详解如何用 SPSS + BigInsights 共同构架大数据分析平台

相关背景及概念介绍
IBM SPSS Modeler(以下简称 Modeler)是一款数据挖掘分析的行业软件,其采用数据流的方式来展示数据挖掘的操作过程,并结合 CRISP-DM 工业标准打造了一个支持众多数据挖掘操作的应用平台。
IBM SPSS Analytic Server是大数据分析的解决方案,它提供了一个易于实现的框架,从而能够在分布式文件系统上来执行大数据分析。它将 IBM SPSS 现有的商业分析技术与大数据技术相结合,使得用户能够使用复杂的分析算法以高可伸缩的方式来解决基于大数据的分析问题。
IBM InfoSphere BigInsights是IBM基于开源Hadoop框架开发的企业级大数据平台,即集成了Hadoop生态系统中众多主流的开源组件,例如HDFS、MapReduce、YARN、Spark、HIVE、HBASE等,也为企业客户开发了众多实用的数据处理和分析组件,例如可视化数据探索组件BigSheets、大数据SQL访问引擎BigSQL、商业数据分析组件BigR等,帮助企业客户更快更便捷的搭建自己的核心大数据平台,并将数据转化为商业价值。
安装配置
安装环境
硬件:3台HP X86服务器,24核,64GB内存,8*1TB硬盘
操作系统:Redhat 6.5
软件:
BigInsigtsV4.1( IOP + Data Analytics)
SPSS AS 2.1
SPSS Modeler Server 17.1
SPSS Modeler Client 17.1
SPSS AS 2.1和Big Insights 4.1的安装概述
SPSS AS 2.1和Big Insights 4.1的安装是通过Ambari平台配置,Ambari 跟 Hadoop 等开源软件一样,也是 Apache Software Foundation 中的一个项目,并且是顶级项目。目前最新的发布版本是 2.0.1,未来不久将发布 2.1 版本。就 Ambari 的作用来说,就是创建、管理、监视Hadoop 的集群,但是这里的 Hadoop 是广义,指的是 Hadoop 整个生态圈(例如Hive,Hbase,Sqoop,Zookeeper 等),而并不仅是特指Hadoop。用一句话来说,Ambari 就是为了让 Hadoop 以及相关的大数据软件更容易使用的一个工具。
SPSS AS 2.1具体安装步骤
1.SPSS AS 2.1的安装文件准备: 将IBM-SPSS-AnalyticServer-2.1.0.0-1.x86_64.rpm 和IBM-SPSS-AnalyticServer-ambari-2.1-BI-4.1-2.1.0.0-1.x86_64.rpm 放到以下路径:/home/root/repos/IBM-SPSS-AnalyticServer/x86_64
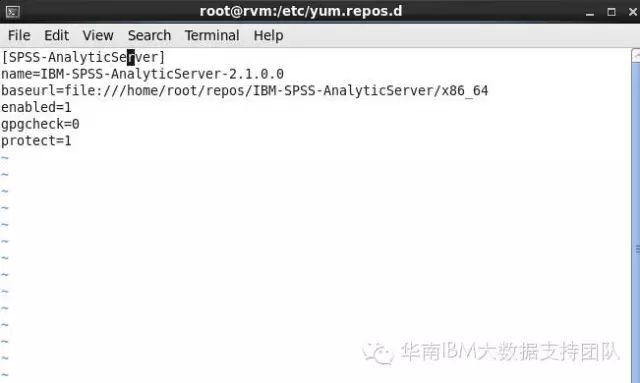
2.创建本地存储库定义,例如在 /etc/yum.repos.d/ 中创建名为 analyticserver.repo(对于RHEL、CentOS)或者创建包含以下内容的 /etc/zypp/repos.d/(对于SLES)。 下图是RHEL环境下内容:
[IBM-SPSS-AnalyticServer]
name=IBM-SPSS-AnalyticServer-2.1.0.0
baseurl=file:///home/root/repos/IBM-SPSS-AnalyticServer/x86_64
enabled=1
gpgcheck=0
protect=1
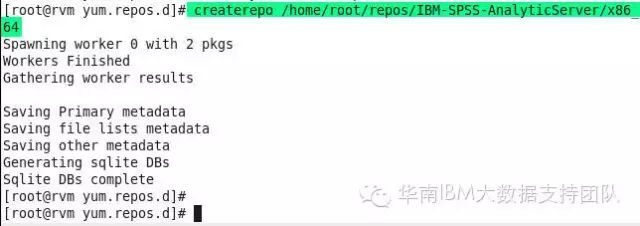
3.创建本地Yum存储库
createrepo/home/root/repos/IBM-SPSS-AnalyticServer/x86_64
4. 安装本地存储库中的Ambari元数据RPM,这是具有格式IBM-SPSS-AnalyticServer-ambarixxx.rpm的文件,在Redhat中执行
sudo yuminstall IBM-SPSS-AnalyticServer-ambari-2.1-BI-4.1
5.找到/var/lib/ambari-server/resources/stacks/BigInsights/4.1/repos/中的repoinfo.xml文件,添加以下内容:
<repo>
<baseurl>file://home/root/repos/IBM-SPSS-AnalyticServer/x86_64</baseurl>
<repoid>IBM-SPSS-AnalyticServer</repoid>
<reponame>IBM-SPSS-AnalyticServer-2.1.0.0</reponame>
</repo>
</os>
6.重启ambari服务器
ambari-serverrestart
7.验证链接http://rvm.svl.ibm.com:8080
PS:其中rvm.svl.ibm.com是Ambari所在的安装机器名

