Every write operation goes to all replicas, but only responses
from a majority quorum are necessary to commit the write.
每一次写操作都分发到所有副本,只有大部分节点应答才能提交写
缺点:随着副本数的增加,集群中需要ack的节点数量比较多(n/2-1)
存储元数据,数据量不是很大,使用ZooKeeper比较合适

The ISR scheme of Kafka requires all the members of the current ISR to respond
对于一次写的提交,要求当前ISR中的所有成员都ack, 才算提交写成功
ISR的大小是可配置的,和副本数量没有关系.比如11个副本可以配置ISR=3, 如果用quorum,则需要6个节点ack

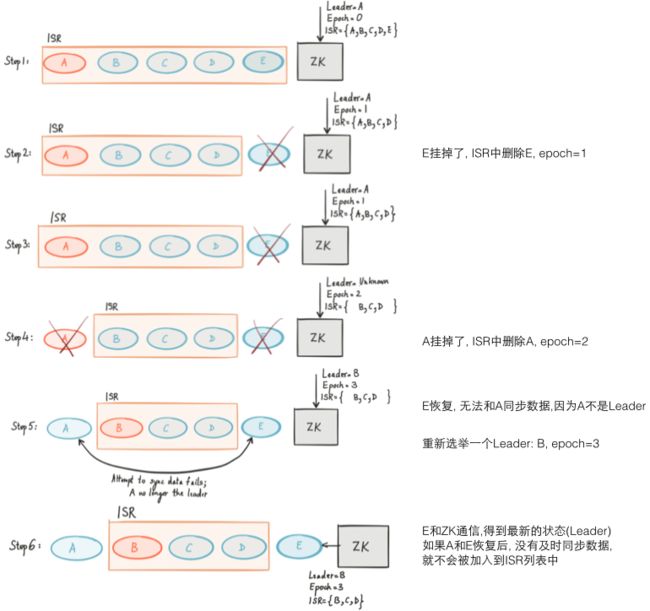
场景1: 节点挂掉后重新和Leader同步数据
场景2: 普通节点和Leader节点都挂了,选举新的Leader
Partition
每条消息都有一个唯一的offset. 一个Topic分成多个Partition
每个Partition中消息offset都是一直增加, LEO表示最后一条消息的offset
可以认为一个Partition内的offset是全局有序的,一个Partition分成多个Segment, 每个Segment的offset也都是有序的
Segment与Segment之间的offset也是有序的, 所有这些Segment组成的一个Partition就是全局有序的

Replication
Leader宕机, 新的Leader一定是从先前Leader的ISR中选举出来的
ISR是所有副本的子集, 是那些能够及时地复制Leader日志的节点

每个Partition的Leader通过计算每个副本和它相比落后的数量来跟踪(更新)ISR列表
当生产者生产一条消息给Broker,写到Leader节点, 并且复制到Partition的所有副本
但只有全部复制到ISR列表中的每个节点(ISR节点必须都ack), 这条消息才算被提交
复制到一个不在ISR列表中的节点, 即使没有ack也没有关系(因为它本身就比较慢了)
如果一个节点落后太多, 就会从ISR中移除. 这样复制延迟取决于ISR中最慢的节点
所以如果ISR中最慢的节点还不争气,也会被剔除掉, 最终在ISR中的节点一般都很快
假设副本数=3, 有三个Broker, 已经有三条消息committed了, 初始时所有的副本(包括Leader)都在ISR中
并且replica.lag.max.messages=4, 只要follower落后于Leader不超过3条消息, 就不会从ISR中移除
replica.lag.time.max.ms=500, 只要follower每隔500ms(或者更快)向Leader获取消息(fetch request)
就不会被标记为DEAD, 也就不会从ISR中移除(如果没有落后太多,但是长时间没fetch,也会被移除的).
lag.max.messages: detect slow replicas
lag.time.max: detect halted or dead replicas

