Spark源码分析(二)RDD
前言
前段时间写了第一篇博客,回头想了想,补充一些东西:
1、我的Spark版本是1.0.2的
2、以后一个星期至少一篇博客,还请大家多多支持
3、因为都是自己的一些拙见,有些问题还请大家指出,我会及时回复
谢谢!!!
关于RDD,有一篇论文,大家可以参考下《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》
中文版本的连接:http://shiyanjun.cn/archives/744.html
什么是RDD
RDD是弹性分布式数据集,其实RDD只是一个标记,也可以称做meta。一个RDD的生成只有两种途径,一是来自于内存集合和外部存储系统,另一种是通过转换操作来自于其他RDD,比如map、filter、reducebykey等等。
RDD一共有5个特征,分别对应5个函数:
1、partions():一个RDD会有一个或者多个分区
2、preferredLocation(p):对于分区p而言,返回数据本地化计算的节点
3、dependencies():RDD之间的依赖关系
4、compute():这个函数是用户编写的,计算每一个分区
5、partitioner():RDD的分区函数
下面介绍每一个函数
RDD分区 partitons()
final def partitions: Array[Partition] = {
checkpointRDD.map(_.partitions).getOrElse {
if (partitions_ == null) {
partitions_ = getPartitions
}
partitions_
}
}
注意会调用checkpointRDD,如果该RDD checkpoint过,则调用CheckpointRDD.partitions(后面还会详细讲解),否则调用该RDD的getPartitions方法,不同的RDD会实现不同的getPartitions方法
对于一个RDD而言,分区的多少涉及对这个RDD进行并行计算的粒度,每一个RDD分区的计算操作都在一个单独的任务中被执行
RDD优先位置 preferredLocation
final def preferredLocations(split: Partition): Seq[String] = {
checkpointRDD.map(_.getPreferredLocations(split)).getOrElse {
getPreferredLocations(split)
}
}
也会优先在checkpointRDD查找,如果没有就调用该RDD的getPreferredLocations方法这个方法是在DAGScheduler.subMissingTasks会调用,会一直找到第一个RDD,返回数据本地化的节点
RDD依赖关系 dependencies
final def dependencies: Seq[Dependency[_]] = {
checkpointRDD.map(r => List(new OneToOneDependency(r))).getOrElse {
if (dependencies_ == null) {
dependencies_ = getDependencies
}
dependencies_
}
}
和上面一样,也会先在checkpointRDD中查找是否有依赖,deps是在创建RDD实例传入的,其实deps存放的就是依赖的RDD
由于RDD是粗粒度的操作数据集,每一个转换操作都会生成一个新的RDD,所以RDD之间就会形成类似于流水线(一个Stage内,pipeline)一样的前后依赖关系,在Spark中存在两种类型的依赖,即窄依赖和宽依赖,如下图所示
- 窄依赖:每一个父RDD的分区最多只被子RDD的一个分区所用
- 宽依赖:多个子RDD的分区会依赖于同一个父RDD的分区
在图中,一个大矩形表示一个RDD,在大矩形中的小矩形表示这个RDD的一个分区
在Spark中要明确地区分这两种依赖关系有两个方面的原因:
第一,对于窄依赖中所有的RDD而言(一个Stage中),可以在集群的一个节点上如流水线(pipeline)一般地执行,从而加快执行速度,宽依赖类似于MapReduce一样的shuffle操作;
第二,解决数据容错,如果一个节点死机了,而且运算窄依赖,则只要把丢失的父RDD分区重算即可,不依赖于其他节点,而宽依赖需要父RDD的所有分区都存在,重算就很昂贵了;
第三,在调度中作为不同Stage的划分点
RDD分区计算compute()
def compute(split: Partition, context: TaskContext): Iterator[T]对于Spark中每个RDD的计算都是以partition为单位,compute函数会使用用户编写好的程序,最终返回相应分区数据的迭代器
有两种生成迭代器的方式:
1、firstParent[T].iterator(split, context).map(f),即父RDD的Iterator的next方法会调用f进行相应的处理。
2、f(firstParent.iterator()): 对父RDD的Iterator的hasNext和next方法进行自定义处理, 即f会调用Iterator的hasNext和next方法即对整个分区进行操作
很重要的一点,这种compute是复合式的,它会一直找到这个stage中的第一个RDD.iterator执行,也就是所谓的pipeline
RDD分区类partitioner
partitioner这个属性只存在于(K,V)类型的RDD中,对于非(K,V)类型的partitioner的值就是None。
partitioner属性既决定了RDD本身的分区数量,也可以作为其父RDD shuffle输出中每个分区进行数据切割的依据
RDD之间的转换
典型的Job逻辑执行图如下图所示
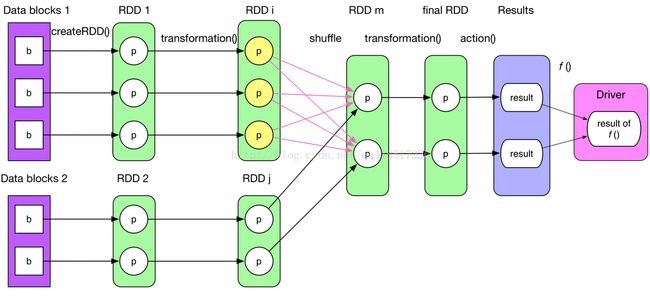
下面用一个实例讲解,基本涵盖RDD中的所有操作
val hdfsFile = sc.textFile(args(1))
val flatMapRdd = hdfsFile.flatMap(s => s.split(" "))
val filterRdd = flatMapRdd.filter(_.length == 2)
val mapRdd = filterRdd.map(word => (word, 1))
val reduce = mapRdd.reduceByKey(_ + _)
reduce.cache()
reduce.saveAsTextFile(hdfs://...)