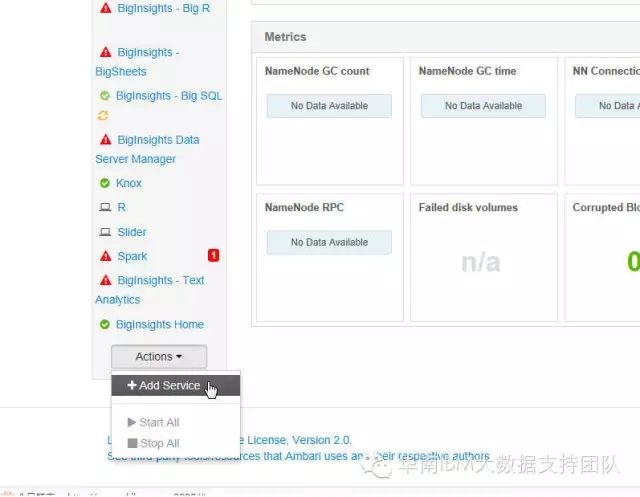
8.进入Ambari UI界面添加服务:
在左下角Action-->Add Services
9.选择SPSS Analytics Server, 设置AS用户名密码 admin/admin (用户名密码可自己设置)
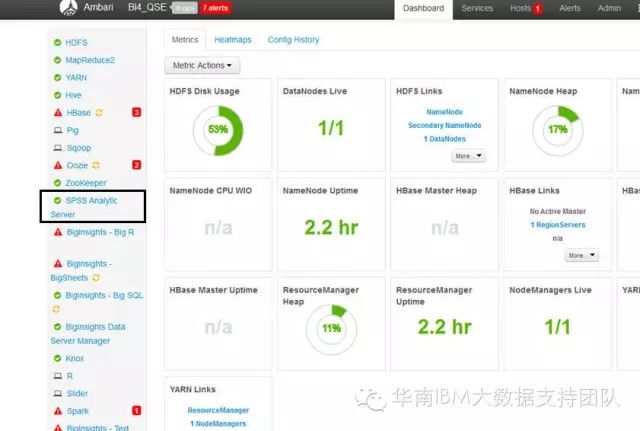
10.成功安装后,正常启动,可看到SPSS Analytic Server在左边的服务项目中,如下图:
11.验证AS是否成功安装的链接
http://rvm.svl.ibm.com:9080/analyticserver/admin/ibm
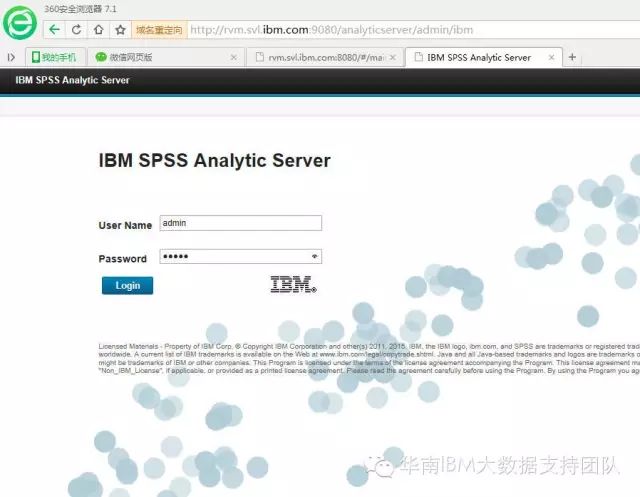
登陆后进入以下页面

