机器学习算法与Python实践之(七)逻辑回归(Logistic Regression)
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。比如某用户购买某商品的可能性,某病人患有某种疾病的可能性,以及某广告被用户点击的可能性等。(注意这里是:“可能性”,而非数学上的“概率”,logisitc回归的结果并非数学定义中的概率值,不可以直接当做概率值来用。该结果往往用于和其他特征值加权求和,而非直接相乘)
那么它究竟是什么样的一个东西,又有哪些适用情况和不适用情况呢?
一. 官方定义:
Figure 1. The logistic function, with z on the horizontal axis and ƒ(z) on the vertical axis
逻辑回归是一个学习f:X− > Y 方程或者P(Y|X)的方法,这里Y是离散取值的,X= < X1,X2…,Xn > 是任意一个向量其中每个变量离散或者连续取值。
二. 我的解释
只看公式太痛苦了,分开说一下就好。Logistic Regression 有三个主要组成部分:回归、线性回归、Logsitic方程。
1)回归
Logistic Regression 是线性回归的一种,线性回归是一种回归。那么回归是什么呢?
回归其实就是对已知公式的未知参数进行估计。大家可以简单的理解为,在给定训练样本点和已知的公式后,对于一个或多个未知参数,机器会自动枚举参数的所有可能取值(对于多个参数要枚举它们的不同组合),直到找到那个最符合样本点分布的参数(或参数组合)。(当然,实际运算有一些优化算法,肯定不会去枚举的)
注意,回归的前提是公式已知,否则回归无法进行。而现实生活中哪里有已知的公式啊(G=m*g 也是牛顿被苹果砸了脑袋之后碰巧想出来的不是?哈哈),因此回归中的公式基本都是数据分析人员通过看大量数据后猜测的(其实大多数是拍脑袋想出来的,嗯…)。根据这些公式的不同,回归分为线性回归和非线性回归。线性回归中公式都是“一次”的(一元一次方程,二元一次方程…),而非线性则可以有各种形式(N元N次方程,log方程 等等)。具体的例子在线性回归中介绍吧。
2)线性回归
直接来一个最简单的一元变量的例子:假设要找一个 y 和 x 之间的规律,其中 x 是鞋子价钱,y 是鞋子的销售量。(为什么要找这个规律呢?这样的话可以帮助定价来赚更多的钱嘛,小学的应用题经常做的呵呵)。已知一些往年的销售数据(x0,y0), (x1, y1), … (xn, yn)做样本集, 并假设它们满足线性关系:y = a*x + b (其中a,b的具体取值还不确定),线性回归即根据往年数据找出最佳的 a, b 取值,使 y = a * x + b 在所有样本集上误差最小。
也许你会觉得…..晕!这么简单! 这需要哪门子的回归呀!我自己在草纸上画个xy坐标系,点几个点就能画出来!(好吧,我承认我们初中时都被这样的画图题折磨过)。事实上一元变量的确很直观,但如果是多元就难以直观的看出来了。比如说除了鞋子的价格外,鞋子的质量,广告的投入,店铺所在街区的人流量都会影响销量,我们想得到这样的公式:sell = a*x + b*y + c*z + d*zz + e。这个时候画图就画不出来了,规律也十分难找,那么交给线性回归去做就好。(线性回归具体是怎么做的请参考相应文献,都是一些数学公式,对程序员来说,我们就把它当成一条程序命令就好)。这就是线性回归算法的价值。
需要注意的是,这里线性回归能过获得好效果的前提是y = a*x + b 至少从总体上是有道理的(因为我们认为鞋子越贵,卖的数量越少,越便宜卖的越多。另外鞋子质量、广告投入、客流量等都有类似规律);但并不是所有类型的变量都适合用线性回归,比如说x不是鞋子的价格,而是鞋子的尺码),那么无论回归出什么样的(a,b),错误率都会极高(因为事实上尺码太大或尺码太小都会减少销量)。总之:如果我们的公式假设是错的,任何回归都得不到好结果。
3)Logistic方程
上面我们的sell是一个具体的实数值,然而很多情况下,我们需要回归产生一个类似概率值的0~1之间的数值(比如某一双鞋子今天能否卖出去?或者某一个广告能否被用户点击? 我们希望得到这个数值来帮助决策鞋子上不上架,以及广告展不展示)。这个数值必须是0~1之间,但sell显然不满足这个区间要求。于是引入了Logistic方程,来做归一化。这里再次说明,该数值并不是数学中定义的概率值。那么既然得到的并不是概率值,为什么我们还要费这个劲把数值归一化为0~1之间呢?归一化的好处在于数值具备可比性和收敛的边界,这样当你在其上继续运算时(比如你不仅仅是关心鞋子的销量,而是要对鞋子卖出的可能、当地治安情况、当地运输成本 等多个要素之间加权求和,用综合的加和结果决策是否在此地开鞋店时),归一化能够保证此次得到的结果不会因为边界 太大/太小 导致 覆盖其他feature 或 被其他feature覆盖。(举个极端的例子,如果鞋子销量最低为100,但最好时能卖无限多个,而当地治安状况是用0~1之间的数值表述的,如果两者直接求和治安状况就完全被忽略了)这是用logistic回归而非直接线性回归的主要原因。到了这里,也许你已经开始意识到,没错,Logistic Regression 就是一个被 Logistic 方程归一化后的线性回归,仅此而已。
至于所以用 Logistic 而不用其它,是因为这种归一化的方法往往比较合理(人家都说自己叫Logistic 了嘛,呵呵),能够打压过大和过小的结果(往往是噪音),以保证主流的结果不至于被忽视。具体的公式及图形见本文的一、官方定义部分。其中 f(X) 就是我们上面例子中的 sell 的实数值了,而 y 就是得到的0~1之间的卖出可能性数值了。
三. Logistic Regression的适用性
1) 可用于概率预测,也可用于分类。
并不是所有的机器学习方法都可以做可能性概率预测(比如 SVM 就不行,它只能得到1或者-1)。可能性预测的好处是结果又可比性:比如我们得到不同广告被点击的可能性后,就可以展现点击可能性最大的 N 个。这样以来,哪怕得到的可能性都很高,或者可能性都很低,我们都能取最优的topN。当用于分类问题时,仅需要设定一个阈值即可,可能性高于阈值是一类,低于阈值是另一类。
2) 仅能用于线性问题
只有在 feature 和 target 是线性关系时,才能用 Logistic Regression(不像SVM那样可以应对非线性问题)。这有两点指导意义,一方面当预先知道模型非线性时,果断不使用 Logistic Regression; 另一方面,在使用 Logistic Regression 时注意选择和 target 呈线性关系的 feature。
