R语言︱SNA-社会关系网络—igraph包(社群划分、画图)(三)
社群划分跟聚类差不多,参照《R语言与网站分析》第九章,社群结构特点:社群内边密度要高于社群间边密度,社群内部连接相对紧密,各个社群之间连接相对稀疏。
社群发现有五种模型:点连接、随机游走、自旋玻璃、中间中心度、标签发现。
评价社群三个指标:模块化指标Q、网络聚类系数、网络密度。
画图有三种方法:直接plot、书中自编译函数、SVG。
———————————————————————————————————
不同社群划分模型的区别
| 社群模型 | 概念 | 效果 |
| 点连接 | 某点与某社群有关系就是某社群的 | 最差,常常是某一大类超级多 |
| 随机游走 | 利用距离相似度,用合并层次聚类方法建立社群 | 运行时间短,但是效果不是特别好,也会出现某类巨多 |
| 自旋玻璃 | 关系网络看成是随机网络场,利用能量函数来进行层次聚类 | 耗时长,适用较为复杂的情况 |
| 中间中心度 | 找到中间中心度最弱的删除,并以此分裂至到划分不同的大群落 | 耗时长,参数设置很重要 |
| 标签传播 | 通过相邻点给自己打标签,相同的标签一个雷 | 跟特征向量可以组合应用,适用于话题类 |
———————————————————————————————————
一、社群发现模型
1、基于点连接的社群发现——clusters
如果一个点与社群有联系则放在一个网络中,简单易懂,耗时短,但是分类效果并不特别好。
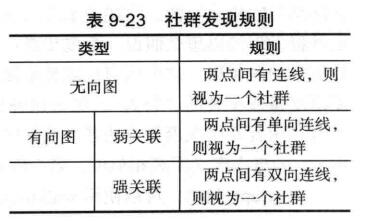
clusters(g.dir,mode="weak")
mode是用来选择强关联还是弱关联,weak or strong.
2、随机游走的社群发现

member<-walktrap.community(g.undir,weights=E(g)$weight,step=4)weight代表线权重,默认就是E(g)$label;step代表游走步长,越大代表分类越粗糙,分类类别越小。默认为4.
3、自旋玻璃社群发现

member<-spinglass.community(g.undir,weights=E(g.undir)$weight,spins=2) #需要设置参数weights,因为无默认值weight代表线权重,但是与随机游走不同,其要自己赋上去,weight=E(g)$label不能少;spins代表产生的社群数,默认值为25。
这个社群分类函数有了自己定义分类数量的效果。
4、中间中心度社群发现

member<-edge.betweenness.community(g.undir,weight=E(g)$weight,directed=F)
有默认的线权重,并且默认是无向线的,directed=T时就代表有向线。
5、传播标签社群发现

