机器学习算法与Python实践之(六)二分k均值聚类
在上一个博文中,我们聊到了k-means算法。但k-means算法有个比较大的缺点就是对初始k个质心点的选取比较敏感。有人提出了一个二分k均值(bisecting k-means)算法,它的出现就是为了一定情况下解决这个问题的。也就是说它对初始的k个质心的选择不太敏感。那下面我们就来了解和实现下这个算法。
一、二分k均值(bisecting k-means)算法
二分k均值(bisecting k-means)算法的主要思想是:首先将所有点作为一个簇,然后将该簇一分为二。之后选择能最大程度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇。以此进行下去,直到簇的数目等于用户给定的数目k为止。
以上隐含着一个原则是:因为聚类的误差平方和能够衡量聚类性能,该值越小表示数据点月接近于它们的质心,聚类效果就越好。所以我们就需要对误差平方和最大的簇进行再一次的划分,因为误差平方和越大,表示该簇聚类越不好,越有可能是多个簇被当成一个簇了,所以我们首先需要对这个簇进行划分。
二分k均值算法的伪代码如下:
***************************************************************
将所有数据点看成一个簇
当簇数目小于k时
对每一个簇
计算总误差
在给定的簇上面进行k-均值聚类(k=2)
计算将该簇一分为二后的总误差
选择使得误差最小的那个簇进行划分操作
***************************************************************
二、Python实现
我使用的Python是2.7.5版本的。附加的库有Numpy和Matplotlib。具体的安装和配置见前面的博文。在代码中已经有了比较详细的注释了。不知道有没有错误的地方,如果有,还望大家指正(每次的运行结果都有可能不同)。里面我写了个可视化结果的函数,但只能在二维的数据上面使用。直接贴代码:
biKmeans.py
- #################################################
- # kmeans: k-means cluster
- # Author : zouxy
- # Date : 2013-12-25
- # HomePage : http://blog.csdn.net/zouxy09
- # Email : [email protected]
- #################################################
- from numpy import *
- import time
- import matplotlib.pyplot as plt
- # calculate Euclidean distance
- def euclDistance(vector1, vector2):
- return sqrt(sum(power(vector2 - vector1, 2)))
- # init centroids with random samples
- def initCentroids(dataSet, k):
- numSamples, dim = dataSet.shape
- centroids = zeros((k, dim))
- for i in range(k):
- index = int(random.uniform(0, numSamples))
- centroids[i, :] = dataSet[index, :]
- return centroids
- # k-means cluster
- def kmeans(dataSet, k):
- numSamples = dataSet.shape[0]
- # first column stores which cluster this sample belongs to,
- # second column stores the error between this sample and its centroid
- clusterAssment = mat(zeros((numSamples, 2)))
- clusterChanged = True
- ## step 1: init centroids
- centroids = initCentroids(dataSet, k)
- while clusterChanged:
- clusterChanged = False
- ## for each sample
- for i in xrange(numSamples):
- minDist = 100000.0
- minIndex = 0
- ## for each centroid
- ## step 2: find the centroid who is closest
- for j in range(k):
- distance = euclDistance(centroids[j, :], dataSet[i, :])
- if distance < minDist:
- minDist = distance
- minIndex = j
- ## step 3: update its cluster
- if clusterAssment[i, 0] != minIndex:
- clusterChanged = True
- clusterAssment[i, :] = minIndex, minDist**2
- ## step 4: update centroids
- for j in range(k):
- pointsInCluster = dataSet[nonzero(clusterAssment[:, 0].A == j)[0]]
- centroids[j, :] = mean(pointsInCluster, axis = 0)
- print 'Congratulations, cluster using k-means complete!'
