CUDA矩阵乘法——利用共享存储器
上篇的方法是在全局存储区中,这样对取数据时速度回很慢,影响性能,而设备中线程对块中的共享存储区中数据读取时速度是很快的,并且在全局存储区中进行读取时,有很多数组元素的重复读取。因此,先将需要计算的数组数据读取到共享存储区中,再利用共享存储区中的数据进行计算,就会提高性能。
但由于每个块的共享存储区的存储空间一般很小,以本人8400MG为例,只有16KB,因此在一个块内需要的数据量大时,有必要对数据进行分块,分块进行计算。
1.分块策略
比如上篇中的:
网格维度:(width/TILE_WIDTH,width/TILE_WIDTH) (64,64)
块维度:(TILE_WIDTH,TILE_WIDTH) (16,16)
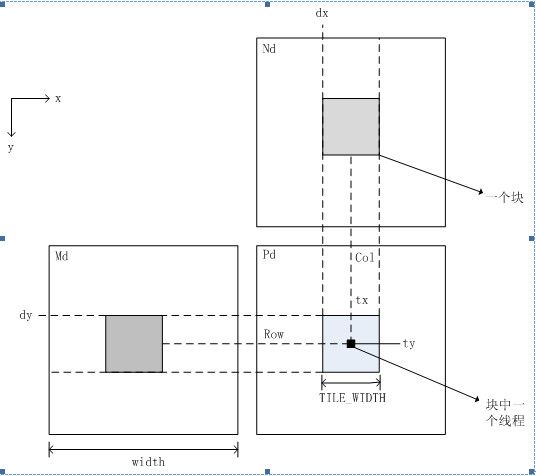
计算如图中Pd中的一个块需要Md和Nd虚线包围的数据。Pd一个块中的所需的数据大小:TILE_WIDTH*width*2*4/1024 (KB) 2因为Md和Nd两个数组,4因为float。计算得128MB。显然大大超过了16KB,这时就需要采用分块的方式计算。(注意:分块计算的方式在大数据处理中是很常用的方法)
分块大小:可以先尝试尝试,就以TILE_WIDTH*TILE_WIDTH的矩形块为一小块,进行分块分阶段计算。计算需要的存储器大小为16*16*2*4/1024=2KB,可以,根据上图也很清晰,思路明了(这是关键)。
2.源程序
__shared__关键字说明变量存储在共享存储区内,共享存储区内的数据对块内的线程是共享的。在线程内申明的变量作用范围知识线程。
每个块中含有TILE_WIDTH*TILE_WIDTH个线程,而每个小块中Md和Nd中的数据元素为TILE_WIDTH*TILE_WIDTH,因此块中的一个线程将Md和Nd中的一个元素加载进共享存储器。如下代码第21、22行所示(tx,ty)处的线程分别将Md和Nd中的一个元素加载进共享存储器中。
采用此方法,kernel函数就要改变,如下:
__global__ static void MatrixMulKernel(const float* Md,const float* Nd,float* Pd,int Width)
{
//共享存储器保存从从全局存储器中加载的数据
__shared__ float Mds[TILE_WIDTH][TILE_WIDTH];
__shared__ float Nds[TILE_WIDTH][TILE_WIDTH];
//计算Pd和Md中元素的行索引
int bx=blockIdx.x;
int by=blockIdx.y;
int tx=threadIdx.x;
int ty=threadIdx.y;
//Pd的行和列
int Row = by*TILE_WIDTH+ty;
int Col = bx*TILE_WIDTH+tx;
float Pvalue = 0.0;
//第k小块
for (int k=0;k<Width/TILE_WIDTH;k++)
{
//通过协作把Md和Nd的块加载到共享存储器中
Mds[ty][tx]=Md[Row*Width+k*TILE_WIDTH+tx];
Nds[ty][tx]=Nd[(k*TILE_WIDTH+ty)*Width+Col];
__syncthreads(); //等待块中其他线程同步
for(int m=0;m<TILE_WIDTH;m++)
Pvalue +=Mds[ty][m]*Nds[m][tx];
__syncthreads(); //等待其他线程计算完,因为Pvalue要用到下一个块的计算
}
//每个线程负责计算P中的一个元素
Pd[Row*Width+Col]=Pvalue;
}
里面比较重要的是线程同步,用__syncthreads()函数,完成一个块内线程的同步的功能,因为要让线程将需要的数据都加在进共享存储区内才能进行计算。
3.测试结果
CPU计算比较耗时,就不测试了,可以看到采用此方法比上篇中的性能要提高了不少。
4.不同分配策略比较
上面只是用到了2KB的共享存储器,可以考虑将分块数据更大一点,即将上面Md和Nd中四个小块合并为一个小块
Md一个小块大小:(TILE_WIDTH,TILE_WIDTH*4)
Nd一个小块的大小:(TILE_WIDTH*4,TILE_WIDTH)
上面代码就要进行些变化,主要是共享存储器分配大小以及循环变量的循环条件。
测试结果如下:
可见比前面要慢些。这里还可以利用其它分块策略进行测试,从而找到最适合的分块策略,分块是同时也要兼顾物理存储限制及存储器访问模型。
http://www.cnblogs.com/Romi/archive/2012/05/17/2506826.html
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
上篇中http://www.cnblogs.com/Romi/archive/2012/05/09/2492363.html,出了点问题,也是后来才发现的,意识到每个块中最多只能有512个线程,而该文的块大小为64*64,显然超过了512,因此此篇将其改为16,即TILE_WIDTH=16。其他代码还是和上篇一样。
矩阵计算模型的数组元素索引如下图所示
测试结果如下:
GPU计算时间变长了,上篇那样数组中的元素并没有全计算到。可以看到GPU计算时间虽然也有点多,但还是比CPU串行计算要快。
此文中数据保存在全局存储器,进行计算时,从全局存储区取数据进行计算,而从全局存储器取数据的速度是很慢的,而且取矩阵元素有很多重复,即一个矩阵元素取了好多次,这些都会对计算性能产生影响,因此还可以进一步优化。
http://www.cnblogs.com/Romi/archive/2012/05/17/2506787.html