数据库知识总结
1 关系数据库的设计范式有哪些?
第一范式: 关系数据库表的每一列都是不可分割的基本数据项。第一范式是确保列中的值是不重复。
第二范式:必须是第一范式。而且数据库表中的每一行必须被唯一的区分。 通常将表的一个或者多个属性作为行的主键。(另一种说法:而且R中每一个非主属性完全函数依赖于R的某个候选键)
第三范式:必须是第二范式。一个表中的列不能依赖于另一个表中的非主键列。(另一种说法:每个非主属性都不传递依赖于R的候选键)
BCF: 必须是第一范式,而且每个属性都不传递依赖于关系R的候选键。
第四范式:设R是一个关系模式,D是R上的多值依赖集合。如果D中成立非平凡多值依赖X->->Y时,X必是R的超键。
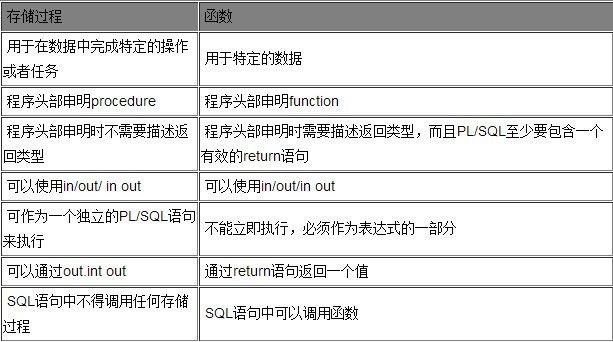
2 存储过程和函数的区别是什么?
存储过程是用户定义的一系列SQL语句的集合,涉及特定表或其他对象的任务,用户可以调用存储过程。而函数通常是它接收参数并返回某种类型的值,并且不涉及特定用户表。
如下表格是在Oracle中里面的:
存储过程的定义:
CREATE [OR REPLACE] Procedure [模式名.]过程名
[(参数名 [IN | OUT| IN OUT ] 数据类型 ...)]
{IS | AS}
[说明部分]
<PL/SQL块>;
函数的定义:
CREATE [OR REPLACE] FUNCTION [模式名.]过程名
[(参数名 [IN ] 数据类型 ...)]
RETURN 数据类型
{IS | AS}
[说明部分]
<PL/SQL块>;
3 什么是数据库事务?
答案:数据库事务是指作为单个逻辑工作单元执行的一系列操作,这些操作要么全做,要么全不做,是一个不可分割的工作单位。 满足ACID。
A 原子性: 事务的原子性是指一个事务要么全部执行,要么不执行。
C 一致性: 事务的一致性是指事务的运行并不改变数据库中数据的一致性。 (银行转账)
I 独立性:事务的独立性是指并发执行的事务相互之间不能干扰。
D 持久性: 事务的持久性是指 事务运行成功以后,系统的更新是永久的。
4 索引基本问题
5 解释聚集索引和非聚集索引之间的区别
答案: 聚集索引的顺序就是数据的物理存储顺序,而对非聚集索引是索引顺序与数据的物理存储顺序无关。正因为如此,一个表最多只能有一个聚集索引。
聚集索引确定了数据的物理顺序。聚集索引类似于电话薄(按姓氏排序)。 由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。但该索引可以包含多个列(组合索引),就像电话薄按照姓氏和名字进行组织一样。 聚集索引对于那些经常要搜索范围值的列特别有效。使用聚集索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理上相邻。
非聚集索引:非聚集索引与课本中索引类似。数据存储在一个地方,索引存储在另一个地方,索引带有指针指向数据的存储位置。索引中的项目按照索引键值的顺序存储,而表中的信息按另一种顺序存储。
eg: 在sql Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚集索引: 索引的叶节点就是数据节点。 而非聚集索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
6 角色
数据库角色是被命名的一组与数据库操作相关的权限,角色是权限的集合。因此可以为一组具有相同权限的用户创建一个角色,使用角色来管理数据库权限可以简化授权的过程。
1 创建一个角色
Create ROLE R1;
2 使用GRANT语句,使角色R1拥有Student表的SELECT、UPDATE、INSERT权限
GRANT SELECT ,PDATE,INSERT
ON TABLE Student
TO R1;
3 将这个角色授予王平,张明,赵玲。使他们具有角色R1所包含的全部权限
GRANT R1
TO 王平,张明, 赵玲;
4 当然,也可以一次性的通过R1来回收王平的这3个权限
REVOKE R1
FROM 王平;
角色的修改
GRANT DELETE
ON TABLE Student
TO R1
使角色R1在原来的基础上增加了Student表的DELETE权限
REVOKE SELECT
ON TABLE Student
FROM R1;
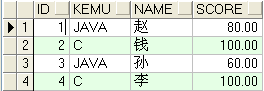
7 求成绩第二高的学生的名字