3) 各feature之间不需要满足条件独立假设,但各个feature的贡献是独立计算的。
逻辑回归不像朴素贝叶斯一样需要满足条件独立假设(因为它没有求后验概率)。但每个feature的贡献是独立计算的,即LR是不会自动帮你 combine 不同的 features 产生新 feature 的 (时刻不能抱有这种幻想,那是决策树,LSA,pLSA,LDA或者你自己要干的事情)。举个例子,如果你需要TF*IDF这样的feature,就必须明确的给出来,若仅仅分别给出两维 TF 和 IDF 是不够的,那样只会得到类似 a*TF + b*IDF 的结果,而不会有 c*TF*IDF 的效果。
机器学习算法与Python实践这个系列主要是参考《机器学习实战》这本书。因为自己想学习Python,然后也想对一些机器学习算法加深下了解,所以就想通过Python来实现几个比较常用的机器学习算法。恰好遇见这本同样定位的书籍,所以就参考这本书的过程来学习了。
这节学习的是逻辑回归(Logistic Regression),也算进入了比较正统的机器学习算法。啥叫正统呢?我概念里面机器学习算法一般是这样一个步骤:
1)对于一个问题,我们用数学语言来描述它,然后建立一个模型,例如回归模型或者分类模型等来描述这个问题;
2)通过最大似然、最大后验概率或者最小化分类误差等等建立模型的代价函数,也就是一个最优化问题。找到最优化问题的解,也就是能拟合我们的数据的最好的模型参数;
3)然后我们需要求解这个代价函数,找到最优解。这求解也就分很多种情况了:
a)如果这个优化函数存在解析解。例如我们求最值一般是对代价函数求导,找到导数为0的点,也就是最大值或者最小值的地方了。如果代价函数能简单求导,并且求导后为0的式子存在解析解,那么我们就可以直接得到最优的参数了。
b)如果式子很难求导,例如函数里面存在隐含的变量或者变量相互间存在耦合,也就互相依赖的情况。或者求导后式子得不到解释解,例如未知参数的个数大于已知方程组的个数等。这时候我们就需要借助迭代算法来一步一步找到最有解了。迭代是个很神奇的东西,它将远大的目标(也就是找到最优的解,例如爬上山顶)记在心上,然后给自己定个短期目标(也就是每走一步,就离远大的目标更近一点),脚踏实地,心无旁贷,像个蜗牛一样,一步一步往上爬,支撑它的唯一信念是:只要我每一步都爬高一点,那么积跬步,肯定能达到自己人生的巅峰,尽享山登绝顶我为峰的豪迈与忘我。
另外需要考虑的情况是,如果代价函数是凸函数,那么就存在全局最优解,方圆五百里就只有一个山峰,那命中注定了,它就是你要找的唯一了。但如果是非凸的,那么就会有很多局部最优的解,有一望无际的山峰,人的视野是伟大的也是渺小的,你不知道哪个山峰才是最高的,可能你会被命运作弄,很无辜的陷入一个局部最优里面,坐井观天,以为自己找到的就是最好的。没想到山外有山,人外有人,光芒总在未知的远处默默绽放。但也许命运眷恋善良的你,带给你的总是最好的归宿。也有很多不信命的人,觉得人定胜天的人,誓要找到最好的,否则不会罢休,永不向命运妥协,除非自己有一天累了,倒下了,也要靠剩下的一口气,迈出一口气能支撑的路程。好悲凉啊……哈哈。
呃,不知道扯那去了,也不知道自己说的有没有错,有错的话请大家不吝指正。那下面就进入正题吧。正如上面所述,逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏,冥冥人海,滚滚红尘,我们是否找到了最适合的那个她。
一、逻辑回归(LogisticRegression)
Logistic regression (逻辑回归)是当前业界比较常用的机器学习方法,用于估计某种事物的可能性。之前在经典之作《数学之美》中也看到了它用于广告预测,也就是根据某广告被用户点击的可能性,把最可能被用户点击的广告摆在用户能看到的地方,然后叫他“你点我啊!”用户点了,你就有钱收了。这就是为什么我们的电脑现在广告泛滥的原因了。
还有类似的某用户购买某商品的可能性,某病人患有某种疾病的可能性啊等等。这个世界是随机的(当然了,人为的确定性系统除外,但也有可能有噪声或产生错误的结果,只是这个错误发生的可能性太小了,小到千万年不遇,小到忽略不计而已),所以万物的发生都可以用可能性或者几率(Odds)来表达。“几率”指的是某事物发生的可能性与不发生的可能性的比值。
Logistic regression可以用来回归,也可以用来分类,主要是二分类。还记得上几节讲的支持向量机SVM吗?它就是个二分类的例如,它可以将两个不同类别的样本给分开,思想是找到最能区分它们的那个分类超平面。但当你给一个新的样本给它,它能够给你的只有一个答案,你这个样本是正类还是负类。例如你问SVM,某个女生是否喜欢你,它只会回答你喜欢或者不喜欢。这对我们来说,显得太粗鲁了,要不希望,要不绝望,这都不利于身心健康。那如果它可以告诉我,她很喜欢、有一点喜欢、不怎么喜欢或者一点都不喜欢,你想都不用想了等等,告诉你她有49%的几率喜欢你,总比直接说她不喜欢你,来得温柔。而且还提供了额外的信息,她来到你的身边你有多少希望,你得再努力多少倍,知己知彼百战百胜,哈哈。Logistic regression就是这么温柔的,它给我们提供的就是你的这个样本属于正类的可能性是多少。
还得来点数学。(更多的理解,请参阅参考文献)假设我们的样本是{x, y},y是0或者1,表示正类或者负类,x是我们的m维的样本特征向量。那么这个样本x属于正类,也就是y=1的“概率”可以通过下面的逻辑函数来表示:

这里θ是模型参数,也就是回归系数,σ是sigmoid函数。实际上这个函数是由下面的对数几率(也就是x属于正类的可能性和负类的可能性的比值的对数)变换得到的:

换句话说,y也就是我们关系的变量,例如她喜不喜欢你,与多个自变量(因素)有关,例如你人品怎样、车子是两个轮的还是四个轮的、长得胜过潘安还是和犀利哥有得一拼、有千尺豪宅还是三寸茅庐等等,我们把这些因素表示为x1, x2,…, xm。那这个女的怎样考量这些因素呢?最快的方式就是把这些因素的得分都加起来,最后得到的和越大,就表示越喜欢。但每个人心里其实都有一杆称,每个人考虑的因素不同,萝卜青菜,各有所爱嘛。例如这个女生更看中你的人品,人品的权值是0.6,不看重你有没有钱,没钱了一起努力奋斗,那么有没有钱的权值是0.001等等。我们将这些对应x1, x2,…, xm的权值叫做回归系数,表达为θ1, θ2,…, θm。他们的加权和就是你的总得分了。请选择你的心仪男生,非诚勿扰!哈哈。
