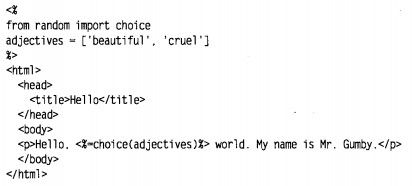
python学习第十五章——python和万维网
1.屏幕抓取:可以使用urllib获取网页的HTML源代码,然后使用正则表达式提取信息即可。下面是一个例子:

2.Tidy:Tidy是用来修复不规范且随意的HTML的工具,会确保文件的格式是正确的(也就是所有元素都正确嵌套),这样解析的时候就比较方便了。Tidy库的获取和安装是比较简单的,这里就不讲了。
现在假设有个叫做messy.html的混乱的HTML文件,下面的程序会对该文件运行Tidy,然后打印结果:

3.使用HTMLParser:上面获得了格式良好的XHTML代码之后,我们就可以使用标准库模块HTMLParser进行解析了。我们只需继承HTMLParser并且对handle_starttage或handle_data等事件处理方法进行覆盖。下图总结了一些相关的方法,以及解析器在何时对它们进行自动调用。
下面的这段代码是使用HTMLParser模块获取网页:
4.Beautiful Soup:下载BeautifulSoup.py文件,将它放置在python路径中(比如python安装文件夹里面的site-packages目录)。下面的例子是使用它进行屏幕抓取的程序:

第一步:CGI程序应该放在通过网络可以访问的目录中,并且必须将它们标识为CGI脚本,方法有两种:将脚本放在叫做cgi-bin的子目录中;把脚本文件扩展名改为.cgi。
第二步:加入pound bang行:当把脚本放在正确位置后,需要在脚本的开始处增加pound bang行。即只要将#!/usr/bin/env pthon加到脚本开始处就可以了。在windows中,需要使用#!c:\python22\python.exe。
第三步:设置文件许可:chmod 755 somescript.cgi,这样就可以将脚本作为网页打开了,并且执行。一般来说不允许CGI脚本修改计算机上的任何文件,如果想要它修改文件,必须显式地给它设置相应的许可。这时有两个选择,如果有root权限的话,可以为你的脚本创建一个用户账户,改变需要修改的文件的所有权。如果没有root全选,则可以为文件设置文件许可,这样系统上的所有用户都被允许写文件。chmod 666 editable_file.txt。
6.简单的CGI脚本:例子如下:

7.使用cgitb调试:只需要在#!/usr/bin/env pthon后面加入import cgitb:cgitb.enable()这行即可,当cgi脚本有程序错误的时候,在网页上就会显示详细的错误信息。
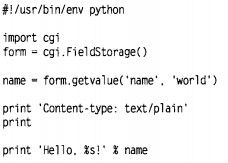
8.使用cgi模块:我们通常需要脚本接收任何形式的输入。输入是通过HTML表单提供给CGI脚本的键值对或称字段。可以使用cgi模块的FieldStorage类从CGI脚本中获取这些字段。当创建FieldStorage实例时(应该只创建一个),它会从请求中获取输入变量(或者字段),然后通过类字典借口将它们提供给程序。FieldStorage的值可以通过普通的键查找方式访问。获取值的简单方式就是用getvalue()方法,它类似于字典的get方法,但它会返回项目的value特性的值。如:form=cgi.FieldStorage();name=form.getvalue('name','unknow')这里我提供了一个默认值,如果不提供的话,就会将None作为默认值使用,默认值用于字段没有值的情况。下面是一个完整的简单例子:
9.创建表单:如下:

10.mod_python:安装,在unix上首先下载mod_python的源代码,然后解压缩,进入目录。接着运行mod_python的configure脚本:./configure --with-apxs=/usr/local/apache/bin/apxs,如果apxs不在这个位置,需要修改apxs程序的路径。然后编译所有的文件:make。接着就是安装了:make install。在windows上可以在http://www.apache.org/dist/httpd/modpython/win上下载,然后双击运行即可。配置apache:找到为特定模块使用的apache配置文件,文件通常叫做httpd.conf或者apache.conf,在unix中增加LoadModule python_module lobexec/mod_python.so,在windows中增加LoadModule python_module modules/mod_python.so。现在apache指导到哪里找mod_python了,但是还是不能使用:得告诉它什么时候去找。必须在apache的配置文件中增加几行代码,可以在主配置文件中(可能是commonapache2.conf)或者放在名为.htaccess的文件中,该文件所在目录中有用于web访问的脚本。下面假设使用.htaccess文件,如果有的话,可以像下面这样将指令打包:
如果要使用CGI处理程序,要将下面的代码放在放置CGI脚本所在目录中的.htaccess文件内:
![]()
如果需要支持PSP页面需要加上如下代码:
![]()
下面是一个带有少量随机数据的PSP例子: