Matlab并行运算
今天搞了一下matlab的并行计算,效果好的出乎我的意料。
本来CPU就是双核,不过以前一直注重算法,没注意并行计算的问题。今天为了在8核的dell服务器上跑程序才专门看了一下。本身写的程序就很容易实现并行化,因为beamline之间并没有考虑相互作用。等于可以拆成n个线程并行,要是有550核的话,估计1ms就算完了。。。
先转下网上找到的资料。
一、Matlab 并行计算原理梗概Matlab的并行计算实质还是主从结构的分布式计算。当你初始化Matlab并行计算环境时,你最初的Matlab进程自动成为主节点,同时初始化多个(具体个数手动设定,详见下文)Matlab计算子节点。Parfor的作用就是让这些子节点同时运行Parfor语句段中的代码。Parfor运行之初,主节点会将Parfor循环程序之外变量传递给计算子节点。子节点运算过程时互不干扰,运算完毕,则应该有相应代码将各子节点得到的结果组合到同一个数组变量中,并返回到Matlab主节点。当然,最终计算完毕应该手动关闭计算子节点。
二十六、初始化 Matlab 并行计算环境这里讲述的方法仅针对多核机器做并行计算的情况。设机器的CPU核心数量是CoreNum双核机器的CoreNum2,依次类推。CoreNum以不等于核心数量,但是如果CoreNum小于核心数量则核心利用率没有最大化,如果CoreNum大于核心数量则效率反而可能下降。因此单核机器就不要折腾并行计算了,否则速度还更慢。下面一段代码初始化Matlab并行计算环境:
%Initialize Matlab Parallel Computing Enviornment by Xaero | Macro2.cn
CoreNum=2; %设定机器CPU核心数量,我的机器是双核,所以CoreNum=2
if matlabpool('size')<=0 %判断并行计算环境是否已然启动
matlabpool('open','local',CoreNum); %若尚未启动,则启动并行环境
else
disp('Already initialized'); %说明并行环境已经启动。
end
运行成功后会出现如下语句:
Starting matlabpool using the 'local' configuration ... connected to 2 labs.
如果运行出错,按照下面的办法检测:
首先运行:
matlabpool size
如果出错,说明你没有安装Matlab并行工具箱。确认安装了此工具箱后,运行:
matlabpool open local 2;
如果出错,证明你的机器在开启并行计算时设置有问题。请联系MathWorks的售后服务。
二十七、终止 Matlab 并行计算环境
用上述语句启动Matlab并行计算环境的话,在你的内存里面有CoreNum个Matlab进程存在,每个占用内存都在百兆以上。(可以用Windows任务管理器查看),故完成运行计算后可以将其关闭。关闭的命令很简单:
matlabpool close
二十八、Matlab 做 Monte Carlo 并行的算法Matlab并行计算比较特别。下图节选自Matlab并行计算工具箱用户手册。这个列表告诉你Matlab如何处理Parfor并行计算程序段中的各种变量。所以写代码时要注意不少问题,否则写出的并行代码可能还不如非并行的代码快。
这里我推荐大家用Matlab写Monte Carlo并行代码时按照以下注意事项来写:
1.将Monte Carlo模拟过程中不会改变的参数都写在Parfor循环块外面
2.生成随机数、计算f(x)等过程都写在Parfor里面
3.不要将V0结果传递出Parfor,而是直接计算出V0的均值、方差传递出parfor。
4.最后用数学公式将传递出Parfor的V0的均值方差组合计算成最终结果
这些事项如何体现到程序中请参照示例代码文件并结合视频教程学习。这样的并行办法简单易行,对原始程序没有太大的改动,同时传递变量耗费时间也较少,效率比较高。
另外一个问题就是并行代码做模拟的次数问题。我们要达到用非并行的代码做N此模拟所能得到结果的精确程度,在核心为CoreNum并行代码中,Parfor语句段中只要做N/CoreNum次即可达到。
二十九、将例子改写为并行代码附件中的pareg1.m,……,pareg5.m五个文件分别是前一章五个例子的并行代码。这里需要提到的是,这五个代码文件都是用向量化的代码编写。原因在于,在前一章大家都看到了,向量化的代码比循环语句代码一般快几十甚至上千倍,所以要提高速度,向量化代码是最重要的优化方法,并行计算倒是其次。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
刚才试了一下,我使用的MATLAB2010可以多核运行的。需要多核多线程跑的算法,在之前要让matlab在本地建立4个“实验室”(我的机器是4核,所以是4个)
>> matlabpool local 4
Starting matlabpool using the 'local' configuration ... connected to 4 labs.
