Hive
一、hive简介
1. Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL ),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL ,它允许熟悉 SQL 的用户查询数据。
2. Hive是SQL解析引擎,它将SQL语句转译成M/R Job然后在Hadoop执行(大部分的查询由 MapReduce 完成(包含 * 的查询,比如 select * from table 不会生成 MapRedcue 任务))。
3.Hive的表其实就是HDFS的目录/文件,按表名把文件夹分开。如果是分区表,则分区值是子文件夹名
二、hive架构
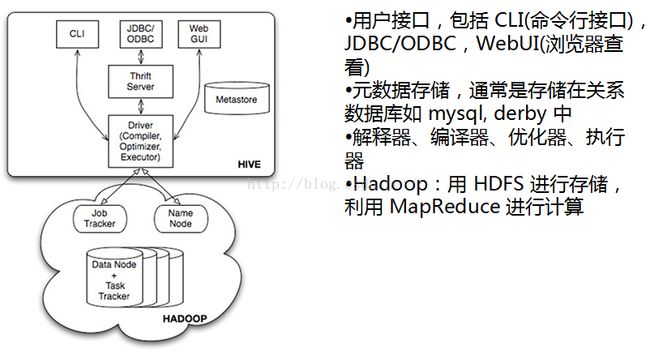
三、hive的metastore
1、metastore是hive元数据的集中存放地。metastore默认使用内嵌的derby数据库作为存储引擎
2、Derby引擎的缺点:一次只能打开一个会话(用户切换到不同目录下启动hive都会创建自己的MetaStore),不能多用户共享
3、使用Mysql作为外置存储引擎,多用户同时访问
四、hive与传统数据库
注意:由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的
五、hive的数据存储
Hive的数据存储基于Hadoop HDFS,没有专门的数据存储格式,存储结构主要包括:数据库、文件、表、视图,Hive默认可以直接加载文本文件(TextFile),还支持sequence file 、RC file,创建表时,指定Hive数据的列分隔符与行分隔符,Hive即可解析数据。
1、数据库
默认数据库"default",使用#hive命令后,不使用hive>use <数据库名>,系统默认的数据库。
可以创建一个新库hive > create database test_dw;
2、表
<1>Table 内部表
每一个 Table 在 Hive 中都有一个相应的目录存储数据。例如,一个表 test,它在 HDFS 中的路是user/hive/warehouse/test。 warehouse是在 hive-site.xml 中由 ${hive.metastore.warehouse.dir} 指定的数据仓库的目录,所有的 Table 数据(不包括 External Table)都保存在这个目录中。删除表时,元数据与数据都会被删除
例子:
创建表
hive>create table inner_table (key string);
加载数据
hive>load data local inpath '/root/inner_table.dat' into table inner_table;
<2>分区表
在hive中查询时一般会扫描整个表内容,会消耗很多时间做没必要的工作,因此出现了分区表!!
Partition 对应于数据库的 Partition 列的密集索引,在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中
例如:test表中包含 date 和 city 两个 Partition,则对应于date=20130201, city = bj 的 HDFS 子目录为/warehouse/test/date=20130201/city=bj
例子:
创建表
create table partition_table(rectime string,msisdn string) partitioned by(daytime string,city string) row format delimited fields terminated by '\t' stored as TEXTFILE;
加载数据到分区
load data local inpath '/home/partition_table.dat' into table partition_table partition (daytime='2013-02-01',city='bj');
增加、删除分区
alter table partition_table add(drop) partition (daytime='2013-02-04',city='bj')
<3>桶表
桶表是对数据进行哈希取值,然后与桶的数量取模。把数据放到对应的文件中。
创建表
create table bucket_table(id string) clustered by(id) into 3 buckets;(3个桶就是对应个文件)
加载数据
set hive.enforce.bucketing = true;
insert into table bucket_table select name from stu;
<4>外部表
(1)指向已经在 HDFS 中存在的数据,可以创建 Partition
(2)内部表 的创建过程和数据加载过程(这两个过程可以在同一个语句中完成),在加载数据的过程中,实际数据会被移动到数据仓库目录中;之后对数据对访问将会直接在数据仓库目录中完成。删除表时,表中的数据和元数据将会被同时删除;
外部表 只有一个过程,加载数据和创建表同时完成,并不会移动到数据仓库目录中,只是与外部数据建立一个链接。当删除一个 外部表 时,仅删除该链接
创建表
hive>create external table external_table1 (key string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' location '/home/external';
六、创建表
1、create语法来创建
create external table employee( name string, salary float, subordinates array<string>, deductions map<string,float>, address struct<street:string,city:string,state:string,zip:int> ) row format delimited fields terminated by '\t' collection items terminated by ',' map keys terminated by ':', lines terminated by '\n' stored as textfile location '/data';
data数据的格式是这样的:
![]()
2、由一个表创建另一个表
create table test1 like test2;
3、由其他表查询创建表
create table test as select name from test1;
七、加载数据
1、内表加载数据
(1)创建表时加载
create table newtable as select col1,col2 from oldtable;
(2)本地数据加载
load data local inpath 'localpath' [overwrite] into table tablename;
(3)hdfs数据加载
load data inpath 'hdfspath' [overwrite] into table tablename;
注意:此操作是移动数据,hdfs上的数据将会移动到数据仓库
(4)由查询语句加载数据
insert [overwrite | into] table tablename
select col1,col2 from table where...........
2、外表数据加载
(1)创建表时指定数据位置
create external table tablename() .........location 'path';
(2)查询插入,同内表
注意:这个时候外表在数据仓库中是存在的,只不过这种方式对于外表来说没有什么意义!
3、hive分区表数据加载
(1)本地数据加载
load data local inpth 'localpath' [overwrite] into table tablename partition(pn=‘’);
(2)加载hdfs数据
load data inpath 'hdfspath' [overwrite] into table tablename partition(pn='')
(3)由查询语句加载数据
insert [overwrite] into table tablename partion(pn='')
select col1,col2 from table where.....
八、数据的导出方式
1、hadoop命令的方式
hadoop fs -get[text] /user/hive/warehouse/tablename/* /hive_data(本地路径)
2、通过insert的方式
insert overwrite [local] directory '/data' row format delimited fields terminated by '\t'
select col from tablename;
九、动态分区
*不需要为不同的分区添加不同的插入语句
*分区不确定,需要从数据中获取
1、必须设置的参数
set hive.exec.dynamic.partition=true;//使用动态分区
set hive.exec.dynamic.partition.mode=nostrick;//无限制模式,如果是strict,则比不有一个静态分区,且放在最前面
2、创建动态分区表及其插入数据
十、表属性操作
1、修改表名
alter table tablename rename to new_tablename;
2、修改列名
alter table tablename change column c1 c2 string;
3、 增加列
alter table tablename add columns (c1 string,c2 long);
4、修改分隔符
alter table tablename [partition(dt='xxxxx')] set serdeproperties ('field.delim'='\t');
5、修改location
alter table tablename [partition()] set location 'path';
十一、hive高级查询
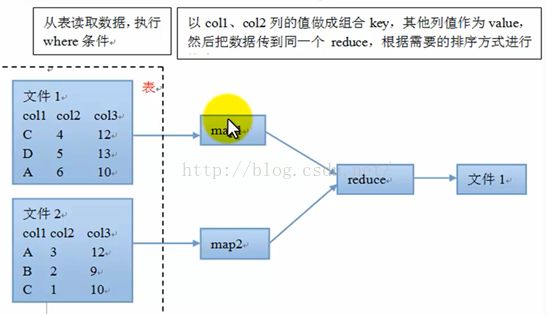
1、order by
例子:select col1,col2 from tablename where...
order by col1,col2 [asc | desc];
注意:
* 可以有多列排序,默认按照字典排序
* order by为全局排序
* order by需要reduce操作,且只有一个reduce
mapreduce原理:
2、group by
*按照某些字段的值进行分组,有相同值放在一起(可以拿来去重操作)
样例:
select col1,[col2] from tablename
where....
group by col1,[col2]
注意:select 后面非聚合列必须出现在group by中
特征:
使用了reduce操作,受限于reduce数量,可以设置参数set mapred.reduce.tasks=n;
mapreduce原理:
3、Join
*join等值连接、left outer join左外连接、right outer join右外连接
例子:

select a.col,a.col2,b.col4 from a join b on a.col=b.col3
输出:
mapreduce原理:

4、mapjoin(join的优化操作,不走reduce)
*在map端把小标加载到内存,然后读取大表,和内存中的小表完成连接操作
优缺点:
优点:不消耗reduce资源
缺点:占用部分内存,因为每个map都会加载一次小表;生成较多小文件
配置参数:
select /*+mapjoin(n)*/ m.col,m.col2,n.col3 from m join n on m.col=n.col
mapreduce原理:
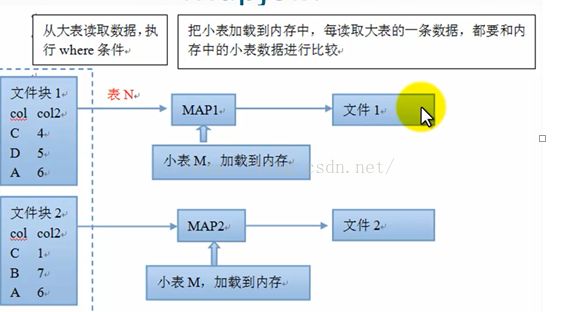
mapjoin的使用场景:
*有一张很小的表
*不等值连接操作
5、distribute by 和sort by
*distribute by分散数据
distribute by col,按照col列把数据分散到不同的reduce
*sort by排序
sort by col,对每个reduce局部对col排序
*样例
set mapred.reduce.tasks=3;//设置reduce数量为3
select col1,col2 from m
distribute by col1
sort by col1 asc,col2 asc;
*对比

mapreduce原理:

