论文读书笔记-Multi-Label Classification on Tree- and DAG-Structured Hierarchies
标题:Multi-Label Classification on Tree- and DAG-Structured Hierarchies
这篇来自2011年ICML机器学习会议上的一篇,作者是James T.Kwok. 凑巧的是,在11月3日的中国机器学习会议上见到过这位教授,他也是第二个发言的。当时南大的周教授在介绍他的时候,就说他对于Kernel极其了解,算的是kernel方面的专家。当时James给我们讲的正是这篇论文的成果--关于多标签的分类。
首先要介绍一下多标签,在现实世界中,对每样事物并不是只有一个标签进行标记,完全可以有多个标记,就好像我们在写博客的时候也可以加上十来个Tag一样。这种标签往往是以树或者DAG图(也就是一个结点可能有多个父节点)的形式进行组织的。在对多标签进行分类时,我们常常是在树或DAG图中找到一个最佳的子图,这也是本文要解决的问题。
下面是一些摘抄:
1、 多标签问题的分类
Problem transformation: transform a multilabel classfication problem into one or more singlelabel classfication problems.
Algorithm adaptation: extend a specific learning algorithm for mulilabel classfication.
2、 kernel dependency estimation
We are given the training data where xi is some input space S, ![]() is the output vector, and d is the number of labels.
is the output vector, and d is the number of labels.

可以看到,KDE算法首先是把输出向量(label)进行降维处理,然后对每个降维投影进行单独学习,学习到模型后再返回到原来的维度。这里的投影通常使用的做法是PCA(主成分分析),也就是找出m个主要的特征向量,z就通过一个简单的Py得到,然后维度返回时直接 PTz即可,这样容易看到维度返回时并不是很精确的,不过由于取到的都是主要的向量,一定程度上就这样代替了。
3、some property
T-property: if a node is labeled positive, its parent must also be labeled positive.
AND-G-property: if a node is labeled positive, all its parents must also be labeled positive.
OR-G-property: if a node is labeled positive, one of its parents must also be labeled positive.
以上就是作者先给出的定义,在树中和DAG图中不相同,DAG图中要考虑AND和OR两种情况。
4、 prediction on tree hierarchies
假设我们已经有了一个样本,它有L个label。当然,如果L个标签是没有结构的,那我们只需要简单的从中找出最大的放入到 即可,这就简化为下面这个最优化问题:
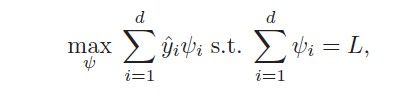
其中ψ=[ψ1...ψd]T , ψi∈{0,1}.
当标签是以树的形式构成的,这个最优化问题就变成这样:

解决这样的问题的关键就是合并结点:Ensure that { wi } is nonincreasing by condensing the non-monotonic tree segments to supernodes. A supernode S is formed by merging a node with its parent. It is assigned a supernode value which is the average of the wi values over all its constituent nodes.这段话说的很简单,父子结点合并后值就当成一个结点看待,值就是父子们值的均值。这样就能保证贪心算法能不断进行下去,In each iteration, an unassigned supernode S∗ with the largest SNV is selected. If assigning ψ(S∗) to 1 does not violate the T -property (i.e., ψ(pa(S∗)) = 1), the assignment will be made permanent; otherwise, S∗ is condensed with its parent. The process is repeated until。针对一个结点,看它的父亲结点是否被中,选中了则把该结点选中,否则就把该结点与父节点进行合并,算法时间O(NlogN)。
SuperNode如下:
与此类似的,DAG图也可以这样来做,首先是DAG图的最优化问题:
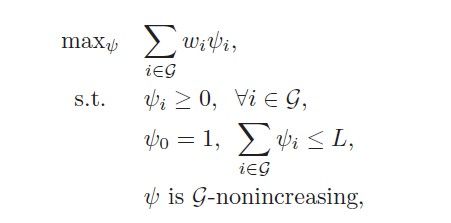
其中ψ满足的条件可以是上面的AND条件或者是OR条件,针对具体问题可以不一样。不过,在进行与父节点合并时,需要进行改动。When the current labeling is not consistent with the DAG, we merge the supernode S∗ with the unassigned parent that has the smallest SNV.至于这样做的原因作者这样描述:By merging S∗ with the parent with the smallest SNV, the new supernode will have the smallest possible SNV. We always selects the supernode with the largest SNV, existing supernodes that may be more promising than the newly merged supernode will be able to be considered first.简单说来就是优先选择那些较早存在的supernodes,所谓先到先考虑。算法时间也为O(NlogN)。
针对OR的条件,原理依然类似,需要修改的还是父子结点合并的时候,The key idea is to preserve the label consistencies by converting part of the DAG to a tree.因为每个父节点都子节点都有相同的影响力,所以要把子节点进行复制,on condensing a supernodeS∗withnpaparent supernodes, since allits parents are equally desirable because of the OR-Gproperty, we replicateS∗npatimes and merge eachreplicate with one of its parents.拆分图如下:
至此,我们用贪心算法解决上面三种情况的multi-Labeled问题。
5、 performance measures
这个是本论文在对算法性能进行评估的时候提到的,貌似模式识别课上讲过,这里学习下
Precision: TP/(TP+FP) 精确度
Recall: TP/(TP+FN) 查全率(翻译不当)
TP is the number of true positives. FP is the number of false positive. FN is the number of false negatives.
小结:贪心算法谁都知道,比DP简单很多,但是作者能把贪心算法巧妙的与KDE结合起来并用来解决机器学习中比较头疼的问题,这是一个很大的创新。正所谓人工智能刘峡壁老师所说,我们现在学这么多东西就是在装配自己的武器库,等到问题到来时用这些武器去解决。当然,一个很可悲的现实是,我们有武器却不会用,所有有些人看上去比别人懂得更多,但却很能解决问题,这就是仁者见仁智者见智了。