显示正在进行多核配置,一会说,连接到4个“实验室”。我理解就是在本地虚拟出4台可以运行matlab的工作站,这样用分布式计算工具箱可以进行并行计算(matlabpool这个命令好像是在并行计算工具箱里的)。观察windows任务管理器,可以发现一共有5个MATLAB.exe进程。其中一个占内存较多的,我理解是主控的,他基本不干活,只负责分配,进行计算时他的cpu占用率只有1~2%,剩下四个进程专门用来计算的,跑起来各占cpu 25%左右。看上去还是每个matlab进程单核运算,但是一下开4个进程,所以能把cpu用满。
如果后续还需要多核运算,就直接用parfor好了,不用每次都用matlabpool命令。那个配置一次就好。
算完了,不再跑了,临退出时关闭配置就行。
>> matlabpool close
Sending a stop signal to all the labs ... stopped.
下面是我一个M文件的程序,测测4核并行计算和单核计算的差距,很简单。
function testtime
runtimes = 1e9;
dummy1 = 0;
dummy2 = 0;
%matlabpool local 4
tic
%for x= 1:runtimes;
parfor x= 1:runtimes;
dummy1 = dummy1 + x;
dummy2 = 2 * x + 1;
end
toc
plot([1 2], [dummy1, dummy2]);
第一次用普通for语句,单核跑,6.09秒
>> testtime
Elapsed time is 6.094267 seconds.
第二次用parfor语句,4核跑,1.63秒
>> matlabpool local 4
Starting matlabpool using the 'local' configuration ... connected to 4 labs.
>> testtime
Elapsed time is 1.631350 seconds.
>> matlabpool close
加速比 6.09 / 1.63 = 3.736,将近4倍(还有开销吧),还比较可观。
Parallel Computing Toolbox是一个matlab2011开始提供的组件,用于提供交互式的并行计算功能
一、运用的场合
很多应用程序中包含多个重复的代码部分,这些代码可能有多次循环迭代,也可能只有少量的循环迭代,但他们只是重复次数与输入参数的区别,对于处理这样的数据,并行计算是一个理想的方法,并行循环的唯一限制是每个循环间没有相互的依赖关系
当然,对于相互依赖的程序代码,也有可以实现并行计算的技巧
对于MATLAB,你可以选择运行一个庞大的批处理程序,也可以选择将他们拆分成多个任务由多个远程的计算机并行地执行,那将会极大的增加运行效率
同时,如果要处理的数据过于庞大,并行计算的性能也将明显优于异步的计算与处理
二、并行计算方案简介
-
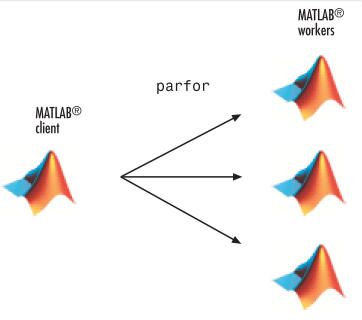
交互运行一个循环程序
在这个例子中,我们只是要学习怎么将一个简单的for循环程序变成一个并行执行的程序,for循环中处理的数据量以及for循环的迭代次数都是很小的,因此,很难在这个例子中体现出并行计算的效率优势
1、假设你的代码中包含下面一个显示正弦波形的for循环:
for i=1:1024
A(i) = sin(i*2*pi/1024);
end
plot(A)
2、为了能够使用matlab提供的交互式工具,你需要首先打开matlabpool,这个组件可以运行在你的本地计算机上,也可以运行在多个远程计算机上