所以说上面的logistic回归就是一个线性分类模型,它与线性回归的不同点在于:为了将线性回归输出的很大范围的数,例如从负无穷到正无穷,压缩到0和1之间,这样的输出值表达为“可能性”才能说服广大民众。当然了,把大值压缩到这个范围还有个很好的好处,就是可以消除特别冒尖的变量的影响(不知道理解的是否正确)。而实现这个伟大的功能其实就只需要平凡一举,也就是在输出加一个logistic函数。另外,对于二分类来说,可以简单的认为:如果样本x属于正类的概率大于0.5,那么就判定它是正类,否则就是负类。实际上,SVM的类概率就是样本到边界的距离,这个活实际上就让logistic regression给干了。

所以说,LogisticRegression 就是一个被logistic方程归一化后的线性回归,仅此而已。
好了,关于LR的八卦就聊到这。归入到正统的机器学习框架下,模型选好了,只是模型的参数θ还是未知的,我们需要用我们收集到的数据来训练求解得到它。那我们下一步要做的事情就是建立代价函数了。
LogisticRegression最基本的学习算法是最大似然。啥叫最大似然,可以看看我的另一篇博文“从最大似然到EM算法浅解”。
假设我们有n个独立的训练样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1}。那每一个观察到的样本(xi, yi)出现的概率是:
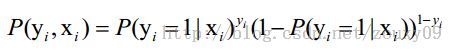
上面为什么是这样呢?当y=1的时候,后面那一项是不是没有了,那就只剩下x属于1类的概率,当y=0的时候,第一项是不是没有了,那就只剩下后面那个x属于0的概率(1减去x属于1的概率)。所以不管y是0还是1,上面得到的数,都是(x, y)出现的概率。那我们的整个样本集,也就是n个独立的样本出现的似然函数为(因为每个样本都是独立的,所以n个样本出现的概率就是他们各自出现的概率相乘):

那最大似然法就是求模型中使得似然函数最大的系数取值θ*。这个最大似然就是我们的代价函数(cost function)了。
OK,那代价函数有了,我们下一步要做的就是优化求解了。我们先尝试对上面的代价函数求导,看导数为0的时候可不可以解出来,也就是有没有解析解,有这个解的时候,就皆大欢喜了,一步到位。如果没有就需要通过迭代了,耗时耗力。
我们先变换下L(θ):取自然对数,然后化简(不要看到一堆公式就害怕哦,很简单的哦,只需要耐心一点点,自己动手推推就知道了。注:有xi的时候,表示它是第i个样本,下面没有做区分了,相信你的眼睛是雪亮的),得到:

这时候,用L(θ)对θ求导,得到:

然后我们令该导数为0,你会很失望的发现,它无法解析求解。不信你就去尝试一下。所以没办法了,只能借助高大上的迭代来搞定了。这里选用了经典的梯度下降算法。
二、优化求解
2.1、梯度下降(gradient descent)
Gradient descent 又叫 steepest descent,是利用一阶的梯度信息找到函数局部最优解的一种方法,也是机器学习里面最简单最常用的一种优化方法。它的思想很简单,和我开篇说的那样,要找最小值,我只需要每一步都往下走(也就是每一步都可以让代价函数小一点),然后不断的走,那肯定能走到最小值的地方,例如下图所示:

但,我同时也需要更快的到达最小值啊,怎么办呢?我们需要每一步都找下坡最快的地方,也就是每一步我走某个方向,都比走其他方法,要离最小值更近。而这个下坡最快的方向,就是梯度的负方向了。
对logistic Regression来说,梯度下降算法新鲜出炉,如下:
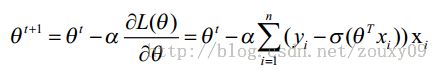
其中,参数α叫学习率,就是每一步走多远,这个参数蛮关键的。如果设置的太多,那么很容易就在最优值附加徘徊,因为你步伐太大了。例如要从广州到上海,但是你的一步的距离就是广州到北京那么远,没有半步的说法,自己能迈那么大步,是幸运呢?还是不幸呢?事物总有两面性嘛,它带来的好处是能很快的从远离最优值的地方回到最优值附近,只是在最优值附近的时候,它有心无力了。但如果设置的太小,那收敛速度就太慢了,向蜗牛一样,虽然会落在最优的点,但是这速度如果是猴年马月,我们也没这耐心啊。所以有的改进就是在这个学习率这个地方下刀子的。我开始迭代是,学习率大,慢慢的接近最优值的时候,我的学习率变小就可以了。所谓采两者之精华啊!这个优化具体见2.3 。
梯度下降算法的伪代码如下:
################################################
初始化回归系数为1
重复下面步骤直到收敛{
计算整个数据集的梯度
使用alpha x gradient来更新回归系数
}
返回回归系数值
################################################
2.2、随机梯度下降SGD (stochastic gradient descent)
梯度下降算法在每次更新回归系数的时候都需要遍历整个数据集(计算整个数据集的回归误差),该方法对小数据集尚可。但当遇到有数十亿样本和成千上万的特征时,就有点力不从心了,它的计算复杂度太高。改进的方法是一次仅用一个样本点(的回归误差)来更新回归系数。这个方法叫随机梯度下降算法。由于可以在新的样本到来的时候对分类器进行增量的更新(假设我们已经在数据库A上训练好一个分类器h了,那新来一个样本x。对非增量学习算法来说,我们需要把x和数据库A混在一起,组成新的数据库B,再重新训练新的分类器。但对增量学习算法,我们只需要用新样本x来更新已有分类器h的参数即可),所以它属于在线学习算法。与在线学习相对应,一次处理整个数据集的叫“批处理”。
随机梯度下降算法的伪代码如下:
################################################
初始化回归系数为1
重复下面步骤直到收敛{
对数据集中每个样本
计算该样本的梯度
使用alpha xgradient来更新回归系数
}
返回回归系数值
################################################
2.3、改进的随机梯度下降
评价一个优化算法的优劣主要是看它是否收敛,也就是说参数是否达到稳定值,是否还会不断的变化?收敛速度是否快?

上图展示了随机梯度下降算法在200次迭代中(请先看第三和第四节再回来看这里。我们的数据库有100个二维样本,每个样本都对系数调整一次,所以共有200*100=20000次调整)三个回归系数的变化过程。其中系数X2经过50次迭代就达到了稳定值。但系数X1和X0到100次迭代后稳定。而且可恨的是系数X1和X2还在很调皮的周期波动,迭代次数很大了,心还停不下来。产生这个现象的原因是存在一些无法正确分类的样本点,也就是我们的数据集并非线性可分,但我们的logistic regression是线性分类模型,对非线性可分情况无能为力。然而我们的优化程序并没能意识到这些不正常的样本点,还一视同仁的对待,调整系数去减少对这些样本的分类误差,从而导致了在每次迭代时引发系数的剧烈改变。对我们来说,我们期待算法能避免来回波动,从而快速稳定和收敛到某个值。
对随机梯度下降算法,我们做两处改进来避免上述的波动问题:
1)在每次迭代时,调整更新步长alpha的值。随着迭代的进行,alpha越来越小,这会缓解系数的高频波动(也就是每次迭代系数改变得太大,跳的跨度太大)。当然了,为了避免alpha随着迭代不断减小到接近于0(这时候,系数几乎没有调整,那么迭代也没有意义了),我们约束alpha一定大于一个稍微大点的常数项,具体见代码。
2)每次迭代,改变样本的优化顺序。也就是随机选择样本来更新回归系数。这样做可以减少周期性的波动,因为样本顺序的改变,使得每次迭代不再形成周期性。
改进的随机梯度下降算法的伪代码如下:
################################################
初始化回归系数为1
重复下面步骤直到收敛{
对随机遍历的数据集中的每个样本
随着迭代的逐渐进行,减小alpha的值
计算该样本的梯度
使用alpha x gradient来更新回归系数
}
返回回归系数值
################################################

比较原始的随机梯度下降和改进后的梯度下降,可以看到两点不同:
1)系数不再出现周期性波动。2)系数可以很快的稳定下来,也就是快速收敛。这里只迭代了20次就收敛了。而上面的随机梯度下降需要迭代200次才能稳定。
三、Python实现
我使用的Python是2.7.5版本的。附加的库有Numpy和Matplotlib。具体的安装和配置见前面的博文。在代码中已经有了比较详细的注释了。不知道有没有错误的地方,如果有,还望大家指正(每次的运行结果都有可能不同)。里面我写了个可视化结果的函数,但只能在二维的数据上面使用。直接贴代码:
logRegression.py
- #################################################
- # logRegression: Logistic Regression
- # Author : zouxy
- # Date : 2014-03-02
- # HomePage : http://blog.csdn.net/zouxy09
- # Email : [email protected]
- #################################################
- from numpy import *
- import matplotlib.pyplot as plt
- import time
- # calculate the sigmoid function
- def sigmoid(inX):
- return 1.0 / (1 + exp(-inX))
- # train a logistic regression model using some optional optimize algorithm
- # input: train_x is a mat datatype, each row stands for one sample
- # train_y is mat datatype too, each row is the corresponding label
- # opts is optimize option include step and maximum number of iterations
- def trainLogRegres(train_x, train_y, opts):
- # calculate training time
- startTime = time.time()
- numSamples, numFeatures = shape(train_x)
- alpha = opts['alpha']; maxIter = opts['maxIter']
- weights = ones((numFeatures, 1))
- # optimize through gradient descent algorilthm
- for k in range(maxIter):
- if opts['optimizeType'] == 'gradDescent': # gradient descent algorilthm
- output = sigmoid(train_x * weights)
- error = train_y - output
- weights = weights + alpha * train_x.transpose() * error
- elif opts['optimizeType'] == 'stocGradDescent': # stochastic gradient descent
- for i in range(numSamples):
- output = sigmoid(train_x[i, :] * weights)
- error = train_y[i, 0] - output
- weights = weights + alpha * train_x[i, :].transpose() * error
- elif opts['optimizeType'] == 'smoothStocGradDescent': # smooth stochastic gradient descent
- # randomly select samples to optimize for reducing cycle fluctuations
- dataIndex = range(numSamples)
- for i in range(numSamples):
- alpha = 4.0 / (1.0 + k + i) + 0.01
- randIndex = int(random.uniform(0, len(dataIndex)))
- output = sigmoid(train_x[randIndex, :] * weights)
- error = train_y[randIndex, 0] - output
- weights = weights + alpha * train_x[randIndex, :].transpose() * error
- del(dataIndex[randIndex]) # during one interation, delete the optimized sample
- else:
- raise NameError('Not support optimize method type!')