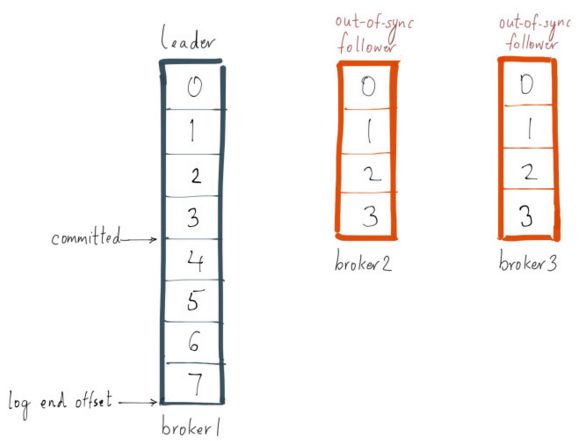
Producer向Leader发送了一条消息, Leader的LEO增加了一.
这个时候Broker3由于某种原因卡住了, 无法从Leader上及时获取这条消息
而Broker2则正常地从Leader上同步了这条消息到自己本地.
由于一条消息被成功地提交的必要条件是: 在ISR中的所有节点都复制了这条消息.
Broker3还在ISR中, 只要它没有复制这条消息, 那么这条消息就不会被committed.
由于现在Broker3才落后Leader一条消息 < replica.lag.max.messages=4
所以它并不会从ISR中移除, 所以只能静静地等Broker3…
要么再多落后几条消息, 从ISR中移除
要么赶快恢复过来, 然后从Leader复制消息, 及时赶上Leader,不要落后太多

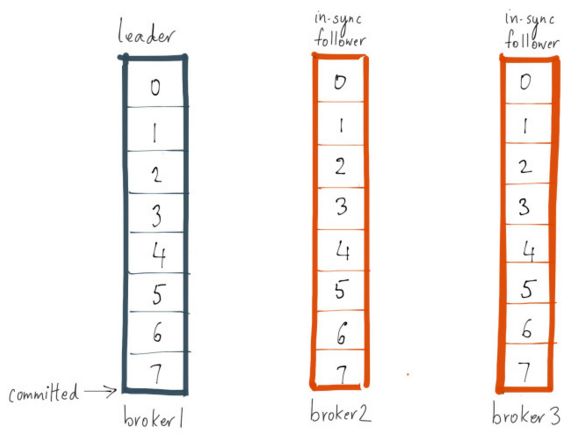
假设Broker3在100ms后恢复过来, 然后从Leader同步这条稍微延迟的消息
现在两个follower都复制了消息3, 由于ISR的所有节点都复制了消息3,
现在Leader的committed(HW)可以向后移动到消息3了.
如果Producer发送一批4条消息 = lag.max.messages = 4
所有的follower都落后于leader太多了, 它们会从ISR中删除
由于所有的follower都是alive的, 它们会在下次fetch request时赶上Leader的LEO
即复制这批消息, 现在落后的消息已经被补上了, 于是就会被重新加入到ISR中,
于此同时由于follower都复制了这批消息, committed也增加到最新的便宜位置
这种大批量的生产消息, 造成follower不断地shuttle in and out of ISR (移除后又添加)
而且需要根据topic的期望流量猜测正确的值, 看起来并不是很好控制!
现在统一只使用一个配置: replica.lag.time.max.ms 来控制stuck和slow的replica.
不过它的含义变为: follower上的副本和Leader相比out-of-sync的时间
stuck replica含义仍然不变:如果没有及时发送fetch request, 会被认为Dead,并移除
slow replica: 副本从刚开始落后与Leader, 直到超过这个时间,说明它太慢了也会移除
这样即使有突增流量或一直都是大批消息, 除非副本一直落后与Leader太长的时间
否则如果副本只要在这个时间内能赶上Leader, 就不会出现删除后又添加到ISR的现象
Ref
http://www.confluent.io/blog/distributed-consensus-reloaded-apache-zookeeper-and-replication-in-kafka
http://www.confluent.io/blog/hands-free-kafka-replication-a-lesson-in-operational-simplicity/
http://it.dataguru.cn/article-9856-1.html