- return centroids, clusterAssment
- # bisecting k-means cluster
- def biKmeans(dataSet, k):
- numSamples = dataSet.shape[0]
- # first column stores which cluster this sample belongs to,
- # second column stores the error between this sample and its centroid
- clusterAssment = mat(zeros((numSamples, 2)))
- # step 1: the init cluster is the whole data set
- centroid = mean(dataSet, axis = 0).tolist()[0]
- centList = [centroid]
- for i in xrange(numSamples):
- clusterAssment[i, 1] = euclDistance(mat(centroid), dataSet[i, :])**2
- while len(centList) < k:
- # min sum of square error
- minSSE = 100000.0
- numCurrCluster = len(centList)
- # for each cluster
- for i in range(numCurrCluster):
- # step 2: get samples in cluster i
- pointsInCurrCluster = dataSet[nonzero(clusterAssment[:, 0].A == i)[0], :]
- # step 3: cluster it to 2 sub-clusters using k-means
- centroids, splitClusterAssment = kmeans(pointsInCurrCluster, 2)
- # step 4: calculate the sum of square error after split this cluster
- splitSSE = sum(splitClusterAssment[:, 1])
- notSplitSSE = sum(clusterAssment[nonzero(clusterAssment[:, 0].A != i)[0], 1])
- currSplitSSE = splitSSE + notSplitSSE
- # step 5: find the best split cluster which has the min sum of square error
- if currSplitSSE < minSSE:
- minSSE = currSplitSSE
- bestCentroidToSplit = i
- bestNewCentroids = centroids.copy()
- bestClusterAssment = splitClusterAssment.copy()
- # step 6: modify the cluster index for adding new cluster
- bestClusterAssment[nonzero(bestClusterAssment[:, 0].A == 1)[0], 0] = numCurrCluster
- bestClusterAssment[nonzero(bestClusterAssment[:, 0].A == 0)[0], 0] = bestCentroidToSplit
- # step 7: update and append the centroids of the new 2 sub-cluster
- centList[bestCentroidToSplit] = bestNewCentroids[0, :]
- centList.append(bestNewCentroids[1, :])
- # step 8: update the index and error of the samples whose cluster have been changed
- clusterAssment[nonzero(clusterAssment[:, 0].A == bestCentroidToSplit), :] = bestClusterAssment
- print 'Congratulations, cluster using bi-kmeans complete!'
- return mat(centList), clusterAssment
- # show your cluster only available with 2-D data
- def showCluster(dataSet, k, centroids, clusterAssment):
- numSamples, dim = dataSet.shape
- if dim != 2:
- print "Sorry! I can not draw because the dimension of your data is not 2!"
- return 1
- mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr']
- if k > len(mark):
- print "Sorry! Your k is too large! please contact Zouxy"
- return 1
- # draw all samples
- for i in xrange(numSamples):
- markIndex = int(clusterAssment[i, 0])
- plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex])
- mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb']
- # draw the centroids
- for i in range(k):
- plt.plot(centroids[i, 0], centroids[i, 1], mark[i], markersize = 12)
- plt.show()
三、测试结果
测试数据是二维的,共80个样本。有4个类。具体见上一个博文。
测试代码:
test_biKmeans.py
- #################################################
- # kmeans: k-means cluster
- # Author : zouxy
- # Date : 2013-12-25
- # HomePage : http://blog.csdn.net/zouxy09
- # Email : [email protected]
- #################################################
- from numpy import *
- import time
- import matplotlib.pyplot as plt
- ## step 1: load data
- print "step 1: load data..."
- dataSet = []
- fileIn = open('E:/Python/Machine Learning in Action/testSet.txt')
- for line in fileIn.readlines():
- lineArr = line.strip().split('\t')
- dataSet.append([float(lineArr[0]), float(lineArr[1])])
- ## step 2: clustering...
- print "step 2: clustering..."
- dataSet = mat(dataSet)
- k = 4
- centroids, clusterAssment = biKmeans(dataSet, k)
- ## step 3: show the result
- print "step 3: show the result..."