- print 'Congratulations, training complete! Took %fs!' % (time.time() - startTime)
- return weights
- # test your trained Logistic Regression model given test set
- def testLogRegres(weights, test_x, test_y):
- numSamples, numFeatures = shape(test_x)
- matchCount = 0
- for i in xrange(numSamples):
- predict = sigmoid(test_x[i, :] * weights)[0, 0] > 0.5
- if predict == bool(test_y[i, 0]):
- matchCount += 1
- accuracy = float(matchCount) / numSamples
- return accuracy
- # show your trained logistic regression model only available with 2-D data
- def showLogRegres(weights, train_x, train_y):
- # notice: train_x and train_y is mat datatype
- numSamples, numFeatures = shape(train_x)
- if numFeatures != 3:
- print "Sorry! I can not draw because the dimension of your data is not 2!"
- return 1
- # draw all samples
- for i in xrange(numSamples):
- if int(train_y[i, 0]) == 0:
- plt.plot(train_x[i, 1], train_x[i, 2], 'or')
- elif int(train_y[i, 0]) == 1:
- plt.plot(train_x[i, 1], train_x[i, 2], 'ob')
- # draw the classify line
- min_x = min(train_x[:, 1])[0, 0]
- max_x = max(train_x[:, 1])[0, 0]
- weights = weights.getA() # convert mat to array
- y_min_x = float(-weights[0] - weights[1] * min_x) / weights[2]
- y_max_x = float(-weights[0] - weights[1] * max_x) / weights[2]
- plt.plot([min_x, max_x], [y_min_x, y_max_x], '-g')
- plt.xlabel('X1'); plt.ylabel('X2')
- plt.show()
四、测试结果
测试代码:
test_logRegression.py
- #################################################
- # logRegression: Logistic Regression
- # Author : zouxy
- # Date : 2014-03-02
- # HomePage : http://blog.csdn.net/zouxy09
- # Email : [email protected]
- #################################################
- from numpy import *
- import matplotlib.pyplot as plt
- import time
- def loadData():
- train_x = []
- train_y = []
- fileIn = open('E:/Python/Machine Learning in Action/testSet.txt')
- for line in fileIn.readlines():
- lineArr = line.strip().split()
- train_x.append([1.0, float(lineArr[0]), float(lineArr[1])])
- train_y.append(float(lineArr[2]))
- return mat(train_x), mat(train_y).transpose()
- ## step 1: load data
- print "step 1: load data..."
- train_x, train_y = loadData()
- test_x = train_x; test_y = train_y
- ## step 2: training...
- print "step 2: training..."
- opts = {'alpha': 0.01, 'maxIter': 20, 'optimizeType': 'smoothStocGradDescent'}
- optimalWeights = trainLogRegres(train_x, train_y, opts)
- ## step 3: testing
- print "step 3: testing..."
- accuracy = testLogRegres(optimalWeights, test_x, test_y)
- ## step 4: show the result
- print "step 4: show the result..."
- print 'The classify accuracy is: %.3f%%' % (accuracy * 100)
- showLogRegres(optimalWeights, train_x, train_y)
测试数据是二维的,共100个样本。有2个类。如下:
testSet.txt
- -0.017612 14.053064 0
- -1.395634 4.662541 1
- -0.752157 6.538620 0
- -1.322371 7.152853 0
- 0.423363 11.054677 0
- 0.406704 7.067335 1
- 0.667394 12.741452 0
- -2.460150 6.866805 1
- 0.569411 9.548755 0
- -0.026632 10.427743 0
- 0.850433 6.920334 1
- 1.347183 13.175500 0
- 1.176813 3.167020 1
- -1.781871 9.097953 0
- -0.566606 5.749003 1
- 0.931635 1.589505 1
- -0.024205 6.151823 1
- -0.036453 2.690988 1
- -0.196949 0.444165 1
- 1.014459 5.754399 1
- 1.985298 3.230619 1
- -1.693453 -0.557540 1
- -0.576525 11.778922 0
