("OBJECT_ID"=1)
Statistics 统计信息
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets 我们知道leo_t1表的object_id没有重复值,因此使用B-tree索引扫描只有2次一致性读
0 physical reads
0 redo size
339 bytes sent via SQL*Net toclient
370 bytes received via SQL*Netfrom client
1 SQL*Net roundtrips to/fromclient
0 sorts (memory)
0 sorts (disk)
0 rows processed
结果键值多的情况
LS@LEO> select * from leo_t2 where object_ID=1;(select/*+full(leo_t2) */ * from leo_t2 whereobject_ID=1;hint方式强制全表扫描)
4943 rows selected.
Execution Plan 执行计划
----------------------------------------------------------
Plan hash value: 3657048469
----------------------------------------------------------------------------
| Id |Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 4943 | 98860 | 12 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| LEO_T2 | 4943 | 98860| 12 (0)| 00:00:01 | sql结果是4943row,那么全表扫描也是4943row
----------------------------------------------------------------------------
Predicate Information (identified by operationid):
---------------------------------------------------
1 -filter("OBJECT_ID"=1)
Statistics 统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
366 consistent gets 导致有366次一致性读
0 physical reads
0 redo size
154465 bytes sent via SQL*Net toclient
4000 bytes received via SQL*Netfrom client
331 SQL*Net roundtrips to/fromclient
0 sorts (memory)
0 sorts (disk)
4943 rows processed
大家肯定会疑惑,为什么要用全表扫描而不用B-tree索引呢,这是因为oracle基于成本优化器CBO认为使用全表扫描要比使用B-tree索引性能更好更快,由于我们结果重复率很高,导致有366次一致性读,从cup使用率12%上看也说明了B-tree索引不适合键值重复率较高的列
我们在看一下强制使用B-tree索引时,效率是不是没有全表扫描高呢?
LS@LEO> select /*+index(leo_t2 leo_t2_index) */ * from leo_t2where object_ID=1; hint方式强制索引扫描
4943 rows selected.
Execution Plan 执行计划
----------------------------------------------------------
Plan hash value: 321706586
--------------------------------------------------------------------------------------------
| Id |Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 |SELECT STATEMENT | | 4943 | 98860 | 46 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| LEO_T2 | 4943 | 98860 | 46 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | LEO_T2_INDEX | 4943 | | 10 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------
Predicate Information (identified by operationid):
---------------------------------------------------
2 -access("OBJECT_ID"=1)
Statistics 统计信息
----------------------------------------------------------
1 recursive calls
0 db block gets
704 consistent gets 使用B-tree索引704次一致性读 > 全表扫描366次一致性读,而且cpu使用率也非常高,显然效果没有全表扫描高
0 physical reads
0 redo size
171858 bytes sent via SQL*Net toclient
4000 bytes received via SQL*Netfrom client
331 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
4943 rows processed
小结:从以上的测试我们可以了解到,B-tree索引在什么情况下使用跟键值重复率高低有很大关系的,之间没有一个明确的分水岭,只能多测试分析执行计划后来决定。