最优化方法:梯度下降法
链接地址:http://www.codelast.com/%E5%8E%9F%E5%88%9B-%E5%86%8D%E8%B0%88-%E6%9C%80%E9%80%9F%E4%B8%8B%E9%99%8D%E6%B3%95%E6%A2%AF%E5%BA%A6%E6%B3%95steepest-descent/
一、算法过程
最速下降法(又称梯度法,或Steepest Descent),是无约束最优化领域中最简单的算法,单独就这种算法来看,属于早就“过时”了的一种算法。但是,它的理念是其他某些算法的组成部分,或者说是在其他某些算法中,也有最速下降法的“影子”。因此,我们还是有必要学习一下的。
我很久以前已经写过一篇关于最速下降法的文章了,但是这里我还打算再写一篇,提供更多一些信息,让大家可以从更简单生动的方面去理解它。
『1』名字释义
最速下降法只使用目标函数的一阶导数信息——从“梯度法”这个名字也可见一斑。并且,它的本意是取目标函数值“最快下降”的方向作为搜索方向。于是我们就想知道这个问题的答案:沿什么方向,目标函数 f(x) 的值下降最快呢?
『2』函数值下降最快的方向
先说结论:沿负梯度方向 d=−gk ,函数值下降最快。
下面就来推导一下。
将目标函数 f(x) 在点 xk 处泰勒展开(这是我们惯用的“伎俩”了)——
f(x)=f(xk)+αgTkdk+o(α)
高阶无穷小 o(α) 可忽略,由于我们定义了步长 α>0 ,因此,当 gTkdk<0 时, f(x)<f(xk) ,即函数值是下降的。此时 dk 就是一个下降方向。
但是 dk 具体等于什么的时候,可使目标函数值下降最快呢?
文章来源:http://www.codelast.com/
由Cauchy-Schwartz不等式(柯西-许瓦兹不等式)可得:
∣∣dTkgk∣∣≤∥dk∥∥gk∥
当且仅当 dk=gk 时,等号成立, dTkgk 最大(>0)。
所以 dk=−gk 时, dTkgk 最小(<0), f(x) 下降量最大。
所以 −gk 是最快速下降方向。
『3』缺点
它真的“最快速”吗?答案是否定的。
事实是,它只在局部范围内具有“最速”性质。
对整体求解过程而言,它的下降非常缓慢。
『4』感受一下它是如何“慢”的
先来看一幅图(直接从维基百科上弄过来的,感谢Wiki):

文章来源:http://www.codelast.com/
这幅图表示的是对一个目标函数的寻优过程,图中锯齿状的路线就是寻优路线在二维平面上的投影。
这个函数的表达式是:
f(x1,x2)=(1−x1)2+100⋅(x2−x12)2
它叫做Rosenbrock function(罗森布罗克方程),是个非凸函数,在最优化领域,它通常被用来作为一个最优化算法的performance test函数。
我们来看一看它在三维空间中的图形:

它的全局最优点位于一个长长的、狭窄的、抛物线形状的、扁平的“山谷”中。
我们再来看另一个目标函数 f(x,y)=sin(12x2−14y2+3)cos(2x+1−ey) 的寻优过程:
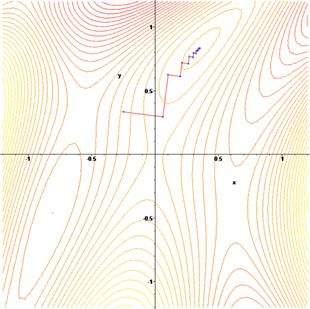
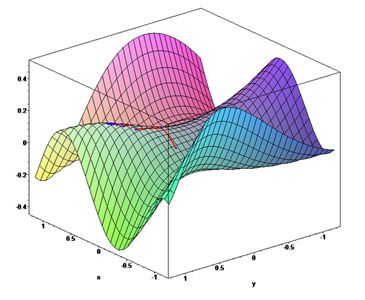
它在三维空间中的图形是这样的:
『5』为什么“慢”的分析
上面花花绿绿的图确实很好看,我们看到了那些寻优过程有多么“惨烈”——太艰辛了不是么?
但不能光看热闹,还要分析一下——为什么会这样呢?
由 精确line search满足的一阶必要条件,得:
∇f(xk+αkdk)Tdk=0 ,即 gTk+1dk=0
故由最速下降法的 dk=−gk 得:
gTk+1dk=gTk+1(−gk)=−gTk+1gk=−dTk+1dk=0⇒ dTk+1dk=0
即:相邻两次的搜索方向是相互直交的(投影到二维平面上,就是锯齿形状了)。
文章来源: http://www.codelast.com/
如果你非要问,为什么 dTk+1dk=0 就表明这两个向量是相互直交的?那么我就耐心地再解释一下:
由两向量夹角的公式:
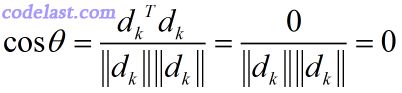
两向量夹角为90度,因此它们直交。
『6』优点
这个被我们说得一无是处的最速下降法真的就那么糟糕吗?其实它还是有优点的:程序简单,计算量小;并且对初始点没有特别的要求;此外,许多算法的初始/再开始方向都是最速下降方向(即负梯度方向)。
文章来源:http://www.codelast.com/
『7』收敛性及收敛速度
最速下降法具有整体收敛性——对初始点没有特殊要求。
采用精确线搜索的最速下降法的收敛速度:线性。
二、梯度下降算法的代码
//梯度下降法
float gsdFindArc(std::vector<cv::Point2f> & inlierPs,cv::Point2f ¢er, float radius)
{
//弧的残差函数为 f = A - 2nXiX - 2nYiY
//double matrix[4][2]={{1,4},{2,5},{5,1},{4,2}};
Eigen::MatrixXf M(inlierPs.size(),2);
for (int i=0;i< M.rows();++i )
{
M(i,0) = inlierPs[i].x;
M(i,1) = inlierPs[i].y;
}
//初始化三个优化参数
std::vector<float > xi(3);
xi[0] = center.x;
xi[1] = center.y;
xi[2] = radius;
//初始化result
//double result[4]={19,26,19,20};
std::vector<float > result(inlierPs.size() );
float r = xi[2];
for (int i=0;i< M.rows();++i )
{
float x = M(i,0);
float y = M(i,1);
result[i] = x*x + y*y - 2*x*xi[0] - 2*y*xi[1] + xi[0]*xi[0] + xi[1]*xi[1] - r*r;
}
//double w[2]={0,0};//初始为零向量
double w[3] = {0,0,0};
double loss = 10.0;
const double n = 0.01; //步长
int numIter = 100*inlierPs.size();
for(int i=0;i< numIter && loss>0.001; i++)
{
double error_sum=0;
int j = i % inlierPs.size();
{
double h = 0;
for(int k=0; k<xi.size() ; k++)
h += M(j,k)* w[k];
error_sum = h - result[j];
for(int k=0; k<xi.size(); k++)
w[k] -= n * (error_sum) * M(j,k);//更新权值,权值更新过程为整个关键过程
}
double loss=0;
for(int j=0; j< M.rows() ;j++)
{
double sum = 0;
for( int k=0; k<xi.size() ; k++)
sum += M(j,k) * w[k];
loss += (sum - result[j]) * (sum-result[j]);
}
std::cout<< "Loss!"<< loss << std::endl;
}
return 1.0;
}