TFIDF算法java实现(TF/IDF选取高频词)
一、算法简介
TF-IDF(term frequency–inverse document frequency)。TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF*IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条t在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,IDF越大,则说明词条t具有很好的类别区分能力。
二、算法实现
1》主要文件
package tfidf;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import jeasy.analysis.MMAnalyzer;
public class ReadFiles {
private static List<String> fileList = new ArrayList<String>();
private static HashMap<String, HashMap<String, Float>> allTheTf = new HashMap<String, HashMap<String, Float>>();
private static HashMap<String, HashMap<String, Integer>> allTheNormalTF = new HashMap<String, HashMap<String, Integer>>();
public static List<String> readDirs(String filepath) throws FileNotFoundException, IOException {
try {
File file = new File(filepath);
if (!file.isDirectory()) {
System.out.println("输入的参数应该为[文件夹名]");
System.out.println("filepath: " + file.getAbsolutePath());
} else if (file.isDirectory()) {
String[] filelist = file.list();
for (int i = 0; i < filelist.length; i++) {
File readfile = new File(filepath + "\\" + filelist[i]);
if (!readfile.isDirectory()) {
//System.out.println("filepath: " + readfile.getAbsolutePath());
fileList.add(readfile.getAbsolutePath());
} else if (readfile.isDirectory()) {
readDirs(filepath + "\\" + filelist[i]);
}
}
}
} catch (FileNotFoundException e) {
System.out.println(e.getMessage());
}
return fileList;
}
public static String readFiles(String file) throws FileNotFoundException, IOException {
StringBuffer sb = new StringBuffer();
InputStreamReader is = new InputStreamReader(new FileInputStream(file), "gbk");
BufferedReader br = new BufferedReader(is);
String line = br.readLine();
while (line != null) {
sb.append(line).append("\r\n");
line = br.readLine();
}
br.close();
return sb.toString();
}
public static String[] cutWord(String file) throws IOException {
String[] cutWordResult = null;
String text = ReadFiles.readFiles(file);
MMAnalyzer analyzer = new MMAnalyzer();
//System.out.println("file content: "+text);
//System.out.println("cutWordResult: "+analyzer.segment(text, " "));
String tempCutWordResult = analyzer.segment(text, " ");
cutWordResult = tempCutWordResult.split(" ");
return cutWordResult;
}
public static HashMap<String, Float> tf(String[] cutWordResult) {
HashMap<String, Float> tf = new HashMap<String, Float>();//正规化
int wordNum = cutWordResult.length;
int wordtf = 0;
for (int i = 0; i < wordNum; i++) {
wordtf = 0;
for (int j = 0; j < wordNum; j++) {
if (cutWordResult[i] != " " && i != j) {
if (cutWordResult[i].equals(cutWordResult[j])) {
cutWordResult[j] = " ";
wordtf++;
}
}
}
if (cutWordResult[i] != " ") {
tf.put(cutWordResult[i], (new Float(++wordtf)) / wordNum);
cutWordResult[i] = " ";
}
}
return tf;
}
public static HashMap<String, Integer> normalTF(String[] cutWordResult) {
HashMap<String, Integer> tfNormal = new HashMap<String, Integer>();//没有正规化
int wordNum = cutWordResult.length;
int wordtf = 0;
for (int i = 0; i < wordNum; i++) {
wordtf = 0;
if (cutWordResult[i] != " ") {
for (int j = 0; j < wordNum; j++) {
if (i != j) {
if (cutWordResult[i].equals(cutWordResult[j])) {
cutWordResult[j] = " ";
wordtf++;
}
}
}
tfNormal.put(cutWordResult[i], ++wordtf);
cutWordResult[i] = " ";
}
}
return tfNormal;
}
public static Map<String, HashMap<String, Float>> tfOfAll(String dir) throws IOException {
List<String> fileList = ReadFiles.readDirs(dir);