第一行属于创建操作:从存储系统HDFS、HBase等读入数据,转换成HadoopRDD
第二、三、四行属于转换操作:最后转换成MappedRDD
第五行比较特别也属于转换操作,前面的转换操作比较简单,这个比较复杂,会产生shuffle,同时因为在RDD类中没有该函数,它采用了隐式转换,源码在SparkContext中实例化了PairRDDFunctions,然后我们写代码时引用SparkContext._,就能使用PairRDDFunctions里面的方法
第六行属于控制操作:该方法最终调用了persisit方法,该方法主要是控制变量storageLevel,默认是None,会影响RDD.iterator,是从BlockManager读取缓存还是重新计算;控制操作还有checkpoint()方法,后面的章节还会详细讲解
第七行属于行动操作:将计算结果存储到存储系统或者返回给Driver,还会触发作业的真正提交(延迟执行lazy)
由于篇幅的原因的,在这里主要讲解reduceBykey(_+_),其余RDD的用法都能网上搜到
reduceBykey(_+_)最终会调用以下函数:
def combineByKey[C](createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K, C)] = {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
if (keyClass.isArray) {
if (mapSideCombine) {
throw new SparkException("Cannot use map-side combining with array keys.")
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw new SparkException("Default partitioner cannot partition array keys.")
}
}
val aggregator = new Aggregator[K, V, C](createCombiner, mergeValue, mergeCombiners)
if (self.partitioner == Some(partitioner)) {
self.mapPartitionsWithContext((context, iter) => {
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else if (mapSideCombine) {
val combined = self.mapPartitionsWithContext((context, iter) => {
aggregator.combineValuesByKey(iter, context)
}, preservesPartitioning = true)//先在partition内部做mapSideCombine,返回一个MapPartitionsRDD
val partitioned = new ShuffledRDD[K, C, (K, C)](combined, partitioner)
.setSerializer(serializer)//ShuffledRDD,进行shuffle
partitioned.mapPartitionsWithContext((context, iter) => {
new InterruptibleIterator(context, aggregator.combineCombinersByKey(iter, context))
}, preservesPartitioning = true)//shuffle完成后,在reduce端在做一次combine,返回一个MapPartitionsRDD
} else {
// Don't apply map-side combiner.
val values = new ShuffledRDD[K, V, (K, V)](self, partitioner).setSerializer(serializer)
values.mapPartitionsWithContext((context, iter) => {
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
}
}
combine是这样的操作, Turns an RDD[(K, V)] into a result of type RDD[(K, C)]
其中C有可能只是简单类型, 但经常是seq, 比如(Int, Int) to (Int, Seq[Int])
combineByKey函数一般需要传入5个典型参数,说明如下
其中C有可能只是简单类型, 但经常是seq, 比如(Int, Int) to (Int, Seq[Int])
- createCombiner: V => C, C不存在的情况下, 比如通过V创建seq C
- mergeValue: (C, V) => C, 当C已经存在的情况下, 需要merge, 比如把item V加到seq C中, 或者叠加
- mergeCombiners: (C, C) => C, 合并两个C
- partitioner: 分区函数, Shuffle时需要的Partitioner
- mapSideCombine: Boolean = true, 为了减小传输量, 很多combine可以在map端先做, 比如叠加, 可以先在一个partition中把所有相同的key的value叠加, 再shuffle
ShuffledRDD
class ShuffledRDD[K, V, P <: Product2[K, V] : ClassTag](
@transient var prev: RDD[P],
part: Partitioner)
extends RDD[P](prev.context, Nil) {
private var serializer: Serializer = null
def setSerializer(serializer: Serializer): ShuffledRDD[K, V, P] = {
this.serializer = serializer
this
}
override def getDependencies: Seq[Dependency[_]] = {
List(new ShuffleDependency(prev, part, serializer))
}
override val partitioner = Some(part)
override def getPartitions: Array[Partition] = {
Array.tabulate[Partition](part.numPartitions)(i => new ShuffledRDDPartition(i))
}
override def compute(split: Partition, context: TaskContext): Iterator[P] = {
val shuffledId = dependencies.head.asInstanceOf[ShuffleDependency[K, V]].shuffleId
val ser = Serializer.getSerializer(serializer)
SparkEnv.get.shuffleFetcher.fetch[P](shuffledId, split.index, context, ser)
}
override def clearDependencies() {
super.clearDependencies()
prev = null
}
}
compute函数中主要是Shuffle Read,它由shuffleFetcher完成
因为每个shuffle是有一个全局的shuffleid的,所以在compute里面, 你只是看到用BlockStoreShuffleFetcher根据shuffleid和partitionid直接fetch到shuffle过后的数据
补充一点:Spark内部生成的RDD对象数量一般多于用户书写的Spark应用程序中包含的RDD,其根本原因是Spark的一些操作与RDD不是一一对应的,上面的combineByKey就是一个例子
<原创,转载请注明出处http://blog.csdn.net/qq418517226/article/details/42711067>