求:1、每个科目的最高分。
2、java成绩最高的姓名
3、java成绩第二高的姓名
1.每个科目的最高分:
SELECT kemu,max(score) FROM table GROUP BY kemu;
分析:找出成绩最高的人后,根据科目分组就可以得到每组的最高分的人。
2.java成绩最高的姓名:
SELECT name FROM table WHERE kemu='java' and
score=(SELECT max(score) FROM table WHERE kemu='java');
分析:从表格中查询名称时,提出两点条件1.科目是java,2.科目是java的最高分
3.java成绩第二高的姓名:
SELECT name FROM table WHERE kemu='java' GROUP BY name
ORDER BY SCORE DESC LIMIT 1,1;
分析:在查询姓名时根据[color=blue] kemu='java' [/color]这个条件,然后根据姓名分组,然后根据成绩排序,最后在列表中根据TOP 方法 LIMIT 选取从0开始的第二个姓名,只取1个人。OK了!这个题目主要考察了分组,排名和TOP取值方面的知识,难度相对最高。如果遇到这样的题,应该把大的问题一个个分散成小问题,然后一个个的解决小问题,然后拼凑起来,大问题就可以解决了。
8 稠密索引和稀疏索引
www.2cto.com

www.2cto.com
10 B-Tree索引和Hash索引的区别
Hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
可能很多人又有疑问了,既然 Hash 索引的效率要比 B-Tree 高很多,为什么大家不都用 Hash 索引而还要使用 B-Tree 索引呢?任何事物都是有两面性的,Hash 索引也一样,虽然 Hash 索引效率高,但是 Hash 索引本身由于其特殊性也带来了很多限制和弊端,主要有以下这些。
(1)Hash 索引仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询。
由于 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以它只能用于等值的过滤,不能用于基于范围的过滤,因为经过相应的 Hash 算法处理之后的 Hash 值的大小关系,并不能保证和Hash运算前完全一样。
(2)Hash 索引无法被用来避免数据的排序操作
由于 Hash 索引中存放的是经过 Hash 计算之后的 Hash 值,而且Hash值的大小关系并不一定和 Hash 运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算;
(3)Hash 索引不能利用部分索引键查询。
对于组合索引,Hash 索引在计算 Hash 值的时候是组合索引键合并后再一起计算 Hash 值,而不是单独计算 Hash 值,所以通过组合索引的前面一个或几个索引键进行查询的时候,Hash 索引也无法被利用。
(4)Hash 索引在任何时候都不能避免表扫描
前面已经知道,Hash 索引是将索引键通过 Hash 运算之后,将 Hash运算结果的 Hash 值和所对应的行指针信息存放于一个 Hash 表中,由于不同索引键存在相同 Hash 值,所以即使取满足某个 Hash 键值的数据的记录条数,也无法从 Hash 索引中直接完成查询,还是要通过访问表中的实际数据进行相应的比较,并得到相应的结果。
(5)Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高。
对于选择性比较低(即选择度 %)的索引键,如果创建 Hash 索引,那么将会存在大量记录指针信息存于同一个 Hash 值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据的访问,而造成整体性能低下。
hash相当于把key通过hash函数计算,得到key的hash值,再用这个hash值做指针,查找hash表中是否存在key,如果存在就返回 key所对应的value,选定一个好的hash函数很重要,好的hash函数可以使计算出的hash值分布均匀,降低冲突,只有冲突减小了,才会降低 hash表的查找时间。
b-tree完全基于key的比较,和二叉树相同的道理,相当于建个排序后的数据集,使用二分法查找算法,实际上也非常快,而且受数据量增长影响非常小。