spring(10)通过spring 和 JDBC征服数据库
【0】README
1)本文部分文字描述转自:“Spring In Action(中/英文版)”,旨在review “spring(10)通过spring 和 JDBC征服数据库” 的相关知识;
【1】 spring 的数据访问哲学
1)intro:spring的目标之一是允许我们在开发应用程序的时候,能够遵循面向对象原则中的“针对接口编程”;
2)为了避免持久化的逻辑分散到应用的各个组件中,最好将数据访问的功能放到一个或多个专注于此项任务的组件中。这样的组件通常称为数据访问对象(data accwss object,DAO) 或 Repository;(干货——引入了 DAO 和 Repository)
3)为了避免应用与特定的数据访问策略耦合在一起,编写良好的 Repository应该以接口的方式暴露功能,下图展现了设计数据访问层的合理方式:
 (t3)
(t3)
【1.2】数据访问模板化
1)intro:spring将数据访问过程中固定的和可变的部分明确划分为两个不同 的类: 模板(template) 和 回调(callback);模板管理过程中固定的部分,而回调处理自定义的数据访问代码。下图展现了这两个类的职责:(干货——引入了模板和回调)
(t4)
2)针对不同的持久化平台,spring 提供了多个可选的模板。如果直接使用 JDBC,那你可以选择 JdbcTemplate。如果你希望使用对象关系映射框架,那 HibernateTemplate 或 JpaTemplate 可能会适合你。下表列出了 spring 所提供的所有数据访问模板及其用途:
 (t5)
(t5)
Attention)spring所支持的大多数持久化功能都依赖于 数据源。因此,在声明模板和 Repository之前,需要在spring 中配置一个 数据源用来连接数据库;
【2】配置数据源
1)intro:spring 提供了在 spring上下文中配置数据源bena 的多种方式:
way1)通过JDBC 驱动程序定义的数据源;way2)通过JNDI 查找的数据源;way3)连接池的数据源;
【2.1】使用JNDI 数据源
1)intro to jndi :http://blog.csdn.net/pacosonswjtu/article/details/51644550
2)利用spring,可以像使用 spring bean 那样配置 JNDI 中数据源的引用并将其装配到需要的类中;
3)使用 java配置 将 JNDI数据源装配到需要的类中:(for spec info ,please visit tomcat中配置jndi数据源以便spring获取)
@Bean // 使用JNDI 数据源.
public DataSource dataSource() {
JndiTemplate jndiTemplate = new JndiTemplate();
DataSource dataSource = null;
try {
dataSource = (DataSource) jndiTemplate.lookup("java:comp/env/jdbc/spring");
} catch (NamingException e) {
e.printStackTrace();
}
return dataSource;
}
【2.2】使用数据源连接池(strongly recommended)
1)intro:直接在spring中配置数据源,但spring并没有提供数据源连接池的实现,但可以有多项可用方案:(schema)
scheme1)Apache Commons DBCP(http://commons.apache.org/proper/commons-dbcp/configuration.html)scheme2)c3p0(https://sourceforge.net/projects/c3p0/)scheme3)BoneCP(http://www.jolbox.com/)
2)看个荔枝:配置DBCP BasicDataSource:
@Bean
public BasicDataSource getDataSource() {
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/t_spring");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
3)BasicDataSource的连接池配置属性如下所示:
 (t6)
(t6)
【2.3】基于JDBC 驱动的数据源
1)intro:在spring中,通过JDBC驱动定义数据源是最简单的配置方式,spring提供了3个这样的数据源类以供选择:
type1)DriverManagerDataSource:在每个连接请求时都会返回一个新建的连接。与 DBCP 的 BasicDataSource 不同,由DriverManagerDataSource 提供的连接并没有进行池化管理;(干货——引入了池化管理)type2)SimpleDriverDataSource:它直接使用 JDBC驱动,来解决再特定环境下的类加载问题,这样的环境包括 OSGi 容器;type3)SingleConnectionDataSource: 在每个连接请求时都会返回同一个的连接。尽管 SingleConnectionDataSource不是严格意义上的连接池数据源,但是你可以将其视为只有一个连接的池;
【3】在spring中使用 JDBC
【3.2】使用 JDBC模板
1)spring将数据访问的样本代码抽象到 模板类中,spring为jdbc提供了3个模板类选择:分别是 JdbcTemplate, NamedParameterJdbcTemplate 和 SimpleJdbcTemplate(已经被弃用),而原书作者推荐了 JdbcTemplate;(干货——原书作者推荐了 JdbcTemplate)
2)intro to JdbcTemplate:最基本的spring jdbc模板,支持简单的JDBC数据库访问功能以及基于索引参数的查询;
【3.2.1】使用 JdbcTemplate来插入数据
1)为了使其正常工作,只需要为其设置 DataSource就可以了;
(for org.springframework.jdbc.core.JdbcOperations API , 参见 JdbcTemplate API)
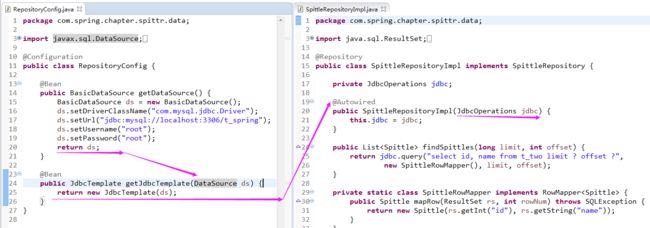
@Configuration
public class RepositoryConfig {
@Bean
public BasicDataSource getDataSource() {
BasicDataSource ds = new BasicDataSource();
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUrl("jdbc:mysql://localhost:3306/t_spring");