- showCluster(dataSet, k, centroids, clusterAssment)
这里贴出两次的运行结果:
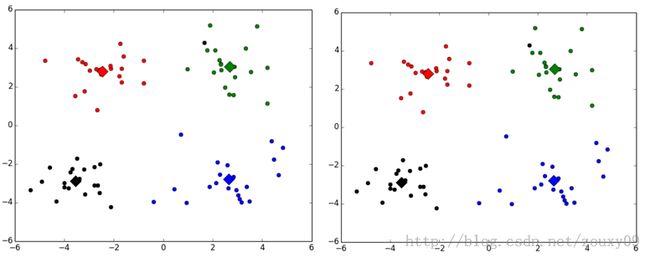
不同的类用不同的颜色来表示,其中的大菱形是对应类的均值质心点。
事实上,这个算法在初始质心选择不同时运行效果也会不同。我没有看初始的论文,不确定它究竟是不是一定会收敛到全局最小值。《机器学习实战》这本书说是可以的,但因为每次运行的结果不同,所以我有点怀疑,自己去找资料也没找到相关的说明。对这个算法有了解的还望您不吝指点下,谢谢。
区分两个概念:
hard clustering:一个文档要么属于类w,要么不属于类w,即文档对确定的类w是二值的1或0。
soft clustering:一个文档可以属于类w1,同时也可以属于w2,而且文档属于一个类的值不是0或1,可以是0.3这样的小数。
K-Means就是一种hard clustering,所谓K-means里的K就是我们要事先指定分类的个数,即K个。
k-means算法的流程如下:
1)从N个文档随机选取K个文档作为初始质心
2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至满足既定的条件,算法结束
在K-means算法里所有的文档都必须向量化,n个文档的质心可以认为是这n个向量的中心,计算方法如下:

这里加入一个方差RSS的概念:

RSSk的值是类k中每个文档到质心的距离,RSS是所有k个类的RSS值的和。
算法结束条件:
1)给定一个迭代次数,达到这个次数就停止,这好像不是一个好建议。
2)k个质心应该达到收敛,即第n次计算出的n个质心在第n+1次迭代时候位置不变。
3)n个文档达到收敛,即第n次计算出的n个文档分类和在第n+1次迭代时候文档分类结果相同。
4)RSS值小于一个阀值,实际中往往把这个条件结合条件1使用
回过头用RSS讨论质心的计算方法是否合理
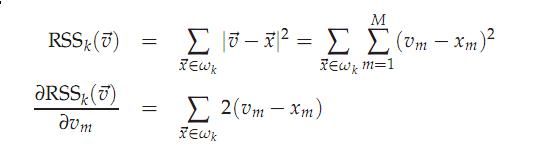
为了取得RSS的极小值,RSS对质心求偏导数应该为0,所以得到质心
可见,这个质心的选择是合乎数学原理的。
K-means方法的缺点是聚类结果依赖于初始选择的几个质点位置,看下面这个例子:
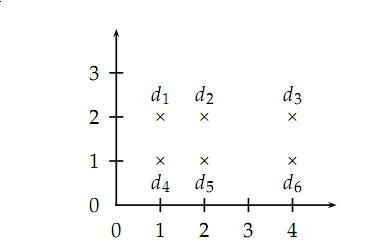
如果使用2-means方法,初始选择d2和d5那么得到的聚类结果就是{d1,d2,d3}{d4,d5,d6},这不是一个合理的聚类结果
解决这种初始种子问题的方案:
1)去处一些游离在外层的文档后再选择
2)多选一些种子,取结果好的(RSS小)的K个类继续算法
3)用层次聚类的方法选择种子。我认为这不是一个合适的方法,因为对初始N个文档进行层次聚类代价非常高。
以上的讨论都是基于K是已知的,但是我们怎么能从随机的文档集合中选择这个k值呢?