- -0.346811 -1.678730 1
- -2.124484 2.672471 1
- 1.217916 9.597015 0
- -0.733928 9.098687 0
- -3.642001 -1.618087 1
- 0.315985 3.523953 1
- 1.416614 9.619232 0
- -0.386323 3.989286 1
- 0.556921 8.294984 1
- 1.224863 11.587360 0
- -1.347803 -2.406051 1
- 1.196604 4.951851 1
- 0.275221 9.543647 0
- 0.470575 9.332488 0
- -1.889567 9.542662 0
- -1.527893 12.150579 0
- -1.185247 11.309318 0
- -0.445678 3.297303 1
- 1.042222 6.105155 1
- -0.618787 10.320986 0
- 1.152083 0.548467 1
- 0.828534 2.676045 1
- -1.237728 10.549033 0
- -0.683565 -2.166125 1
- 0.229456 5.921938 1
- -0.959885 11.555336 0
- 0.492911 10.993324 0
- 0.184992 8.721488 0
- -0.355715 10.325976 0
- -0.397822 8.058397 0
- 0.824839 13.730343 0
- 1.507278 5.027866 1
- 0.099671 6.835839 1
- -0.344008 10.717485 0
- 1.785928 7.718645 1
- -0.918801 11.560217 0
- -0.364009 4.747300 1
- -0.841722 4.119083 1
- 0.490426 1.960539 1
- -0.007194 9.075792 0
- 0.356107 12.447863 0
- 0.342578 12.281162 0
- -0.810823 -1.466018 1
- 2.530777 6.476801 1
- 1.296683 11.607559 0
- 0.475487 12.040035 0
- -0.783277 11.009725 0
- 0.074798 11.023650 0
- -1.337472 0.468339 1
- -0.102781 13.763651 0
- -0.147324 2.874846 1
- 0.518389 9.887035 0
- 1.015399 7.571882 0
- -1.658086 -0.027255 1
- 1.319944 2.171228 1
- 2.056216 5.019981 1
- -0.851633 4.375691 1
- -1.510047 6.061992 0
- -1.076637 -3.181888 1
- 1.821096 10.283990 0
- 3.010150 8.401766 1
- -1.099458 1.688274 1
- -0.834872 -1.733869 1
- -0.846637 3.849075 1
- 1.400102 12.628781 0
- 1.752842 5.468166 1
- 0.078557 0.059736 1
- 0.089392 -0.715300 1
- 1.825662 12.693808 0
- 0.197445 9.744638 0
- 0.126117 0.922311 1
- -0.679797 1.220530 1
- 0.677983 2.556666 1
- 0.761349 10.693862 0
- -2.168791 0.143632 1
- 1.388610 9.341997 0
- 0.317029 14.739025 0
训练结果:
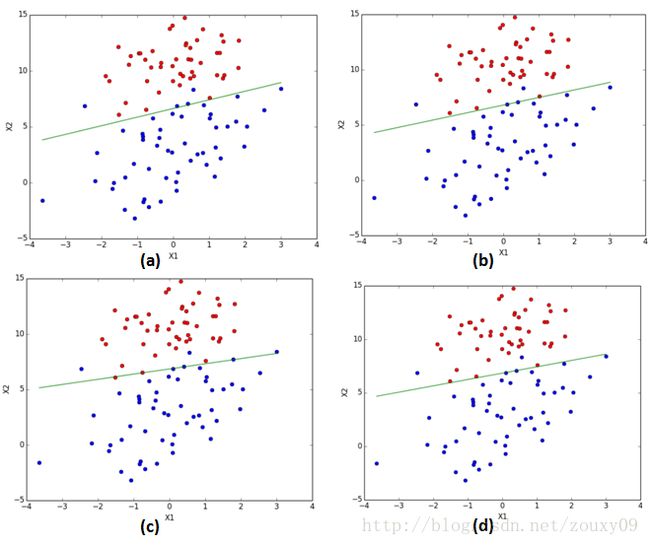
(a)梯度下降算法迭代500次。(b)随机梯度下降算法迭代200次。(c)改进的随机梯度下降算法迭代20次。(d)改进的随机梯度下降算法迭代200次。
逻辑回归源码实现:
<pre name="code" class="html">#coding=utf-8
'''
Created on Oct 27, 2010
Logistic Regression Working Module
@author: Peter
logistic回归的一半过程
(1)收集数据:采用任意方法收集数据。
(2)准备数据:由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据
格式则最佳。
(3)分析数据:采用任意方法对数据进行分析。
(4)训练算法:大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
(5)测试算法:’一旦训练步骤完成,分类将会很快。
(6)使用算法:首先,我们需要输入一些数据,并将其转换成对应的结构化数值;
接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于
哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
logistic回归
优点 计算代价不高 易于理解和实现
缺点 容易欠拟合,分类精度可能不高
使用数据类型 数值型和标称型数据
当x为0时,Sigmoid函数值为0.5 0
随着x的增大,对应的Sigmoid值将逼近于1;而随着x的减小,Sigmoid值将逼近于0。如果横坐标
刻度足够大(图5-1下图),Sigmoid函数看起来很像一个阶跃函数。
因此,为了实现Logistic回归分类器,我们可以在每个特征上都乘以一个回归系数,然后把
所有的结果值相加,将这个总和代人Sigmoid }数中,进而得到一个范围在0}1之间的数值。任
何大于0.5的数据被分人1类,小于0.5即被归人0类。所以,Logisti。回归也可以被看成是一种概
率估计。
梯度上升法:
梯度上升算法到达每个点后都会重新估计移动的方向。从PO开始,计算完该点
的梯度,函数就根据梯度移动到下一点P1。在P1点,梯度再次被重新计算,并
沿新的梯度方向移动到P2。如此循环迭代,直到满足停止条件。迭代的过程中,
梯度算子总是保证我们能选取到最佳的移动方向
Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化
算法来完成。在最优化算法中,最常用的就是梯度上升算法,而梯度上升算法又可以简化为随机
梯度上升算法。
随机梯度上升算法与梯度上升算法的效果相当,但占用更少的计算资源。此外,随机梯度上
升是一个在线算法,它可以在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进
行批处理运算。
机器学习的一个重要问题就是如何处理缺失数据。这个问题没有标准答案,取决于实际应用
中的需求。现有一些解决方案,每种方案都各有优缺点。
sigmoid函数 x为0时,sigmoid函数值为0.5
随着x的增大,对应的sigmoid值将逼近于1,随着x的减小,sigmoid的值接近于0