matlabpool open local 3
3、在matlabpool上,通过使用parfor关键字,你可以将你的代码修改为并行运行的程序:
parfor i=1:1024
A(i) = sin(i*2*pi/1024);
end
plot(A)
4、当程序运行结束,我们要使用下面一条指令关闭matlabpool,并且释放被占用的处理器或
两段代码唯一的区别是将关键字由for变为了parfor,而两段代码的执行结果也是极其相似的
但是,因为这个程序中,每次循环迭代都只是参数不同,之间并没有依赖关系,因此,每次迭代并不一定运行于同一个处理器上,通过parfor关键字声明,每一个迭代可能在多个处理器或多个计算机上并行执行,但并没有任何保证执行顺序的技术,因此,A(900)可能在A(400)之前运行
-
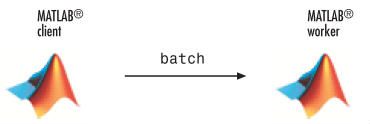
运行一个批处理作业(batch job)
首先,先介绍一下matlab中的批处理作业的概念,使用批处理命令可以让matlab分担某个任务一段时间,下面是一个for循环的例子
1、首先使用下面的命令创建一个脚本
edit mywave
2、在 MATLAB Editor 中键入下面的代码,完成for循环显示函数
for i=1:1024
A(i) = sin(i*2*pi/1024);
end
3、保存并关闭 MATLAB Editor
4、在Matlab命令窗口中输入批处理命令来让脚本在单独的Matlab工作间中执行
job = batch('mywave')
5、batch命令不会阻塞matlab,所以你必须等待工作的完成然后去查看他的结果
wait(job)
6、使用load命令可以把工作间中的变量传输到客户端前
load(job, 'A')
plot(A)
7、工作完成后,要记得调用下面的命令清除数据
destroy(job)
上面的代码将matlab的工作间与客户端之间相分开,很大的提高了效率
-
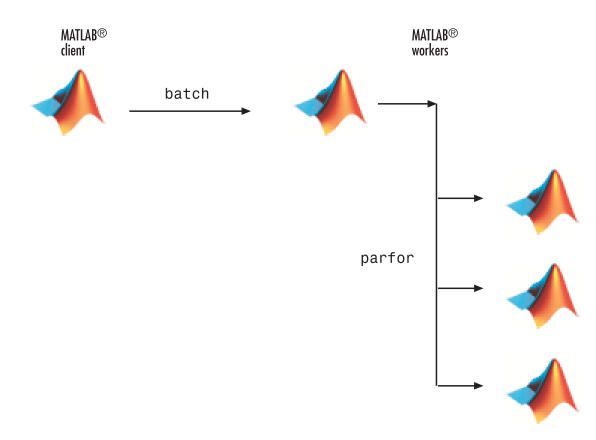
运行一个交互的批处理作业(batch job)
下面的例子将上面的两个例子结合在一起,完成parfor的batch job
1、在MATLAB Editor中编辑你的脚本
edit mywave
2、如下修改你的脚本
parfor i=1:1024
A(i) = sin(i*2*pi/1024);
end
3、保存并退出MATLAB Editor
4、和前面一样,我们运行这个脚本,但是这一次我们要使用一个MATLAB pool 来运行这个脚本
job = batch('mywave', 'matlabpool', 3)
5、和之前一样,我们要去查看结果需要执行下面的代码
wait(job)
load(job, 'A')
plot(A)
6、工作完成后,要记得调用下面的命令清除数据
destroy(job)
上面的这段代码将一个批处理工作分给了三个不同的工作间来协作完成
相信很多朋友在利用matlab进行计算时,会遇到循环次数过大,或者是单次计算量过大的问题,比如需要计算的数值阵列数据量过大,利用传统的编程方式,跑一次程序几个小时,都要等的急死了是不是呢?如果遇到这种情况,则可以尝试一下MATLAB并行计算,传统的计算方式都是串行计算。并行计算之所以可行,取决于两方面因素:a)现在大家的计算机是多核的,至少也是双核了吧,有的可能8核都有,这是很重要的硬件基础。b)MATLAB本身提供了很好的并行计算函数,加上你的聪明智慧,设计合理的软件,这样就有了软件基础了。
-
并行计算的优势是什么?