6、union all
*多个表的数据合并成一个表
样例:
select col
from(select a as col from t1
union all
select b as col from t2
)tmp;
十二、hive函数
1、内置函数
http://blog.csdn.net/wisgood/article/details/17376393
2、hive自定义函数
<1>UDF

例子:
写一个自定义函数,要求能对某一列的数据对某一个数比大小,返回True,false
package com.hive.hadoop;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
public class udfTest extends UDF{
public boolean evaluate(Text t1,Text t2)
{
if(t1==null||t2==null)
return false;
double d1=Double.parseDouble(t1.toString());
double d2=Double.parseDouble(t2.toString());
if(d1>d2)
return true;
else
return false;
}
}
Hive执行add jar:
add jar /function.jar
Hive执行创建模板函数
create temporary function bigthan as ‘com.hive.hadoop.udfTest’
Hql中执行
Select col1,col2 ,bigthan(col2,5) from tablename;
<2>UDAF

例子:在上例的基础之上,统计一下大于基数的个数
package com.hive.hadoop;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.parse.SemanticException;
import org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.typeinfo.TypeInfo;
import org.apache.hadoop.io.LongWritable;
public class CountBigThan extends AbstractGenericUDAFResolver{
//对参数进行判断
@Override
public GenericUDAFEvaluator getEvaluator(TypeInfo[] paramaters)
throws SemanticException {
if(paramaters.length!=2)
{
throw new UDFArgumentTypeException(paramaters.length-1,
"Exactly two argument is expected.");
}
return new GenericUDAFCountBigThanEvaluator();
}
//这个类来处理逻辑
public static class GenericUDAFCountBigThanEvaluator extends GenericUDAFEvaluator{
private LongWritable result;
private PrimitiveObjectInspector inputOI1;
private PrimitiveObjectInspector inputOI2;
//参数检查函数,每个阶段相关方法执行之前都会执行此函数
//map阶段:parameters长度与udaf输入的参数个数有关
//reduce阶段:parameters长度为1
@Override
public ObjectInspector init(Mode m, ObjectInspector[] parameters)
throws HiveException {
super.init(m, parameters);
//最终结果变量
result=new LongWritable(0);
//把原始参数转化一下,方便后面的通用类型转化
inputOI1=(PrimitiveObjectInspector)parameters[0];
if(parameters.length>1)
{
inputOI2=(PrimitiveObjectInspector)parameters[1];
}
return PrimitiveObjectInspectorFactory.writableLongObjectInspector;
}
//此方法在map执行,用来缓存临时的值
@Override
public AggregationBuffer getNewAggregationBuffer() throws HiveException {
CountAgg agg=new CountAgg();//缓存一个long类型的变量(值是1),用来计数;需要重新定义一个类
//重置,需要再次使用的时候要重置为0
reset(agg);
return agg;
}
@Override
public void iterate(AggregationBuffer agg, Object[] par)
throws HiveException {
assert(par.length==2);
if(par==null||par[0]==null||par[1]==null)
return;
double base=PrimitiveObjectInspectorUtils.getDouble(par[0], inputOI1);
double tmp=PrimitiveObjectInspectorUtils.getDouble(par[1], inputOI2);
if(base>tmp)
((CountAgg)agg).count++;
}
@Override
public Object terminatePartial(AggregationBuffer agg)
throws HiveException {
result.set(((CountAgg)agg).count);
return result;
}
@Override
public void merge(AggregationBuffer agg, Object partial)//合并,这个partial是上面函数返回的对象
throws HiveException {
if(partial!=null)
{
long p=PrimitiveObjectInspectorUtils.getLong(partial, inputOI1);
((CountAgg)agg).count+=p;
}
}
@Override
public Object terminate(AggregationBuffer agg) throws HiveException {
result.set(((CountAgg)agg).count);
return result;
}
//重置方法
@Override
public void reset(AggregationBuffer CountAgg) throws HiveException {
CountAgg agg=(CountAgg)CountAgg;
agg.count=0;
}
//新建类
public static class CountAgg implements AggregationBuffer{
long count;
}
}
}
Mode枚举类:


查看源码:
src\ql\src\java\org\apache\hadoop\hive\ql\udf\generic