如果横坐标刻度足够大,sigmoid函数看起来很像一个阶跃函数
为了实现sigmoid回归分类器,可以在每个特征上乘以一个回归系数,然后将所有结果的值想加
将总和代入到sigmoid函数中,进而得到一个范围在0~1之间的数值。任何大于0.5的数据被分入
1类,小于0.5的被归入0类,logistic回归可以看做一种概率估计
基于最优化方法的最佳回归系数确定
z=w0*x0+w1*x1+...+wn*xn
梯度上升法
基本思想:要找到某函数的最大值,最好的方法时沿着该函数的梯度方向探寻,如果梯度记为▽,则函数
的f(x,y)梯度由下式表示:
梯度算子总是指向函数值增长最快的方向。注意:所说的是移动方向,而不是移动量的大小
该量值为步长,记为a
用向量表示的话,梯度算法的迭代公式如下:
w:=w+a▽f(w)
该公式一直被迭代执行,直至达到某个停止条件为止
梯度上升法求函数的最大值
梯度下降法求函数的最小值
'''
from numpy import *
'''
梯度上升法的伪代码如下:
每个回归系数初始化为1
重复R次:
计算整个数据集的梯度
使用alpha x gradient更新回归系数的向量
返回回归系数
'''
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt') #打开文本文件testSet.txt并逐行读取 每行前两个值分别是x1和x2 第三个值是数据对应的类别标签
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #为了方便计算,该函数将X0设为1.0
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX))
'''
梯度上升算法的实际工作是在函数gradAscent()里完成的,该函数有两个参数。第一个参
数是dataMath工n,它是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个
训练样本。我们现在采用的是100个样本的简单数据集,它包含了两个特征X1和X2,再加上第。
维特征XO,所以dataMathln里存放的将是100x3的矩阵。
第二个参数是类别标签,它是一个1x100的行向量。为了便于矩阵运算,需要将该行向量转换为列
向量,做法是将原向量转置,再将它赋值给labelMat。接下来的代码是得到矩阵大小,再设置
一些梯度上升算法所需的参数。
变量alpha是向目标移动的步长,maxCycles是迭代次数。在for循环迭代完成后,将返回
训练好的回归系数。需要强调的是,在2处的运算是矩阵运算。变量h不是一个数而是一个列向
量,列向量的元素个数等于样本个数,这里是100。对应地,运算dataMatrix*weigh七s代表
的不止一次乘积计算,事实上该运算包含了300次的乘积。
>>> import logRegres
>>> dataArr,labelMat = logRegres.loadDataSet()
>>> logRegres.gradAscent(dataArr,labelMat)
'''
def gradAscent(dataMatIn, classLabels): #第一个参数dataMatIn是一个2维numpy数组每列分表代表每个不同的特征 每行代表每个训练样本 第二个参数
dataMatrix = mat(dataMatIn) #convert to NumPy matrix
labelMat = mat(classLabels).transpose() #convert to NumPy matrix 转换为numpy矩阵数据类型
m,n = shape(dataMatrix)
alpha = 0.001 #目标移动的步长
maxCycles = 500 #迭代的次数
weights = ones((n,1))
for k in range(maxCycles): #2 heavy on matrix operations 最终返回训练好的
h = sigmoid(dataMatrix*weights) #matrix mult 矩阵相乘 矩阵运算 h不是一个数而是一个列向量 列向量的元素个数等于样本个数 计算真实类别与预测类别的差值,按照该差值的方向调整回归系数
error = (labelMat - h) #vector subtraction
weights = weights + alpha * dataMatrix.transpose()* error #matrix mult
return weights
'''
分析数据:画出决策边界
>>> from numpy import *
>>> reload(logRegres)
<module 'logRegres' from 'C:\Users\kernel\Documents\python\logRegres.py'>
>>> weights = logRegres.gradAscent(dataArr,labelMat)
>>> logRegres.plotBestFit(weights.getA())
'''
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2] #最佳拟合直线 设置sigmoid函数为0 0两个分类的边界处 0=w0*x0+w1*x1+w2*x2 X0=1
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
'''
梯度上升算法在每次更新回归系数时都需要遍历整个数据集,该方法在处理100个左右的数
据集时尚可,但如果有数十亿样本和成千上万的特征,
那么该方法的计算复杂度就太高了。一种
改进方法是一次仅用一个样本点来更新回归系数,该方法称为随机梯度上升算法。
由于可以在新
样本到来时对分类器进行增量式更新,因而随机梯度上升算法是一个在线学习算法。
习”相对应,一次处理所有数据被称作是“批处理”。
随机梯度上升算法可以写成如下的伪代码:
所有回归系数初始化为1
对数据集中每个样本
计算该样本的梯度
使用alpha x gradient更新回归系数值
返回回归系数值
可以看到,随机梯度上升算法与梯度上升算法在代码上很相似,但也有一些区别:第一,后
者的变量h和误差error都是向量,而前者则全是数值;第二,前者没有矩阵的转换过程,所有
变量的数据类型都是NumPy数组。
>>> weights = logRegres.gradAscent(dataArr,labelMat)
>>> logRegres.plotBestFit(weights.getA())
>>> weights = logRegres.stocGradAscent0(array(dataArr),labelMat)
>>> logRegres.plotBestFit(weights)
这里的分类器错分了三分之一的样本。
运行随机梯度上升算法,在数据集的一次遍历中回归系数与迭代次数的关系
图。回归系数经过大量迭代才能达到稳定值,并且仍然有局部的波动现象
随机梯度上升算法
随机梯度上升算法和梯度上升算法区别:
1、梯度上升算法的变量h和误差error都是向量,随机梯度上升算法全是数值
2、梯度上升算法没有矩阵的转换过程,所有变量的数据类型都是numpy数组
'''
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n) #initialize to all ones