for (String file : fileList) {
HashMap<String, Float> dict = new HashMap<String, Float>();
dict = ReadFiles.tf(ReadFiles.cutWord(file));
allTheTf.put(file, dict);
}
return allTheTf;
}
public static Map<String, HashMap<String, Integer>> NormalTFOfAll(String dir) throws IOException {
List<String> fileList = ReadFiles.readDirs(dir);
for (int i = 0; i < fileList.size(); i++) {
HashMap<String, Integer> dict = new HashMap<String, Integer>();
dict = ReadFiles.normalTF(ReadFiles.cutWord(fileList.get(i)));
allTheNormalTF.put(fileList.get(i), dict);
}
return allTheNormalTF;
}
public static Map<String, Float> idf(String dir) throws FileNotFoundException, UnsupportedEncodingException, IOException {
//公式IDF=log((1+|D|)/|Dt|),其中|D|表示文档总数,|Dt|表示包含关键词t的文档数量。
Map<String, Float> idf = new HashMap<String, Float>();
List<String> located = new ArrayList<String>();
float Dt = 1;
float D = allTheNormalTF.size();//文档总数
List<String> key = fileList;//存储各个文档名的List
Map<String, HashMap<String, Integer>> tfInIdf = allTheNormalTF;//存储各个文档tf的Map
for (int i = 0; i < D; i++) {
HashMap<String, Integer> temp = tfInIdf.get(key.get(i));
for (String word : temp.keySet()) {
Dt = 1;
if (!(located.contains(word))) {
for (int k = 0; k < D; k++) {
if (k != i) {
HashMap<String, Integer> temp2 = tfInIdf.get(key.get(k));
if (temp2.keySet().contains(word)) {
located.add(word);
Dt = Dt + 1;
continue;
}
}
}
idf.put(word, Log.log((1 + D) / Dt, 10));
}
}
}
return idf;
}
public static Map<String, HashMap<String, Float>> tfidf(String dir) throws IOException {
Map<String, Float> idf = ReadFiles.idf(dir);
Map<String, HashMap<String, Float>> tf = ReadFiles.tfOfAll(dir);
for (String file : tf.keySet()) {
Map<String, Float> singelFile = tf.get(file);
for (String word : singelFile.keySet()) {
singelFile.put(word, (idf.get(word)) * singelFile.get(word));
}
}
return tf;
}
}
2》辅助工具类
package tfidf;
public class Log {
public static float log(float value, float base) {
return (float) (Math.log(value) / Math.log(base));
}
}3》测试类
package tfidf;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) throws IOException {
Map<String, HashMap<String, Integer>> normal = ReadFiles.NormalTFOfAll("d:/dir");
for (String filename : normal.keySet()) {
System.out.println("fileName " + filename);
System.out.println("TF " + normal.get(filename).toString());
}
System.out.println("-----------------------------------------");
Map<String, HashMap<String, Float>> notNarmal = ReadFiles.tfOfAll("d:/dir");
for (String filename : notNarmal.keySet()) {
System.out.println("fileName " + filename);
System.out.println("TF " + notNarmal.get(filename).toString());
}
System.out.println("-----------------------------------------");
Map<String, Float> idf = ReadFiles.idf("d;/dir");
for (String word : idf.keySet()) {
System.out.println("keyword :" + word + " idf: " + idf.get(word));
}
System.out.println("-----------------------------------------");
Map<String, HashMap<String, Float>> tfidf = ReadFiles.tfidf("d:/dir");
for (String filename : tfidf.keySet()) {
System.out.println("fileName " + filename);
System.out.println(tfidf.get(filename));
}
}
}
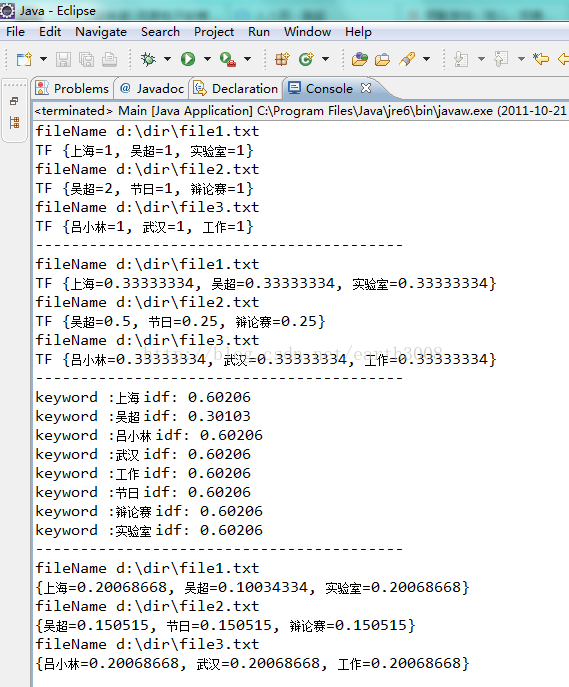
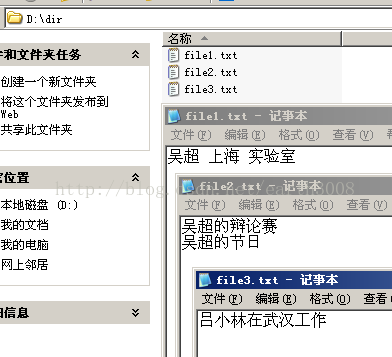
三、实验数据
四、实验结果
五、项目所需依赖
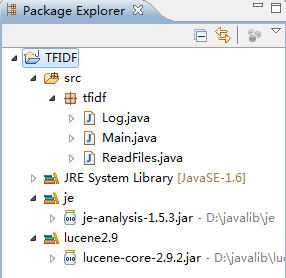
jar包下载地址:http://lvxiaolin1118.download.csdn.net/
注意jar包的版本,否则出现以下问题,请跟换如图版本的jar包。
六、常见疑问截图
1》没有加入lucene jar包
2》加入的lucene jar包版本与je分词jar包不对应
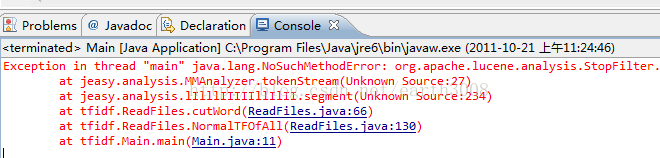
3》我自己又重新跑了一遍程序,正确的输入结果如下