12.选择Data Sources, 可以选择的数据类型包括以下几种:
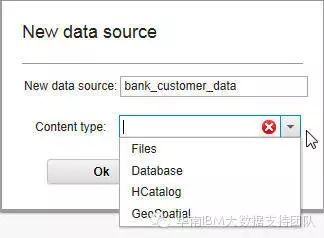
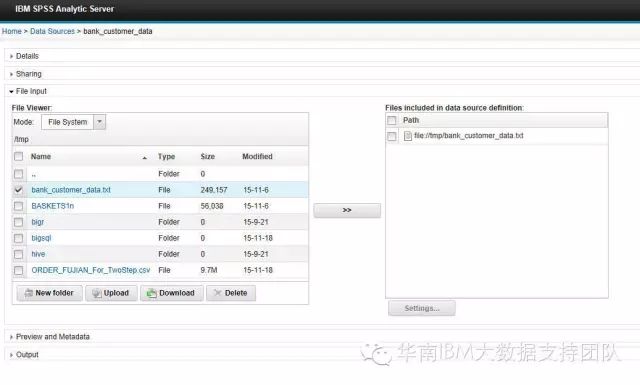
比如这里选择File,在Mode中选择File System,则可看到HDFS上相应的文件夹及文件,直接选择需要的文件,箭头转到右边的对话框中后,保存即可。
SPSS Modeler Server 连接SPSS AS配置
找到SPSS Modeler Server安装路径下的C:\Program Files\IBM\SPSS\ModelerServer\17.1\config的option.cfg,设置以下参数:
as_ssl_enabled, N
as_host, "rvm.svl.ibm.com" -----AS服务器名
as_port, 9080 -----AS端口号
as_context_root, "analyticserver"
as_tenant, "ibm"
as_prompt_for_password, Y -----是否需要密码提示,需要设置成Y
SPSS Modeler Server 连接Big Insight数据源实现基于Spark内在计算算法的运算示例
1.打开SPSS Modeler Client,先连接SPSS ModelerServer

2.数据分析流如下图:

(1)选择数据源AS,双击编辑选择前面在AS Portal页面已经配置好的源文件 bank_customer_data
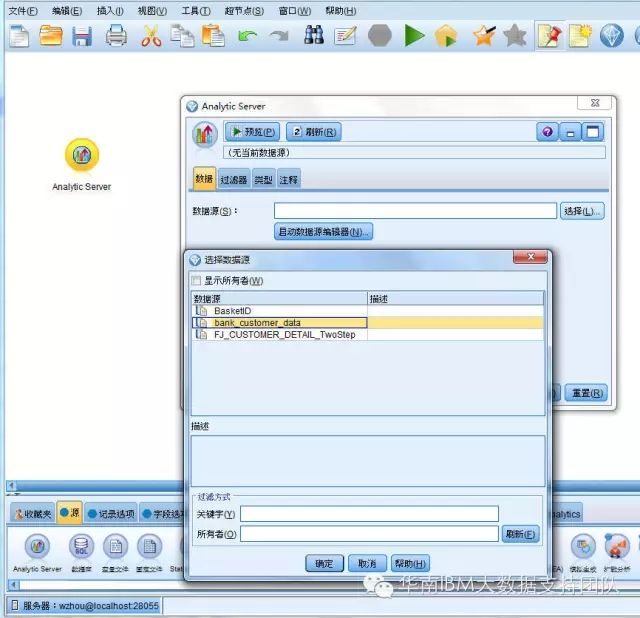
(2).通过类型节点设置输入因素
(3).选择支持分布式算法的TwoStep_AS
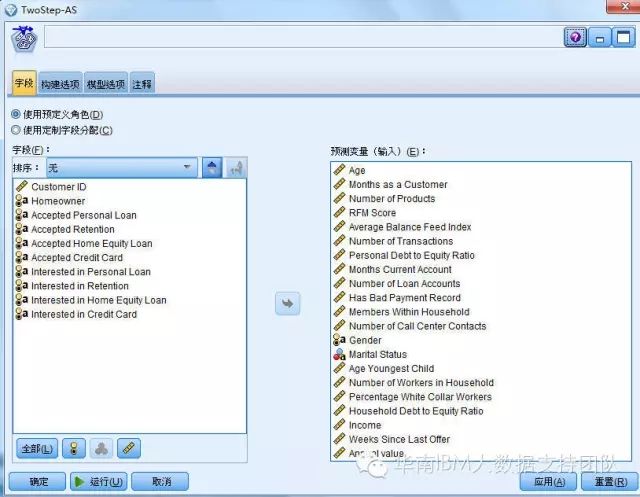
(4).运行后得到聚类分析模型
(5).聚类分析结果导出成文件文件存放到BigInsights Hadoop平台上。
后台查看任务可以聚类算法的分析已转为Spark任务的运行状态

最后、这里给感兴趣的朋友提供一个软件下载链接:http://bigdata.evget.com/product/168.html;大家可以亲自动手尝试一下!