对数线性模型之一(逻辑回归), 广义线性模型学习总结
1、逻辑斯蒂分布,logit转换
2、在二分类问题中,为什么弃用传统的线性回归模型,改用逻辑斯蒂回归?
3、逻辑回归模型的求解过程?
4、实际应用逻辑回归时数据预处理的经验总结。但经验有限,如果有哪位网友这块经验丰富,忘指教,先谢过
5、为什么我们在实际中,经典线性模型的优化目标函数是最小二乘,而逻辑回归则是似然函数
6、从最根本的广义线性模型角度,导出经典线性模型以及逻辑回归
1、逻辑斯蒂分布,logit转换
一个连续随机变量X,如果它的分布函数形式如下,则X服从逻辑斯蒂分布,F(x)的值在0~1之间,它的的图形是一条S型曲线。
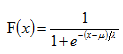

2、在二分类问题中,为什么弃用传统的线性回归模型,改用逻辑斯蒂回归?
线性回归用于二分类时,首先想到下面这种形式,p是属于类别的概率:
![]()
但是这时存在的问题是:
1)等式两边的取值范围不同,右边是负无穷到正无穷,左边是[0,1],这个分类模型的存在问题
2)实际中的很多问题,都是当x很小或很大时,对于因变量P的影响很小,当x达到中间某个阈值时,影响很大。即实际中很多问题,概率P与自变量并不是直线关系。
所以,上面这分类模型需要修整,怎么修正呢?统计学家们找到的一种方法是通过logit变换对因变量加以变换,具体如下:
![]()
![]()
从而,
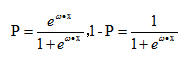
这里的P完全解决了上面的两个问题。
3、逻辑回归模型的求解过程?
1)求解方式
逻辑回归中,Y服从二项分布,误差服从二项分布,而非高斯分布,所以不能用最小二乘进行模型参数估计,可以用极大似然估计来进行参数估计。
2)似然函数、目标函数
严谨一点的公式如下:
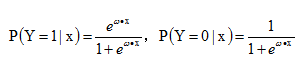
似然函数如下:
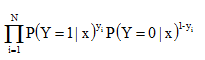
对数似然函数,优化目标函数如下:

整个逻辑回归问题就转化为求解目标函数,即对数似然函数的极大值的问题,即最优化问题,可采用梯度下降法、拟牛顿法等等。
4、实际应用逻辑回归时数据预处理的经验总结,但经验有限,如果有哪位网友这块经验丰富,忘指教,先谢过
1)枚举型的特征直接进行binary
2)数值型特征,可以:标准化、根据分布进行binary
3)进行pairwise
5、为什么我们在实际中,经典线性模型的优化目标函数是最小二乘,而逻辑回归则是似然函数
下面公式直接从Ng notes里面复制过来。
1) 经典线性模型的满足下面等式:
![]()
这里有个假设,即最后这个误差扰动项独立同分布于均值为0的正态分布,即:
![]()
从而:
![]()
由于有上面的假设,从而就有下面的似然函数:
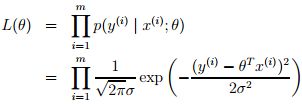
从而这线性回归的问题就可转化为最大化下面的对数似然估计,由于下面公式前面的项是常数,所以这个问题等价于最小化下面等式中的最后一项,即least mean squares。

2)逻辑斯蒂回归中,因变量y不再是连续的变量,而是二值的{0,1},中间用到logit变换,将连续性的y值通过此变换映射到比较合理的0~1区间。在广义线性回归用于分类问题中,也有一个假设(对应于上面回归问题中误差项独立同分布于正态分布),其中h(x)是logistic function
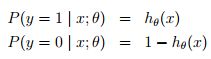
即,给定x和参数,y服从二项分布,上面回归问题中,给定x和参数,y服从正态分布。从而。
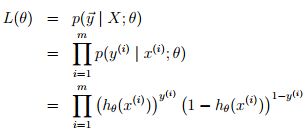
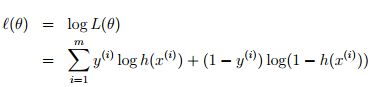
问题不同(一个是分类、一个是回归)对应假设也就不同,决定了logistic regression问题最优化目标函数是上面这项,而非回归问题中的均方误差LMS。
6、从最根本的广义线性模型角度,导出经典线性模型以及逻辑回归
1)指数家族
![]()
当固定T时,这个分布属于指数家族中的哪种分布就由a和b两个函数决定。下面这种是伯努利分布,对应于逻辑回归问题


注:从上面可知![]() ,从而
,从而![]() ,在后面用GLM导logistic regression的时候会用到这个sigmoid函数。
,在后面用GLM导logistic regression的时候会用到这个sigmoid函数。
下面这种是高斯分布,对应于经典线性回归问题
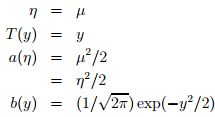

2)GLM(广义线性模型)
指数家族的问题可以通过广义线性模型来解决。如何构建GLM呢?在给定x和参数后,y的条件概率p(y|x,θ) 需要满足下面三个假设:
assum1) y | x; θ ∼ ExponentialFamily(η).
assum2) h(x) = E[y|x]. 即给定x,目标是预测T(y)的期望,通常问题中T(y)=y
assum3) η = θTx,即η和x之间是线性的
3)经典线性回归、逻辑回归
经典线性回归:预测值y是连续的,假设给定x和参数,y的概率分布服从高斯分布(对应构建GLM的第一条假设)。由上面高斯分布和指数家族分布的对应关系可知,η=µ,根据构建GLM的第2、3条假设可将model表示成:

逻辑回归:以二分类为例,预测值y是二值的{1,0},假设给定x和参数,y的概率分布服从伯努利分布(对应构建GLM的第一条假设)。由上面高斯分布和指数家族分布的对应关系可知,![]() ,根据构建GLM的第2、3条假设可model表示成:
,根据构建GLM的第2、3条假设可model表示成:
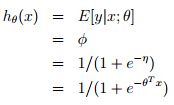
可以从GLM这种角度理解为什么logistic regression的公式是这个形式~
参考资料:
[1] NG的lecture notes,http://cs229.stanford.edu/notes/cs229-notes1.pdf
[2] 其他网络资源