社团划分——Fast Unfolding算法
社团划分——Fast Unfolding算法
一、社区划分问题
1、社区以及社区划分
在社交网络中,用户相当于每一个点,用户之间通过互相的关注关系构成了整个网络的结构,在这样的网络中,有的用户之间的连接较为紧密,有的用户之间的连接关系较为稀疏,在这样的的网络中,连接较为紧密的部分可以被看成一个社区,其内部的节点之间有较为紧密的连接,而在两个社区间则相对连接较为稀疏,这便称为社团结构。
(Newman and Gievan 2004) A community is a subgraph containing nodes which are more densely linked to each other than to the rest of the graph or equivalently, a graph has a community structure if the number of links into any subgraph is higher than the number of links between those subgraphs.
如下图:
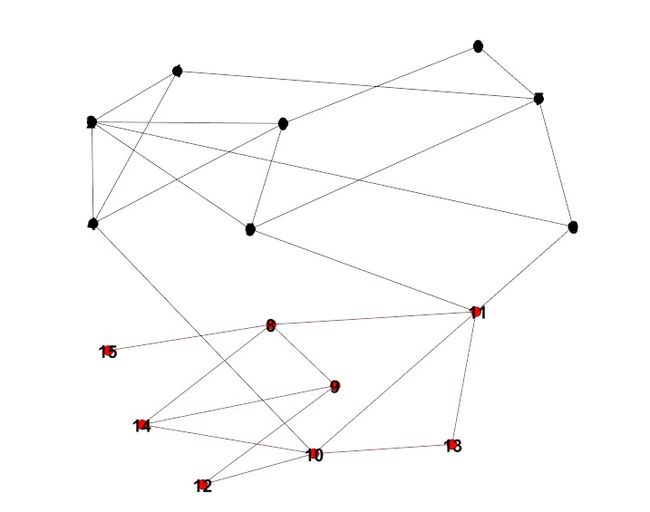
用红色的点和黑色的点对其进行标注,整个网络被划分成了两个部分,其中,这两个部分的内部连接较为紧密,而这两个社区之间的连接则较为稀疏。如何去划分上述的社区便称为社区划分的问题。
2、社区划分的算法
在社区划分问题中,存在着很多的算法,如由Newman和Gievan提出的GN算法,标签传播算法(Label Propagation Algorithm, LPA),这些算法都能一定程度的解决社区划分的问题,但是性能则是各不相同。总的来说,在社区划分中,主要分为两大类算法
- 凝聚方法(agglomerative method):添加边
- 分裂方法(divisive method):移除边
在后续的文章中,我们会继续关注不同的社区划分的算法,在这篇文章中,主要关注Fast Unfolding算法。
3、社区划分的评价标准
为了评价社区划分的优劣,Newman等人提出了模块度的概念,用模块度来衡量社区划分的好坏。简单来讲,就是将连接比较稠密的点划分在一个社区中,这样模块度的值会变大,最终,模块度最大的划分是最优的社区划分。
二、模块度的概念
1、模块度的公式
社区划分的目标是使得划分后的社区内部的连接较为紧密,而在社区之间的连接较为稀疏,通过模块度的可以刻画这样的划分的优劣,模块度越大,则社区划分的效果越好 ,模块度的公式如下所示:
其中, m=12∑i,jAi,j 表示的是网络中的所有的权重, Ai,j 表示的是节点 i 和节点 j 之间的权重, ki=∑jAi,j 表示的是与顶点 i 连接的边的权重, ci 表示的是顶点被分配到的社区, δ(ci,cj) 用于判断顶点 i 与顶点 j 是否被划分在同一个社区中,若是,则返回 1 ,否则,返回 0 。
2、模块度公式的简化形式
上述的模块度的计算可以得到以下的简化形式:
其中, ∑in 表示的是社区 c 内部的权重, ∑tot 表示的是与社区 c 内部的点连接的边的权重,包括社区内部的边以及社区外部的边。
3、模块度公式的解释
模块度(modularity)指的是网络中连接社区结构内部顶点的边所占的比例,减去在同样的社团结构下任意连接这两个节点的比例的期望值。
三、Fast Unfolding算法
1、Fast Unfolding算法的思路
模块度成为度量社区划分优劣的重要标准,划分后的网络模块度值越大,说明社区划分的效果越好,Fast Unfolding算法便是基于模块度对社区划分的算法,Fast Unfolding算法是一种迭代的算法,主要目标是不断划分社区使得划分后的整个网络的模块度不断增大。
2、Fast Unfolding算法的过程
Fast Unfolding算法主要包括两个阶段,如下图所示:
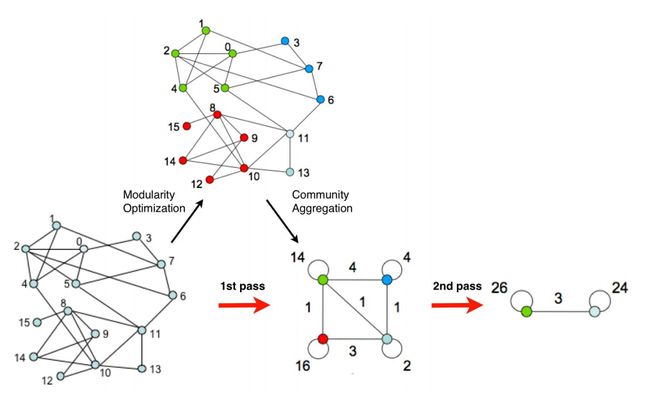
第一阶段称为Modularity Optimization,主要是将每个节点划分到与其邻接的节点所在的社区中,以使得模块度的值不断变大;第二阶段称为Community Aggregation,主要是将第一步划分出来的社区聚合成为一个点,即根据上一步生成的社区结构重新构造网络。重复以上的过程,直到网络中的结构不再改变为止。
具体的算法过程如下所示:
- 初始化,将每个点划分在不同的社区中;
- 对每个节点,将每个点尝试划分到与其邻接的点所在的社区中,计算此时的模块度,判断划分前后的模块度的差值 ΔQ 是否为正数,若为正数,则接受本次的划分,若不为正数,则放弃本次的划分;
- 重复以上的过程,直到不能再增大模块度为止;
- 构造新图,新图中的每个点代表的是步骤3中划出来的每个社区,继续执行步骤2和步骤3,直到社区的结构不再改变为止。
注意:在步骤2中计算节点的顺序对模块度的计算是没有影响的,而是对计算时间有影响。
四、算法实现
针对上图表示的网络,最终的结果为:

可以使用下面的程序实现其基本的原理:
import string
def loadData(filePath):
f = open(filePath)
vector_dict = {}
edge_dict = {}
for line in f.readlines():
lines = line.strip().split("\t")
for i in xrange(2):
if lines[i] not in vector_dict:
#put the vector into the vector_dict
vector_dict[lines[i]] = True
#put the edges into the edge_dict
edge_list = []
if len(lines) == 3:
edge_list.append(lines[1-i]+":"+lines[2])
else:
edge_list.append(lines[1-i]+":"+"1")
edge_dict[lines[i]] = edge_list
else:
edge_list = edge_dict[lines[i]]
if len(lines) == 3:
edge_list.append(lines[1-i]+":"+lines[2])
else:
edge_list.append(lines[1-i]+":"+"1")
edge_dict[lines[i]] = edge_list
return vector_dict, edge_dict
def modularity(vector_dict, edge_dict):
Q = 0.0
# m represents the total wight
m = 0
for i in edge_dict.keys():
edge_list = edge_dict[i]
for j in xrange(len(edge_list)):
l = edge_list[j].strip().split(":")
m += string.atof(l[1].strip())
# cal community of every vector
#find member in every community
community_dict = {}
for i in vector_dict.keys():
