论文读书笔记-large scale text classfication using semi-supervised multinomial naïve bayes
论文标题:large scale text classfication using semi-supervised multinomial naïve bayes.
这篇论文介绍的又是一种分类方法,估计多半是用在模式识别之中。下面是从本文中摘抄的一些要点,有些地方依然没有读懂。
1、 MNB(multinomial naïve bayes)介绍
Given a set of labeled data, MNB often uses a parameter learning method called Frequency Estimate, which estimates word probabilities by computing appropriate frequencies from data.频率估计就是通过计算训练数据中对应的频率来估计单词的频率,这种方法被广泛用在MNB之中。但是由于这种计算需要已经有标签的数据,无法计算那些无标签的数据,而有标签的数据常常是不多的,故需要使用无标签数据来提高MNB的准确性。Expectation-Maximization算法就是一种能对无标签数据进行处理的方法。不过,针对给定的训练数据,EM的表现并不稳定,预测的能力时高时低。这篇文章提出了semi-supervised frequency estimate(SFE)方法。
2、 text document representation
In text classification, a labeled document d is represented as d={w1,w2…wi,c}, where variable or feature wi corresponds to a word in the document d, and c is the class label of d. Typically, the value of wi is the frequency fi of the word wi in document d. We use the w for the set of word in a document d, and thus a document can also be represented as {w,c}. We use T to indicate the training data and the d^t for the t-th document in a dataset T. Each document d has |d| words in it.
Text representation often uses the bag-of-words approach, and a word sequence can be transferred into a bag of words. In this way, only the frequency of a word in a document is recorded, and structural information about the document is ingored.
3、 multinomial naïve bayes
Assume that word distributions in documents are generated by a specific parametric model, and the parameters can be estimated from the training data.MNB model:

其中的参数可以用上面提到的FE进行估计:

其中Nic可以通过以下方法求出:

在求出Nic的同时,我们也求出P(wi):
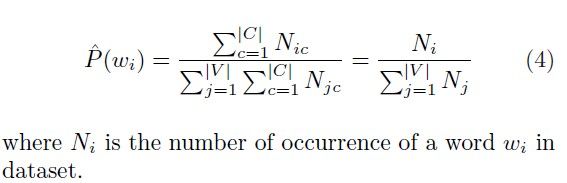
4、 Log likelihood(LL)
上面提到的FE估计方法其实是a generative learning approach.因为其目标方程是一个概似函数(LL):

The first term is called conditional log likelihood(CLL), which measures how well the classifier model estimates the probability of the class given the words. The seconded term is marginal log likelihood(MLL), which measures how well the classifier model estimates the joint distribution of the words in documents. The maximization of MLL often leads to a relatively better classifier given insufficient labeled data. Learnning algorithm should firstly maximize CLL, and then maximize MLL if the labeled data does not provide sufficient information.
5、 expectation-maximization
EM is known to maximize the log likelihood. Its frequency count formula is:
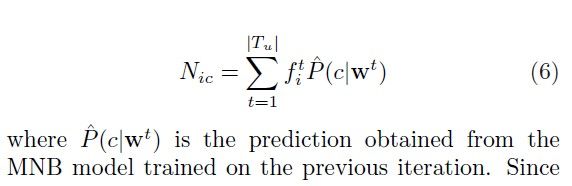
同时:

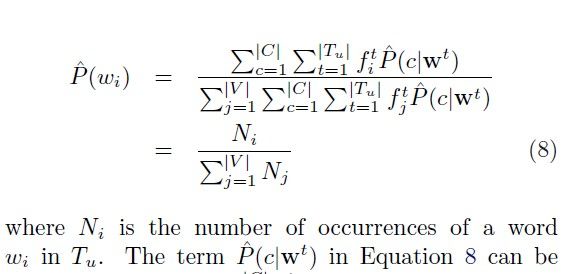
Although EM maximizes MLL in unlabeled data,but when compared to MNB, often leads to relatively inferior conditional log likelihood on labeled training data.
6、 semi-supervised frequency estimate
Our new frequency estimation method combines the word frequency obtained from the unsupervised learning with the class prediction for that word obtained from the supervised learning.

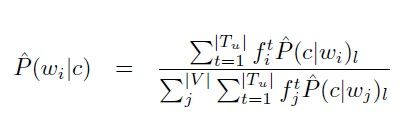
小结:这篇文章就是在比较几种参数估计的算法,基本上都是在用公式推导。看了两遍,也只是知道思想,至于细节,搞不太清。