以自己的经验来看,MATLAB并行计算真是很厉害的,通过对原始程序很简单的改动,就能节省很多时间。我给出一个很简单的例子,说明并行计算的优势所在。例如一个遗传算法的MATLAB程序,通常的计算运行方式需要2个小时得到结果,那如果用一台双核的机器并行计算呢?理论上1个小时就可以跑完。那如果是用一台8核的计算机,就只是一刻钟(15分钟)了。而且并行计算可以配合分布式计算服务,同时调动若干台计算机同时工作,把刚才的程序计算时间缩短到分分钟绝对不是难事啊。
-
如何启动MATLAB并行计算?
以单台双核计算机为例。首先打开MATLAB命令窗口,输入matlabpool open就OK了。如图所示:

这样,就相当于将一台计算机的两个核心,当做两台机器用啦。接下来是编程序实现的方法。
-
MATLAB并行计算的模式有几种?
主要是两种:parfor模式和spmd模式。两种模式的应用都很简单。第一个中,parfor其实就是parallel+for简化而来,顾名思义啊,就是把原来程序中的for循环中的关键字forg改为parfor就OK啦。不过这是很初步的介绍,限于篇幅不能详细展开了,详细的可以用输入命令help parfor查看,如图:

-
同样地,可以适用于spmd模式。
-
程序举例:例如很简单的一个程序:
tic
%传统方式计算
c1=1;
for i = 1:500
c1 = c1+max(eig(rand(i,i)));
end
t1 = toc;
matlabpool open;
%parfor并行方式计算
tic
c2=1;
parfor ii = 1:500
c2 = c2+max(eig(rand(ii,ii)));
end
t2 = toc;
matlabpool close;
display(strcat('parfor并行计算时间:',num2str(t2),'秒'));
display(strcat('客户端串行计算时间:',num2str(t1),'秒'));
分别用传统方式算和parfor算,时间区别如下图所示:

这只是用双核计算的效果,如果是4核心8核心,效果要好的多啦,需要用MATLAB的童鞋不妨试试看咯。
-
关闭并行计算模式。
不想用了?送一个命令进去就关了,估计你已经猜到那即是:matlabpool close.如图所示:
早日学会哦!
Matlab并行运算
目前,新购置的电脑大部分都是多核的了,使用Matlab进行大量计算时如何有效利用多核呢?Matlab目前版本已经比较好的支持多核并行运算了。是用的Matlab版本是R2007b。电脑是双核的。
先简单试试:
>> matlabpool local 2
Submitted parallel job to the scheduler, waiting for it to start.
Connected to a matlabpool session with 2 labs.
显示正在进行多核配置,然后,提示连接到2个“实验室”(labs)。我这也理解的:本地虚拟出2台可以运行matlab的工作站,这样用分布式计算工具箱可以进行并行计算(matlabpool这个命令好像是在并行计算工具箱里的)。
>> testParallel
Elapsed time is 7.750534 seconds.
这里运行testParallel函数,已经开辟了2个labs,为了进行多核并行运算,testParallel中,要用parfor代替原来的for循环。
在运行这个时,观察windows任务管理器,可以发现一共有3个MATLAB.exe进程。其中一个占内存较多的,应该是主控的,他基本不干活,只负责分配,进行计算时他的cpu占用率只有1~2%,剩下两个进程专门用来计算的,跑起来各占cpu 49%左右。看上去还是每个matlab进程单核运算,但是一下开2个进程,所以能把cpu用满。当运行完testParallel后,三个进程的cpu都立刻降为1%左右了。
>> matlabpool close
Sending a stop signal to all the labs...
Waiting for parallel job to finish...
Performing parallel job cleanup...
Done.
当要关闭开辟的2个labs时,使用matlabpool close关闭即可。
代码及使用时间对比如下表:
function testParallel
%非并行
% matlabpool local 2
tic
total=10^5;
for (i=1:total)
ss(i)=inSum;
end
plot(ss);
toc
% matlabpool close
function [s]=inSum
x=abs(round(normrnd(50,40,1,1000)));
s=sum(x);
function testParallel
%并行
matlabpool local 2
tic
total=10^5;
parfor (i=1:total)
ss(i)=inSum;
end
plot(ss);
toc
matlabpool close
function [s]=inSum
x=abs(round(normrnd(50,40,1,1000)));
s=sum(x);
70.471469/7.750534 = 9.0925,并行与否的时间比竟然是9倍,足以表明,在Matlab中使用多核并行运算给我们带来很多好处。
转载请注明出处http://hi.baidu.com/webas/item/438ed30e364e28cf905718d8。
先简单试试:
>> matlabpool local 2
Submitted parallel job to the scheduler, waiting for it to start.
