iOS开发-解析Html-TFHpple
使用Objective-C解析HTML或者XML,系统自带有两种方式一个是通过libxml,一个是通过NSXMLParser。 libxml性能较好,且可以结合urlconnection实现边下载边解析,在要求快速 、分批响应UI到情况下较为有用,NSXMLParser基本没什么优势,不如使用第三方工具。
TFHpple,它是一个轻量级的包装框架,可以很好的解决这个问题,尤其是它支持HTML的解析,是其他XML类库所不及的地方,它是用XPath来定位和解析HTML或者XML。
使用步骤:
1。 -加入 libxml2 到你的项目中
到Project设置中,选all,找到Search paths下面的
Header Search Paths项目
添加新的 search path “${SDKROOT}/usr/include/libxml2″
注意选择 Enable recursive option
2. -加入 libxml2 library 到你的项目
到Target中,选择Build Phases页
在Link Binary With Libraries中
从列表中选择libxml2.dylib
3. 到https://github.com/topfunky/hpple 下载ZIP包
-将下面hpple的源代码加入到你的项目中:
HTFpple.h
HTFpple.m
HTFppleElement.h
HTFppleElement.m
XPathQuery.h
XPathQuery.m
4. xpath 权威教程 http://www.w3school.com.cn/xpath/index.asp
5. 简单例子:
解析标题
- 1.#import "TFHpple.h"
- 2.
- 3.NSData *data = [[NSData alloc] initWithContentsOfFile:@"_www.baidu.com"];
- 4.
- 5.// Create parser
- 6.xpathParser = [[TFHpple alloc] initWithHTMLData:data];
- 7.
- 8.//Get all the cells of the 2nd row of the 3rd table
- 9.NSArray *elements = [xpathParser search:@"//title"];
- 10.
- 11.// Access the first cell
- 12.TFHppleElement *element = [elements objectAtIndex:0];
- 13.
- 14.// Get the text within the cell tag
- 15.NSString *content = [element content];
- 16.
- 17.[xpathParser release];
- 18.[data release]
调用方法.给定参数

解析图片例子的网址(不明白参数的可以自己去看看页面元素)
http://www.lomowo.com/posts/47689
下面是所截取HTML的范围
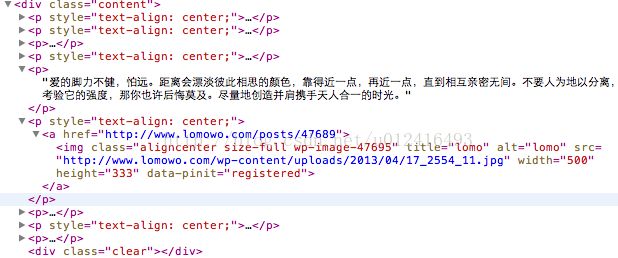
最后我们返回的数组就是 Src 中的图片网址
![]()
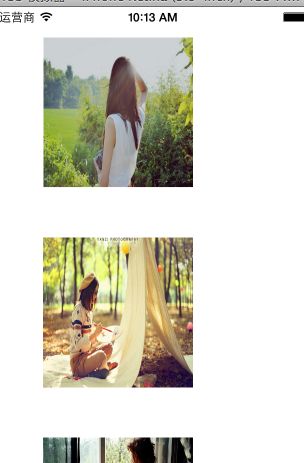
在页面上简单的显示 --(返回的imageArray数组里面 存的就是范围里面所有图片的网址.)
如有不是明白的欢迎留言 ,我会第一时间替你解答,谢谢(我也是才学)