Giraph源码分析(三)—— 消息通信
本人原创,转载请注明出处! 本人QQ:530422429,欢迎大家指正、讨论。
1. 由前文知道每个BSPServiceWorker有一个WorkerServer对象,WorkerServer对象里面又有ServerData对象,作为数据实体。ServerData中包含该Worker的partitionStore、edgeStore、incomingMessageStore、currentMessageStore、聚集值等。
其中incomingMessageStore对象为MessageStoreByPartition(接口)类型,也就是说消息时按照分区来存储的。MessageStoreByPartition接口的关系图如下:
如果用户的程序使用Combiner, incomingMessageStore对象实际为OneMessagePerVertexStore ;否则incomingMessageStore对象为ByteArrayMessagesPerVertexStore类型。
下面先分析ByteArrayMessagesPerVertexStore类型。对同一个vertex的multiple消息存储为一个byte arrays。
在SimpleMessageStore抽象类中,有一个ConcurrentMap<Integer,ConcurrentMap<I,T>>类型的变量map,用来存储消息。第一层是pairtitionID到发送到该partition消息的映射;第二层是VertexID 到发送给该Vertex的消息队列。下图参考《Giraph通信模块分析》:http://my.oschina.net/skyaugust/blog/95182 。在此表示感谢!
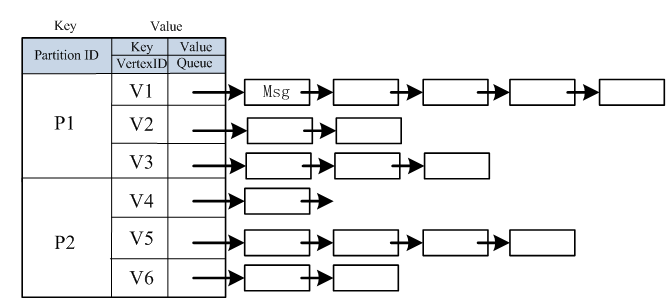
每个顶点的消息列表具体为ExtendedDataOutput类型,它继承DataOutput接口,增加了几个方法而已。每个消息是以字节形式写入到ExtendedDataOutput对象中的。
2. 发送消息时,采用异步式通信。图顶点的计算处理与消息通信并发执行,在计算过程中就可以发送消息,将大规模消息发送分散在不同的时间段,避免瞬时网络通信阻塞,但是接受端需要额外的空间,存储临时接收到的消息,相当于空间换时间。而集中式通信,图顶点的计算处理与消息通信串行进行,在计算完毕后,统一发送消息,控制和实现方式简单,可在发送端对消息进行最大程度优化,但容易造成瞬时间的网络通信阻塞以及增加发送端的消息存储开销。
不同Worker间的消息通信使用RPC方式,具体为Netty。同一Worker内,连续两次迭代的消息直接通过内存操作,把要发送的消息直接复制到Worker的incomingMessageStore中。下面详述消息的存储格式和发送机制。
3. Giraph使用Cache来缓存消息,当消息达到一定阈值后,一次性发送。既按照bulk模式进行,不会一条一条信息发送。向某个顶点发送的消息是按照<destVertexId,Message> pair存储在ByteArrayVertexIdData<I,T>中(实际为ByteArrayVertexIdMessages<I,M>类型)。介绍如下: org.apache.giraph.utils.ByteArrayVertexIdData<I,T>
功能:把<顶点ID,data> Pair 存储在一个 byte数组中。里面有 ExtendedDataOutput对象用来存储数据。
该类中还有一个内部类:VertexIdDataIterator,该内部类继承 VertexIdIterator类。

org.apache.giraph.comm.SendCache用来缓存发送的信息,然后以“Bulk”模式发送。在Giraph中,每个Worker上可以对应多个分区。消息缓存的阈值是以Worker为单位计算,而不是Partition。