Connected to a matlabpool session with 2 labs.
显示正在进行多核配置,然后,提示连接到2个“实验室”(labs)。我这也理解的:本地虚拟出2台可以运行matlab的工作站,这样用分布式计算工具箱可以进行并行计算(matlabpool这个命令好像是在并行计算工具箱里的)。
>> testParallel
Elapsed time is 7.750534 seconds.
这里运行testParallel函数,已经开辟了2个labs,为了进行多核并行运算,testParallel中,要用parfor代替原来的for循环。
在运行这个时,观察windows任务管理器,可以发现一共有3个MATLAB.exe进程。其中一个占内存较多的,应该是主控的,他基本不干活,只负责分配,进行计算时他的cpu占用率只有1~2%,剩下两个进程专门用来计算的,跑起来各占cpu 49%左右。看上去还是每个matlab进程单核运算,但是一下开2个进程,所以能把cpu用满。当运行完testParallel后,三个进程的cpu都立刻降为1%左右了。
>> matlabpool close
Sending a stop signal to all the labs...
Waiting for parallel job to finish...
Performing parallel job cleanup...
Done.
当要关闭开辟的2个labs时,使用matlabpool close关闭即可。
代码及使用时间对比如下表:
| function testParallel %非并行 % matlabpool local 2 tic % matlabpool close function [s]=inSum |
function testParallel %并行 matlabpool local 2 tic matlabpool close function [s]=inSum |
| Elapsed time is 70.471469 seconds. | Elapsed time is 7.750534 seconds. |
70.471469/7.750534 = 9.0925,并行与否的时间比竟然是9倍,足以表明,在Matlab中使用多核并行运算给我们带来很多好处。
首先,LZ要搞清楚自己的电脑是几个核的。如果不是多核的,那就没有办法进行多核运算了。现在大多数电脑是双核的,也有一些高级一些的是四核。
如果是双核的,进行多核运算前,写上代码:
matlabpool local 2;
四核的话写上代码:
matlabpool local 4;
依此类推。
多核运算完以后,要记得关闭多核运算。写上代码:
matlabpool close;
要记住使用matlabpool和parfor缺一不可。开启了matlabpool,还是用for做循环的话,是无法回快速度的。
我没有让你把所有的for循环都改成parfor循环.我的意思是多核运算只能加速parfor的部分.
刚才试了一下,我使用的MATLAB2010可以多核运行的。需要多核多线程跑的算法,在之前要让matlab在本地建立4个“实验室”(我的机器是4核,所以是4个)>> matlabpool local 4
Starting matlabpool using the 'local' configuration ... connected to 4 labs.
显示正在进行多核配置,一会说,连接到4个“实验室”。我理解就是在本地虚拟出4台可以运行matlab的工作站,这样用分布式计算工具箱可以进行并行计算(matlabpool这个命令好像是在并行计算工具箱里的)。观察windows任务管理器,可以发现一共有5个MATLAB.exe进程。其中一个占内存较多的,我理解是主控的,他基本不干活,只负责分配,进行计算时他的cpu占用率只有1~2%,剩下四个进程专门用来计算的,跑起来各占cpu 25%左右。看上去还是每个matlab进程单核运算,但是一下开4个进程,所以能把cpu用满。
如果后续还需要多核运算,就直接用parfor好了,不用每次都用matlabpool命令。那个配置一次就好。
算完了,不再跑了,临退出时关闭配置就行。
>> matlabpool close
Sending a stop signal to all the labs ... stopped.
下面是我一个M文件的程序,测测4核并行计算和单核计算的差距,很简单。
function testtime
runtimes = 1e9;
dummy1
dummy2 = 0;
%matlabpool local 4
tic
%for x= 1:runtimes;
parfor x= 1:runtimes;
dummy1 = dummy1 + x;
dummy2 = 2 * x + 1;
end
toc
plot([1 2], [dummy1, dummy2]);
第一次用普通for语句,单核跑,6.09秒
>> testtime
Elapsed time is 6.094267 seconds.