if vector_dict[i] not in community_dict:
community_list = []
else:
community_list = community_dict[vector_dict[i]]
community_list.append(i)
community_dict[vector_dict[i]] = community_list
#cal inner link num and degree
innerLink_dict = {}
for i in community_dict.keys():
sum_in = 0.0
sum_tot = 0.0
#vector num
vector_list = community_dict[i]
#print "vector_list : ", vector_list
#two loop cal inner link
if len(vector_list) == 1:
tmp_list = edge_dict[vector_list[0]]
tmp_dict = {}
for link_mem in tmp_list:
l = link_mem.strip().split(":")
tmp_dict[l[0]] = l[1]
if vector_list[0] in tmp_dict:
sum_in = string.atof(tmp_dict[vector_list[0]])
else:
sum_in = 0.0
else:
for j in xrange(0,len(vector_list)):
link_list = edge_dict[vector_list[j]]
tmp_dict = {}
for link_mem in link_list:
l = link_mem.strip().split(":")
#split the vector and weight
tmp_dict[l[0]] = l[1]
for k in xrange(0, len(vector_list)):
if vector_list[k] in tmp_dict:
sum_in += string.atof(tmp_dict[vector_list[k]])
#cal degree
for vec in vector_list:
link_list = edge_dict[vec]
for i in link_list:
l = i.strip().split(":")
sum_tot += string.atof(l[1])
Q += ((sum_in / m) - (sum_tot/m)*(sum_tot/m))
return Q
def chage_community(vector_dict, edge_dict, Q):
vector_tmp_dict = {}
for key in vector_dict:
vector_tmp_dict[key] = vector_dict[key]
#for every vector chose it's neighbor
for key in vector_tmp_dict.keys():
neighbor_vector_list = edge_dict[key]
for vec in neighbor_vector_list:
ori_com = vector_tmp_dict[key]
vec_v = vec.strip().split(":")
#compare the list_member with ori_com
if ori_com != vector_tmp_dict[vec_v[0]]:
vector_tmp_dict[key] = vector_tmp_dict[vec_v[0]]
Q_new = modularity(vector_tmp_dict, edge_dict)
#print Q_new
if (Q_new - Q) > 0:
Q = Q_new
else:
vector_tmp_dict[key] = ori_com
return vector_tmp_dict, Q
def modify_community(vector_dict):
#modify the community
community_dict = {}
community_num = 0
for community_values in vector_dict.values():
if community_values not in community_dict:
community_dict[community_values] = community_num
community_num += 1
for key in vector_dict.keys():
vector_dict[key] = community_dict[vector_dict[key]]
return community_num
def rebuild_graph(vector_dict, edge_dict, community_num):
vector_new_dict = {}
edge_new_dict = {}
# cal the inner connection in every community
community_dict = {}
for key in vector_dict.keys():
if vector_dict[key] not in community_dict:
community_list = []
else:
community_list = community_dict[vector_dict[key]]
community_list.append(key)
community_dict[vector_dict[key]] = community_list
# cal vector_new_dict
for key in community_dict.keys():
vector_new_dict[str(key)] = str(key)
# put the community_list into vector_new_dict
#cal inner link num
innerLink_dict = {}
for i in community_dict.keys():
sum_in = 0.0
#vector num
vector_list = community_dict[i]
#two loop cal inner link
if len(vector_list) == 1:
sum_in = 0.0
else:
for j in xrange(0,len(vector_list)):
link_list = edge_dict[vector_list[j]]
tmp_dict = {}
for link_mem in link_list:
l = link_mem.strip().split(":")
#split the vector and weight
tmp_dict[l[0]] = l[1]
for k in xrange(0, len(vector_list)):
if vector_list[k] in tmp_dict:
sum_in += string.atof(tmp_dict[vector_list[k]])
