Hbase+ Phoenix搭建教程
Hbase+ Phoenix搭建教程
一、Hbase简介
HBase是基于列存储、构建在HDFS上的分布式存储系统,其主要功能是存储海量结构化数据。

HBase构建在HDFS之上,因此HBase也是通过增加廉价的PC机提高系统运行和存储的能力。
HBase中存储的表有如下特点:
1、大表:一个表可以有数十亿行,上百万列;
2、无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态的增加,同一张表中不同的行可以有截然不同的列;
3、面向列:面向列(族)的存储和权限控制,列(族)独立检索;
4、稀疏:对于空(null)的列,并不占用存储空间,表可以设计的非常稀疏;
5、数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳;
6、数据类型单一:Hbase中的数据都是字符串,没有类型。
二、hbase的适用场景
1、存在高并发读写
2、表结构的列族经常需要调整
3、存储结构化或半结构化数据
4、高并发的key-value存储
5、key随机写入,有序存储
6、针对每个key保存一个固定大小的集合 多版本
同样hbase数据也存在不适用的场景
1、由于hbase只能提供行锁,它对分布式事务支持不好
2、对于查询操作中的join、group by 性能很差
3、查询如果不使用row-key查询,性能会很差,因为此时会进行全表扫描,建立二级索引或多级索引需要同时维护一张索引表
4、高并发的随机读支持有限
三、hbase基本架构及组件说明
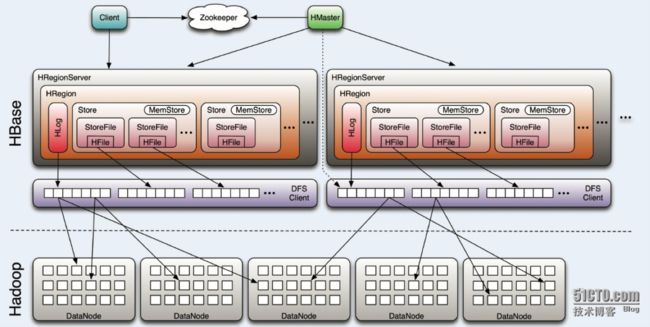
由上图可知,hbase包括Clinet、HMaster、HRegionServer、ZooKeeper组件
各组件功能介绍:
1、Client
Client主要通过ZooKeeper与Hbaser和HRegionServer通信,对于管理操作:client向master发起请求,对于数据读写操作:client向regionserver发起请求
2、ZooKeeper
zk负责存储_root_表的地址,也负责存储当前服务的master地址,regsion server也会将自身的信息注册到zk中,以便master能够感知region server的状态,zk也会协调active master,也就是可以提供一个选举master leader,也会协调各个region server的容灾流程
3、HMaster
master可以启动多个master,master主要负责table和region的管理工作,响应用户对表的CRUD操作,管理region server的负载均衡,调整region 的分布和分配,当region server停机后,负责对失效的regionn进行迁移操作
4、HRegionServer
region server主要负责响应用户的IO请求,并把IO请求转换为读写HDFS的操作
二、hbase安装
参考:http://hbase.apache.org/book/quickstart.html
三、添加Phoenix支持
Phoenix安装
- 下载 我们的HBase版本是0.98.6-hadoop2,对应的Phoenix版本是4.3.1
wget http://mirrors.cnnic.cn/apache/phoenix/phoenix-4.3.1/bin/phoenix-4.3.1-bin.tar.gz
- 解压
tar -zxvf phoenix-4.3.1-bin.tar.gz
- 拷贝jar文件到HBase HMaster,和所有RegionServer的lib目录下
cp phoenix-4.3.1-bin/phoenix-4.3.1-server.jar $(HBASE_HOME)/lib
- 配置HMaster的hbase-site.xml
<!-- Phoenix订制的索引负载均衡器 --><property><name>hbase.master.loadbalancer.class</name><value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value></property><!-- Phoenix订制的索引观察者 --><property><name>hbase.coprocessor.master.classes</name><value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value></property>
- 配置RegionServer的hbase-site.xml
<!-- Enables custom WAL edits to be written, ensuring proper writing/replay of the index updates. This codec supports the usual host of WALEdit options, most notably WALEdit compression. --><property><name>hbase.regionserver.wal.codec</name><value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value></property><!-- Prevent deadlocks from occurring during index maintenance for global indexes (HBase 0.98.4+ and Phoenix 4.3.1+ only) by ensuring index updates are processed with a higher priority than data updates. It also prevents deadlocks by ensuring metadata rpc calls are processed with a higher priority than data rpc calls --><property><name>hbase.region.server.rpc.scheduler.factory.class</name><value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property><property><name>hbase.rpc.controllerfactory.class</name><value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value><description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description></property><!-- To support local index regions merge on data regions merge you will need to add the following parameter to hbase-site.xml in all the region servers and restart. (It’s applicable for Phoenix 4.3+ versions) --><property><name>hbase.coprocessor.regionserver.classes</name><value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value></property>
- 配置Tracing (hadoop-metrics2-hbase.properties) 在HBase的HMaster和所有RegionServer下的conf/hadoop-metrics2-hbase.properties中加入如下配置
# ensure that we receive traces on the server hbase.sink.tracing.class=org.apache.phoenix.trace.PhoenixMetricsSink # Tell the sink where to write the metrics hbase.sink.tracing.writer-class=org.apache.phoenix.trace.PhoenixTableMetricsWriter # Only handle traces with a context of "tracing" hbase.sink.tracing.context=tracing 验证
按照上面的步骤配置完成后就可以进行验证了~本地验证方式如下,进行验证:
- 启动hbase集群
$(HBASE_HOME)/bin/start-hbase.sh - 启动Phoenix SQLLine工具
$(PHOENIX_HOME)/bin/sqlline.py localhost - 运行Phoenix Performance 工具,本地测试的话数据尽量不要超过1000w,通常1000w数据会报错。。。 如下命令,第一个参数是zk地址,第二个是性能测试的数据数量,测试数据会自动生成
$(PHOENIX_HOME)/bin/performance.py localhost1000000
- 在Phoenix SQLLine中进行一些查询操作,sql语法可以参考
http://phoenix.apache.org/language/index.html
备注:
http://nunknown.com/study/282/
bin/hadoop fs -ls /user/root/output3
https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
https://hadoop.apache.org/docs/r2.7.1/hadoop-project-dist/hadoop-common/SingleCluster.html#YARN_on_Single_Node
编译hadoop
http://zilongzilong.iteye.com/blog/2246856
https://segmentfault.com/a/1190000000583427#articleHeader1
http://www.ixirong.com/2015/06/24/how-hbase-use-apache-phoenix/
http://www.infoq.com/cn/news/2013/02/Phoenix-HBase-SQL