第二次用parfor语句,4核跑,1.63秒
>> matlabpool local 4
Starting matlabpool using the 'local' configuration ... connected to 4 labs.
>> testtime
Elapsed time is 1.631350 seconds.
>> matlabpool close
加速比 6.09 / 1.63 = 3.736,将近4倍(还有开销吧),还比较可观。
由于处理器时钟频率的限制,增加核并不意味着是计算性能的提高。为了充分利用新的多核硬件在性能上的优势,软件的基层结构需要向并行计算转换。MATLAB并行计算工具箱就是这种需求的产物,它能很好地实现在多核系统上进行并行运算。文章以典型的数值计算问题为例描述如何使用基本的两种并行运算方式:线程和并行for循环。
典型数值计算问题
为了举例说明这两种方法,我们使用MATLAB 测试一个有关Girko圆定律的假设。Girko圆定律的内容是:一个N×N的随机矩阵(它的元素服从正态分布)的特征值位于半径为的圆内。假设Girko圆定律能被修改应用到奇异值上。这个假设是合理的因为奇异值是一个变换了的矩阵的特征值。首先我们用MATLAB代码实现Girko圆定律的一个实例:
N = 1000;
plot(eig(randn(N)) / sqrt(N), ‘.’);
这段代码运行后得到图1,图上每个点代表复平面上一个特征值。注意所有的特征值都位于半径为1 ,圆心在轴的原点的圆内,特别指出的是结果与Girko圆定律是一致的,特征值的幅值没有超过矩阵维数的平方根。
图1 大小为1000的随机矩阵的特征值在半径为sqrt(1000)的圆内
为了将Girko定律应用到奇异值分解上,我们用MATLAB生成随机矩阵,然后估算它们的奇异值,看是否能基于数值计算阐明这个假设。我们用任意变量N计算max(svd(randn(N)))的值,然后在结果中寻找规律,而这个规律是可以用奇异值分解的理论解释的。
通过下面的循环产生正规随机矩阵,并计算它们的奇异值:
y = zeros(1000,1);
for n = 1:1000
y(n) = max(svd(randn(n)));
end
plot(y);
在单核计算机上运行这段循环代码时需要15分钟多的时间。为了减少计算时间,我们用线程和并行 for循环在多核计算机上运行这段循环代码,然后再来比较性能结果。
使用线程
线程是在多核计算机上进行并行计算的软件解决方案,但是需要记住的一点是多线程和多核处理器不是同一个概念。通常线程的数量和多核的数量一致时性能是最好的,但是也有线程比核少的情况。我们将通过实验去确定对于我们的计算所需的最佳的线程的个数。
运行上面的代码,并通过MATLAB界面属性窗口或者使用maxNumCompThreads()函数去调节线程的个数。图2 显示了不同线程数量对应的结果。除了时间,还有加速情况和并行效率。前者是多核执行时间与单核执行时间的比率,理想地,我们期望在N个核上能达到N倍。后者是加速倍数与核的个数的比率,理想地,我们期望能达到100%。
| 线程个数 |
运行循环所需时间 |
加速倍数 |
效率 |
| 1 |
902.6 |
1.00 |
100% |
| 2 |
867.2 |
1.04 |
52% |
| 3 |
842.3 |
1.07 |
35% |
| 4 |
862.3 |
1.05 |
26% |
图2 不同线程数量对应的代码性能
结果呈现混合型的特点。使用线程确实能提高计算的速度,但是在我们的例子,只有对svd()的调用是被并行计算的。这是因为MATLAB所支持的线程是有限制的:用户不能决定代码的哪部分进行并行运算。
一方面,我们使用多核在不改变代码的情况下加快了计算的速度。另一方面,当增加内核而并没有减少执行时间时就意味着是对成本的浪费。这个时候,我们需要另一种并行运算方法。
使用并行for循环
Parfor循环,即并行for循环,在简单计算中有大量循环语句时是非常有用的。使用Parfor需要并行计算工具箱的支持。图3 是用Parfor语句和前面代码的对比。
| y = zeros(1000,1); for n = 1:1000 y(n) = max(svd(randn(n))); end plot(y); |
y = zeros(1000,1); parfor n = 1:1000 y(n) = max(svd(randn(n))); end plot(y); |
图3 左边:原来的代码 右边:用parfor实现的循环语句