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
'''
改进的随机梯度上升算法
另外,虽然alpha会随着迭代次数不断减小,但永远不会减小到。,这是因为0中
还存在一个常数项。必须这样做的原因是为了保证在多次迭代之后新数据仍然具有一定的影响。
如果要处理的问题是动态变化的,那么可以适当加大上述常数项,来确保新的值获得更大的回归
系数。另一点值得注意的是,在降低alpha的函数中,alpha每次减少1/ (j+i),其中J是迭代次数,
i是样本点的下标①。这样当j +max ( i)时,alpha就不是严格下降的。避免参数的严格下降也常
见于模拟退火算法等其他优化算法中。
此外,改进算法还增加了一个迭代次数作为第3个参数。如果该参数没有给定的话,算法将
默认迭代150次。如果给定,那么算法将按照新的参数值进行迭代。
与stocGradAscen七1()类似,图5-7显示了每次迭代时各个回归系数的变化情况。
使用样本随机选择和alpha动态减少机制的随机梯度上升算法。tocGradASCent1()
所生成的系数收敛示意图。该方法比采用固定alpha的方法收敛速度更快
比较图5-7和图5-6可以看到两点不同。第一点是,图5-7中的系数没有像图5-6里那样出现周
期性的波动,这归功于s七。cGradAscen七1()里的样本随机选择机制;第二点是,图5-7的水平轴
比图5-6短了很多,这是由于stocGradAscentl()可以收敛得更快。这次我们仅仅对数据集做了
20次遍历,而之前的方法是500次。
改进的随机梯度上升算法
下列代码中,alpha的值随着迭代次数不断减小但是不会等于0,有常数项的存在
这样做的原因是为了保证在多次迭代后新数据依然具有一定的影响。如果要处理的
问题是动态变化的,那么可以适当加大上述常数项,来确保新的值活的更大的回归系数
在降低alpha的函数中,alpha每次减少1/(j+i),j是迭代次数,i是样本点的下标
当j<<max(i),alpha不是严格下降的。避免参数的严格下降常见于模拟退火法等其他
优化算法
通过随机选取样本来更新回归系数,这种方法将减少周期性的波动,每次随机从列表中
选出一个值,然后从列表中删除该值,在进行下一次迭代
'''
def stocGradAscent1(dataMatrix, classLabels, numIter=150): #第三个参数如果未指定的话,算法默认迭代150次,如果指定,算法按照新的参数进行迭代
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = range(m)
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not 。alpha每次迭代需要调整,缓解数据波或者高频波动。 随机选取更新
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
'''
它以回归系数和特征向量作为输人来计
算对应的Sigmoid值。如果Sigmoid值大于0.5函数返回l,否则返回0
logistic回归分类函数
'''
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
'''
从病气病症预测病马的死亡率
(1)收集数据:
(2)准备数据:
(3)分析数据:
(4) y}练算法:
给定数据文件。
用Python解析文本文件并填充缺失值。
可视化并观察数据。
使用优化算法,找到最佳的系数。
(5)刚试算法:为了量化回归的效果,
需要观察错误率。根据错误率决定是否回退到训练
阶段,通过改变迭代的次数和步长等参数来得到更好的回归系数。
(6)使用算法:实现一个简单的命令行程序来收集马的症状并输出预侧结果并非难事,这
可以做为留给读者的一道习题。
处理数据中的缺失值:
使用可用特征的均值来填补缺失值;
使用特殊值来填补缺失值,如一1;
忽略有缺失值的样本;
使用相似样本的均值添补缺失值;
使用另外的机器学习算法预测缺失值。
对数据集进行预处理,使其顺利的使用分类算法
在预处理阶段 需要做两件事:
1、所有的缺失值必须使用一个实数值来替换,因为使用numpy数据类型不允许包含缺失值。这里选择
实数0来替换所有缺失值,恰好适用于logistic回归,这样做的直觉在于,我们需要的是一个在更新时
不会影响系数的值,回归系数的更新公式:
weights = weights + alpha * error * dataMatrix[randIndex]
如果dataMatrix的某特征值对应值为0,那么该特征的系数将不做更新
即:weights=weights
由于sigmoid(0)=0.5,即它对结果的预测不具备任何倾向性,因此上述做法也不会对误差项造成任何影响
基于上述原因,将缺失值用0来替代既可以保留现有数据,也不需要对优化算法进行修改,此外
该数据集中的特征值一般不为0
2、如果测试数据集中发现了一条数据的类别标签已经缺失,那么我们的简单做法是将该条数据丢弃
因为类别标签与特征不同,很难确定采用某个合适的值来替换。采用logRegres回归进行分类时
这种做法是合理的,而如果采用类似kNN的方法就可能不太可行
接下来的函数是colicTest(),是用于打开测试集和训练集,并对数据进行格式化处理的
函数。该函数音先导人训练集,同前面一样,数据的最后一列仍然是类别标签。数据最初有三个
类别标签,分别代表马的三种情况:“仍存活”、“已经死亡”和“已经安乐死”。这里为了方便,
将“已经死亡”和“已经安乐死”合并成“未能存活”这个标签。数据导人之后,便可以使用
函数stocGradAscentl()来计算回归系数向量。这里可以自由设定迭代的次数,例如在训练集
上使用500次迭代,实验结果表明这比默认迭代150次的效果更好。在系数计算完成之后,导人测
试集并计算分类错误率。整体看来,colicTest()具有完全独立的功能,多次运行得到的结果
可能稍有不同,这是因为其中有随机的成分在里面。如果在stocGradAscentl()函数中回归系
数已经完全收敛,那么结果才将是确定的。
'''
def colicTest():
frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[21]))
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print "the error rate of this test is: %f" % errorRate
return errorRate
'''
最后一个函数是multiTest(),其功能是调用函数colicTest()10次并求结果的平均值。
从上面的结果可以看到,10次迭代之后的平均错误率为35%。事实上,这个结果并不差,因
为有30%的数据缺失。当然,如果调整colicTest()中的迭代次数和stochGradAscentl()中
的步长,平均错误率可以降到20%左右。
'''
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print "after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests))
五、参考文献
[1] Logisticregression (逻辑回归) 概述
[2] LogisticRegression 之基础知识准备
[3] LogisticRegression