我们可以对k去1~N分别执行k-means,得到RSS关于K的函数下图:
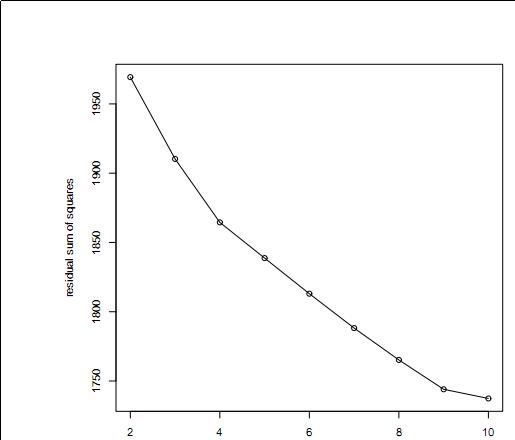
当RSS由显著下降到不是那么显著下降的K值就可以作为最终的K,如图可以选择4或9。
聚类的一些评价手段
什么是聚类
聚类简单的说就是要把一个文档集合根据文档的相似性把文档分成若干类,但是究竟分成多少类,这个要取决于文档集合里文档自身的性质。下面这个图就是一个简单的例子,我们可以把不同的文档聚合为3类。另外聚类是典型的无指导学习,所谓无指导学习是指不需要有人干预,无须人为文档进行标注。
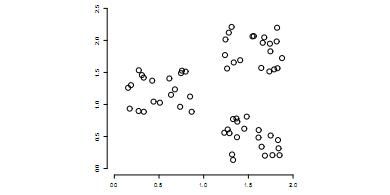
聚类的评价
既然聚类是把一个包含若干文档的文档集合分成若干类,像上图如果聚类算法应该把文档集合分成3类,而不是2类或者5类,这就设计到一个如何评价聚类结果的问题。下面介绍几种聚类算法的评价指标,看下图,
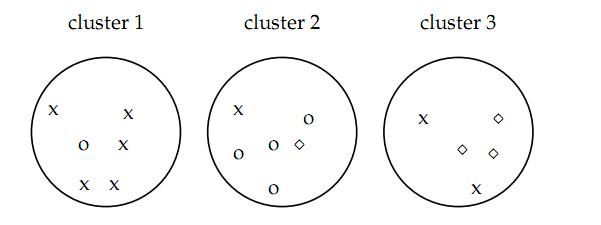
如图认为x代表一类文档,o代表一类文档,方框代表一类文档,完美的聚类显然是应该把各种不同的图形放入一类,事实上我们很难找到完美的聚类方法,各种方法在实际中难免有偏差,所以我们才需要对聚类算法进行评价看我们采用的方法是不是好的算法。
评价方法一:purity
purity方法是极为简单的一种聚类评价方法,只需计算正确聚类的文档数占总文档数的比例:
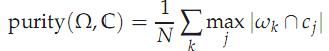
其中Ω = {ω1,ω2, . . . ,ωK}是聚类的集合ωK表示第k个聚类的集合。C = {c1, c2, . . . , cJ}是文档集合,cJ表示第J个文档。N表示文档总数。
如上图的purity = ( 3+ 4 + 5) / 17 = 0.71
其中第一类正确的有5个,第二个4个,第三个3个,总文档数17。
purity方法的优势是方便计算,值在0~1之间,完全错误的聚类方法值为0,完全正确的方法值为1。同时,purity方法的缺点也很明显它无法对退化的聚类方法给出正确的评价,设想如果聚类算法把每篇文档单独聚成一类,那么算法认为所有文档都被正确分类,那么purity值为1!而这显然不是想要的结果。
评价方法二:RI
实际上这是一种用排列组合原理来对聚类进行评价的手段,公式如下:
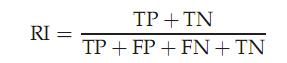
其中TP是指被聚在一类的两个文档被正确分类了,TN是只不应该被聚在一类的两个文档被正确分开了,FP只不应该放在一类的文档被错误的放在了一类,FN只不应该分开的文档被错误的分开了。对上图
TP+FP = C(2,6) + C(2,6) + C(2,5) = 15 + 15 + 10 = 40 其中C(n,m)是指在m中任选n个的组合数。
TP = C(2,5) + C(2,4) + C(2,3) + C(2,2) = 20
FP = 40 - 20 = 20
相似的方法可以计算出TN = 72 FN = 24
所以RI = ( 20 + 72) / ( 20 + 20 + 72 +24) = 0.68
评价方法三:F值
这是基于上述RI方法衍生出的一个方法,
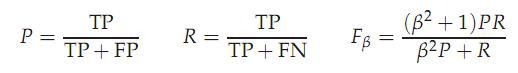
RI方法有个特点就是把准确率和召回率看得同等重要,事实上有时候我们可能需要某一特性更多一点,这时候就适合F值方法