#社群发现方法五:标签传播社群发现
member<-label.propagation.community(g.undir,weights=V(g.undir)$weight)
V(g.undir)$member
member<-label.propagation.community(g.undir,weights = E(g.undir)$weight,initial = c(1,1,-1,-1,2,-1,1))
V(g.undir)$member
member<-label.propagation.community(g.undir,weights = E(g.undir)$weight,
initial = c(1,1,-1,-1,2,-1,1),fixed=c(T,F,F,F,F,F,T))
initial是社群初始化函数,默认为-1(不设置初始值),当然这里你也可以设置;如initial=c(1,1,-1,-1,2)就代表1,2个数为社群1;3、4不设置初始值;5个为社群2
fixed是用来固定函数的,当然如果没有设定初始值,如3.4.6则T,F都无效;如果设定了初始值,T则代表固定在原设定上。
———————————————————————————————————
二、衡量社群的指标
1、模块化指标Q——modularity
相当于是组内误差。
modularity(g.undir,membership=c(1,1,1,2,2,2,2)) #社群总差异,membership设置社群号
membership是每个点的各自分组情况。
2、网络聚类系数——transitivity
按照图形理论,聚集系数是表示一个图形中节点聚集程度的系数,一个网络一个值。
transitivity(g)可以衡量网络中关联性如何,值越大代表交互关系越大。说明网络越复杂,越能放在一块儿,聚类。
比如c(1,2,2,3,3,1)=1;c(1,2,2,3,3,1,1,4,4,3)=0.75,他是衡量是否有loop,能否找到循环到自己的线,三元组。
3、网络密度——graph.density
跟网路聚类系数差不多,也是用来形容网络的结构复杂程度。越大,说明网络越复杂,说明网络越能够放在一块。
graph.density(g.zn) graph.density(group1) graph.density(group2) #从中可以看到不同社群与整体之间的网络密度情况(关联程度)
———————————————————————————————————
三、画 图
由于关系网络图很复杂,而且数据量一大,小的图片形式网路图基本就是一坨浆糊。所以这里JPEG一定要足够大,最好的就是SVG格式。SVG格式的好处就是矢量图,你可以自己放大缩小,而且还可以用工具进行修改。但是最不好就是,一般的工具还打开不了,要用一些特有的工具,打开之后也会出现一些问题。
当然你是可以直接plot的。
1、直接plot
plot(g.test,layout=layout.fruchterman.reingold,edge.arrow.size=0.1,vertex.color=rainbow(7,alpha=0.3),edge.arrow.mode = "-")
代码解读:edge.arrow.size=0.1箭头大小;
vertex.color=rainbow(7,alpha=0.3)颜色,七种;
edge.arrow.mode = "-"连接方式用-。
其中还有很多参数类型:
#vertex.size=1表示节点的大小 #layout表示布局方式(发散性) #vertex.label=NA,不显示任何点信息,默认显示idx号 #vertex.color=V(g)$color 点的颜色设置 #mark.groups表示设置分组 #vertex.shape='none'不带边框 #vertex.label.cex=1.5, #节点字体大小 #vertex.label.color='red' #edge.arrow.size=0.7 #连线的箭头的大小 #edge.color = grey(0.5)#线的颜色 #edge.arrow.mode = "-" 箭头换成线 #vertex.label.dist=5 点标签和节点之间的距离一般0.1,便于错开重叠
2、简易画图自编译函数
R语言与网站分析中还专门写了一个画图函数。
plot.membership<-function(graph,membership,main=""){
V(graph)$member<-membership
mem.col<-rainbow(length(unique(membership)),alpha=0.3)
V(graph)$color<-mem.col[membership]
plot(graph,edge.width=E(graph)$weight,vertex.color=V(graph)$color,main=main)
}
函数需要输入三样东西(关系网络,分组情况,标题)。这里借助上面的社群分类都是可以得到的。用点连接来举个例子:
plot.membership(g.undir,clusters(g.undir)$membership,"无向图的社群发现")
3、SVG如何画高质量图
画一个好看的图你需要考虑这么几个问题:
不同重要性的点是否需要不同的大小?——V(g)$size
重要的点是否要加入其名字标签?——V(g)$label
不同社群的点,是否需要不同的颜色?——V(g)$member
(1)设置点大小
V(gg)$size = 5 V(gg)[degree(g)>=3000]$size = 15
其他节点尺寸都是5,而点度数大于3000的节点尺寸是15;
(2)设置不同社群颜色
mem.col<-rainbow(length(unique(V(g)$member)),alpha = 0.3) V(g)$color<-mem.col[V(g)$member]rainbow是生成颜色的参数,比如"#FF00004D" "#00FFFF4D"
第二句话是将每个点附上颜色。
(3)设置重点词标签
V(g)$label=NA V(g)[degree(g)>=3000]$label=V(gg)[degree(g)>=3000]$name
非重点词不给标签,重点词点度大于3000的给标签名字。
最后的SVG画图函数就是:
svg(filename=paste("C:/Users/long/Desktop","/1.svg",sep = ""),width = 40,height = 40)
plot(data.g,layout=layout.fruchterman.reingold,vertex.color=V(g)$color,vertex.label=V(g)$label,<span style="font-family: Arial, Helvetica, sans-serif;">vertex.size=V(g)$size</span>)
dev.off()
其中layout.fruchterman.reingold是发散式的布局方式。