ds.setUsername("root");
ds.setPassword("root");
return ds;
}
@Bean
public JdbcTemplate getJdbcTemplate(DataSource ds) {
return new JdbcTemplate(ds);
}
}
2)使用JdbcTemplate 来读取数据
@Repository
public class SpittleRepositoryImpl implements SpittleRepository {
private JdbcOperations jdbc;
@Autowired
public SpittleRepositoryImpl(JdbcOperations jdbc) {
this.jdbc = jdbc;
}
public List<Spittle> findSpittles(long limit, int offset) {
return jdbc.query("select id, name from t_two limit ? offset ?",
new SpittleRowMapper(), limit, offset);
}
private static class SpittleRowMapper implements RowMapper<Spittle> {
public Spittle mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Spittle(rs.getInt("id"), rs.getString("name"));
}
}
@Override
public Spittle findSpittle(int id) {
return jdbc.queryForObject("select id,name,address from t_two where id=?",
new RowMapper<Spittle>() { // �����ڲ���
@Override
public Spittle mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Spittle(rs.getInt("id"), rs.getString("name"),
rs.getString("address"));
}
},
id);
}
@Override
public int getItemSum() {
return (int) jdbc.queryForObject("select count(*) as item_sum from t_two", new RowMapper<Object>() {
@Override
public Object mapRow(ResultSet rs, int rowNum) throws SQLException {
return rs.getInt("item_sum");
}
});
}
}
对以上代码的分析(Analysis):这个findOne()方法 使用了 JdbcTemplate.queryForObject() 方法来从数据库查询 Spitter;queryForObject() 方法有三个参数:
parameter1)String对象:包含了要从数据库中查找数据的SQL;parameter2)RowMapper对象:用来从 ResultSet 中提取数据并构建域对象;parameter3)可变参数列表:列出了要绑定到查询上的索引参数值;(Prepared Statement==预备语句)
Attention)值得注意的是 SpitterRowMapper对象中,它实现了 RowMapper接口。对于查询返回的每一行数据,JdbcTemplate 将会调用 RowMapper.mapRow()方法,并传入一个 ResultSet 和 包含行号的整数。在 SpitterRowMapper.mapRow()方法中,我们创建了 Spitter对象并将 ResultSet中的值填充进去;
【3.2.2】使用命名参数
1)intro:命名参数可以赋予SQL 中的每个参数一个明确的名字,在绑定值到查询语句的时候就通过该名字来引用参数。
2)看个荔枝:若某个sql 查询语句定义如下:
private static final String SQL_INSERT_SPITTER =
"insert into spitter (username, password, fullname) " +
"values (:username, :password, :fullname)";
对以上代码的分析(Analysis):使用命名参数查询,绑定值的顺序就不重要了,可以按照名字来绑定值;如果查询语句发生了变化导致参数的顺序与之前不一致,我们不需要修改绑定的代码;
Attention)NamedParameterJdbcTemplate 是一个特殊的 JDBC模板类,它支持使用命名参数;其声明方式通过 JdbcTemplate:(干货——NamedParameterJdbcTemplate 支持命名参数)
@Bean
public NamedParameterJdbcTemplate jdbcTemplate(DataSource dataSource) {
return new NamedParameterJdbcTemplate(dataSource);
}
3)看个荔枝:我们将 NamedParameterJdbcOperations(NamedParameterJdbcTemplate所实现的接口)注入到 Repository中,用它来替代 JdbcOperations,现在的addSpitter()方法如下所示:

private static final String INSERT_SPITTER =
"insert into Spitter " +
" (username, password, fullname, email, updateByEmail) " +
"values " +
" (:username, :password, :fullname, :email, :updateByEmail)";
public void addSpitter(Spitter spitter) {
Map<String, Object> paramMap = new HashMap<String, Object>();
paramMap.put("username", spitter.getUsername());
paramMap.put("password", spitter.getPassword());
paramMap.put("fullname", spitter.getFullName());
paramMap.put("email", spitter.getEmail());
paramMap.put("updateByEmail", spitter.isUpdateByEmail());
jdbcOperations.update(INSERT_SPITTER, paramMap);
}