SendCache中有ByteArrayVertexIdData<I,T>[ ] dataCache数组用来存储发送给每个Partition的消息;有int[ ] dataSizes数组用于记录向每个Worker发送的消息大小,若大于MAX_MSG_REQUEST_SIZE(默认为512KB)就把此Worker上的所有Partition缓存的消息发送到给该Worker,同一Worker内消息也是如此缓存;有int[ ] initBufferSizes数组用于记录每个Worker上的每个Partition的初始化ByteArrayVertexIdData中ExtendedDataOutput对象的大小,同一Worker上的所有Partition初始值相同,该值为平均值。记MAX_MSG_REQUEST_SIZE(message request size)值为M, 该Worker上有P个 partitions,ADDTITIONNAL_MSG_REQUEST_SIZE(比平均值大的因子)默认为0.2f,记为A。则每个Partition的初始大小为:M*(1+A) / P .
由前文知道,每个Worker都有一个NettyWorkerClientRequestProcessor<I,V,E,M>用来发送消息。该类中有SendMessageCache对象用来缓存向外发送的信息。NettyWorkerClientRequestProcessor类中的sendMessageRequest(I,M)
方法如下,用于向某个顶点destVertexId发送消息message。
@Override
public boolean sendMessageRequest(I destVertexId, M message) {
PartitionOwner owner =
serviceWorker.getVertexPartitionOwner(destVertexId);
WorkerInfo workerInfo = owner.getWorkerInfo();
final int partitionId = owner.getPartitionId();
++totalMsgsSentInSuperstep;
// Add the message to the cache
int workerMessageSize = sendMessageCache.addMessage(
workerInfo, partitionId, destVertexId, message);
// Send a request if the cache of outgoing message to
// the remote worker 'workerInfo' is full enough to be flushed
if (workerMessageSize >= maxMessagesSizePerWorker) {
PairList<Integer, ByteArrayVertexIdMessages<I, M>>
workerMessages =
sendMessageCache.removeWorkerMessages(workerInfo);
WritableRequest writableRequest =
new SendWorkerMessagesRequest<I, M>(workerMessages);
doRequest(workerInfo, writableRequest);
return true;
}
return false;
}方法解释:首先根据destVertexId得到对应的partitionId和WorkerInfo,然后把消息add到SendMessageCache中,并返回向该顶点所属Worker发送的消息大小workerMessageSize。若该值大于默认值512KB,则把此Worker对应的所有Partition消息从
SendMessageCache中删除,把删除的消息赋值给workerMessages,其类型为PairList<Integer,ByteArrayVertexIdMessages<I,M>> ,key为partitionId,value为发送给该partition的消息列表,最后调用doRequest()方法发送信息。doRequest()方法如下:
private void doRequest(WorkerInfo workerInfo,
WritableRequest writableRequest) {
// If this is local, execute locally
if (serviceWorker.getWorkerInfo().getTaskId() ==
workerInfo.getTaskId()) {
((WorkerRequest) writableRequest).doRequest(serverData);
localRequests.inc();
} else {
workerClient.sendWritableRequest(
workerInfo.getTaskId(), writableRequest);
remoteRequests.inc();
}
}
可以看到在发送消息时,先判断是否在同一Worker上。如果是的话,调用SendWorkerMessagesRequest<T,M>的doRequest发送消息;否则使用WorkerClient(底层使用Netty)进行消息发送。下面着重讨论同一Worker内的机制。
org.apache.giraph.comm.requests.SendWorkerMessagesRequest类中的doRequest方法如下:
@Override
public void doRequest(ServerData serverData) {
PairList<Integer, ByteArrayVertexIdMessages<I, M>>.Iterator
iterator = partitionVertexData.getIterator();
while (iterator.hasNext()) {
iterator.next();
try {
serverData.getIncomingMessageStore().
addPartitionMessages(iterator.getCurrentFirst(),
iterator.getCurrentSecond());
} catch (IOException e) {
throw new RuntimeException("doRequest: Got IOException ", e);
}
}
}参数为该Worker的ServerData,代码中的partitionVertexData实际为
PairList<Integer,ByteArrayVertexIdMessages<I,M>>workerMessages。 遍历<partitionID,对应的消息列表>来添加到ServerData中的
incomingMessageStore中。ByteArrayMessagesPerVertexStore类中的addPartitionMessages()方法如下:
@Override
public void addPartitionMessages(
int partitionId,
ByteArrayVertexIdMessages<I, M> messages) throws IOException {
ConcurrentMap<I, ExtendedDataOutput> partitionMap =
getOrCreatePartitionMap(partitionId);
……
ByteArrayVertexIdMessages<I, M>.VertexIdMessageIterator
vertexIdMessageIterator = messages.getVertexIdMessageIterator();
// 遍历<destVertexId,Msg> Pair
while (vertexIdMessageIterator.hasNext()) {
vertexIdMessageIterator.next();
// 找到顶点对应的队列,不存在则新建
ExtendedDataOutput extendedDataOutput =
getExtendedDataOutput(partitionMap, vertexIdMessageIterator);
synchronized (extendedDataOutput) {
// 把Msg添加到队列中
vertexIdMessageIterator.getCurrentMessage().write(
extendedDataOutput);
}
}
}4. 当用户使用了Combiner,
incomingMessageStore对应的类型则为OneMessagePerVertexStore,该类为每个顶点只存储一个消息,而非消息队列。结构如下图:

当添加一条消息时,会把顶点已对应的消息和要添加的消息调用combine()方法进行合并,然后存储在上述结构图中。addPartitionMessages()方法如下:
@Override
public void addPartitionMessages(
int partitionId,
ByteArrayVertexIdMessages<I, M> messages) throws IOException {
ConcurrentMap<I, M> partitionMap =
getOrCreatePartitionMap(partitionId);
ByteArrayVertexIdMessages<I, M>.VertexIdMessageIterator
vertexIdMessageIterator = messages.getVertexIdMessageIterator();
// This loop is a little complicated as it is optimized to only create
// the minimal amount of vertex id and message objects as possible.
//遍历<destVertexID,Msg> Pair
while (vertexIdMessageIterator.hasNext()) {
vertexIdMessageIterator.next();
I vertexId = vertexIdMessageIterator.getCurrentVertexId();
M currentMessage =
partitionMap.get(vertexIdMessageIterator.getCurrentVertexId());
if (currentMessage == null) {
M newMessage = combiner.createInitialMessage();
currentMessage = partitionMap.putIfAbsent(
vertexIdMessageIterator.releaseCurrentVertexId(), newMessage);
if (currentMessage == null) {
currentMessage = newMessage;
}
}
synchronized (currentMessage) {
// 调用combine()方法进行合并,并赋值给currentMessage
combiner.combine(vertexId, currentMessage,
vertexIdMessageIterator.getCurrentMessage());
}
}
}5. 在ComputeCallable中的call()方法调用computePartition(Partition)计算完所有Partition上的顶点后,调用WorkerClientRequestProcessor.flush()方法把所有剩余的消息发送出去。
@Override
public void flush() throws IOException {
……
// Execute the remaining sends messages (if any)
PairList<WorkerInfo, PairList<Integer,
ByteArrayVertexIdMessages<I, M>>>
remainingMessageCache = sendMessageCache.removeAllMessages();
PairList<WorkerInfo,
PairList<Integer, ByteArrayVertexIdMessages<I, M>>>.Iterator
iterator = remainingMessageCache.getIterator();
while (iterator.hasNext()) {
iterator.next();
WritableRequest writableRequest =
new SendWorkerMessagesRequest<I, M>(
iterator.getCurrentSecond());
doRequest(iterator.getCurrentFirst(), writableRequest);
}
……
}