inner_list = []
inner_list.append(str(i) + ":" + str(sum_in))
edge_new_dict[str(i)] = inner_list
#cal outer link num
community_list = community_dict.keys()
for i in xrange(len(community_list)):
for j in xrange(len(community_list)):
if i != j:
sum_outer = 0.0
member_list_1 = community_dict[community_list[i]]
member_list_2 = community_dict[community_list[j]]
for i_1 in xrange(len(member_list_1)):
tmp_dict = {}
tmp_list = edge_dict[member_list_1[i_1]]
for k in xrange(len(tmp_list)):
tmp = tmp_list[k].strip().split(":");
tmp_dict[tmp[0]] = tmp[1]
for j_1 in xrange(len(member_list_2)):
if member_list_2[j_1] in tmp_dict:
sum_outer += string.atof(tmp_dict[member_list_2[j_1]])
if sum_outer != 0:
inner_list = edge_new_dict[str(community_list[i])]
inner_list.append(str(j) + ":" + str(sum_outer))
edge_new_dict[str(community_list[i])] = inner_list
return vector_new_dict, edge_new_dict, community_dict
def fast_unfolding(vector_dict, edge_dict):
#1. initilization:put every vector into different communities
# the easiest way:use the vector num as the community num
for i in vector_dict.keys():
vector_dict[i] = i
#print "vector_dict : ", vector_dict
#print "edge_dict : ", edge_dict
Q = modularity(vector_dict, edge_dict)
#2. for every vector, chose the community
Q_new = 0.0
while (Q_new != Q):
Q_new = Q
vector_dict, Q = chage_community(vector_dict, edge_dict, Q)
community_num = modify_community(vector_dict)
print "Q = ", Q
print "vector_dict.key : ", vector_dict.keys()
print "vector_dict.value : ", vector_dict.values()
Q_best = Q
while (True):
#3. rebulid new graph, re_run the second step
print "edge_dict : ",edge_dict
print "vector_dict : ",vector_dict
print "\n rebuild"
vector_dict, edge_new_dict, community_dict = rebuild_graph(vector_dict, edge_dict, community_num)
#print vector_dict
print "community_dict : ", community_dict
Q_new = 0.0
while (Q_new != Q):
Q_new = Q
vector_dict, Q = chage_community(vector_dict, edge_new_dict, Q)
community_num = modify_community(vector_dict)
print "Q = ", Q
if (Q_best == Q):
break
Q_best = Q
vector_result = {}
for key in community_dict.keys():
value_of_vector = community_dict[key]
for i in xrange(len(value_of_vector)):
vector_result[value_of_vector[i]] = str(vector_dict[str(key)])
for key in vector_result.keys():
vector_dict[key] = vector_result[key]
print "vector_dict.key : ", vector_dict.keys()
print "vector_dict.value : ", vector_dict.values()
#get the final result
vector_result = {}
for key in community_dict.keys():
value_of_vector = community_dict[key]
for i in xrange(len(value_of_vector)):
vector_result[value_of_vector[i]] = str(vector_dict[str(key)])
for key in vector_result.keys():
vector_dict[key] = vector_result[key]
print "Q_best : ", Q_best
print "vector_result.key : ", vector_dict.keys()
print "vector_result.value : ", vector_dict.values()
if __name__ == "__main__":
vector_dict, edge_dict=loadData("./cd_data.txt")
fast_unfolding(vector_dict, edge_dict)
参考文献
- Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, Etienne Lefebvre, Fast unfolding of communities in large networks, in Journal of Statistical Mechanics: Theory and Experiment 2008 (10), P1000
- 社区发现算法FastUnfolding的GraphX实现 http://www.tuicool.com/articles/Jrieue