就像maxNumCompThreads()命令可以控制多核方法的并行运算,matlabpool命令能够控制parfor指令的并行行为。Matlabpool指令创建并行任务执行的环境,在此环境下并行for循环能够从MATLAB 的命令提示符交互执行。
Parfor循环在labs上执行,labs之间是能够交互的。像线程一样,labs在处理器核上执行,但是labs的数量并不一定与核的数量相匹配。另不同于线程,labs互相之间是不共享存储单元的。所以,它们能够运行在联网的独立的计算机上。但是,在我们的例子中,我们仅需要知道并行运算工具箱使得parfor有效地工作在一个多核系统上。每个核或本地worker能主导一个lab。
问题自然就出现了:改变代码值得吗?在我们的例子中,改变代码是值得的因为下面的表格清楚地表明了使用parfor的好处。
| Labs数量 |
运行循环所需时间 |
加速倍数 |
效率 |
| 1 |
870.1 |
1.00 |
100% |
| 2 |
487.0 |
1.79 |
89% |
| 3 |
346.2 |
2.51 |
83% |
| 4 |
273.9 |
3.17 |
79% |
图4 不同的lab数量对应的代码性能
从结果可以看出,对于此奇异值分解的计算,无论从加速情况还是效率,parfor的性能是优于多线程的。
不细究代码实现的细节,也有必要解释使用parfor带来的好处。例子中的代码最显著的特征是每个循环是独立的。独立性的特征使得parfor的应用很简单也很高效。使用parfor留给系统的唯一任务是分配循环任务到核执行并获取结果用于其他的运算。
值得说明的一点是parfor在随机数产生的问题上。在parfor循环中使用诸如randn()函数产生的矩阵与for循环中使用类似函数产生的矩阵并不一致,因为parfor循环的是已经被预定了的。在绝大多情况下,这种差异完全是可以接受的。
使用parfor有它的优点,但也有其局限性。例如,如果循环之间相互依赖,而且这种依赖能够通过代码分析得到,那么执行parfor循环就会得到错误的结果。如果这种依赖关系没有检测到,那么就会得到不正确的结果。下面的代码说明了这样的问题:
total = 0;
A = zeros(1000, 1);
parfor i = 1:100
total = total + i; % OK: this is ...
...a known reduction operation
A(i+1) = A(i) + 1; % error: ... ...loop iterations are dependent
end
利用parfor很容易计算total的表达式,但是对于第二个表达式,由于A(i+1)依赖于前一次循环得到的A(i),所以用parfor计算会产生问题。
让我们来更进一步地看看每次循环发生了什么:
Iteration 1: i = 1
A(2) = A(1) + 1 = 0 + 1 = 1
Iteration 2: i = 2
A(3) = A(2) + 1 = 1 + 1 = 2
Iteration 3: i = 3
A(4) = A(3) + 1 = 2 + 1 = 3
通过以上分析我们可以用下面的parfor循环的代码得到跟前面同样结果的代码:
parfor i = 1:10
A(i+1) = i;
end
扩展并行计算
MATLAB已经支持几种并行方法,其他的方法将逐渐在高版本中实现。
我们相信未来计算机将有越来越多的核。总是没过几年核的个数就翻倍,也意味着计算能力的翻倍。但是要利用好这种硬件的优势就需要正确的软件,而写正确的软件就需要正确的软件开发工具。MATLAB便旨在实现这种需求。
________________________________________
所需产品
-
MATLAB
-
Parallel Computing Toolbox
资源与示例
-
Using parfor to Run Loops in Parallel
-
Parallel Programming in MATLAB
文章
-
Eigenvalues and Condition Numbers of Random Matrices. Alan Edelman. Ph.D. thesis, Massachusetts Institute of Technology, May 1989.
-
Language Design for an Uncertain Hardware Future. Roy Lurie. HPCwire, September 28, 2007
-
Multiple Processors and Multiple Cores. Cleve Moler. The MathWorks News & Notes, June 2007