整理系列-20161111-Spark学习周记_4
Spark 机器学习
2016.02.29
- Neural Networks and Deep Learning.Michael Nielsen.2016.02.29
- 尹绪森.Spark 与 MLlib:当机器学习遇见分布式系统[J].程序员.2014,7.
2016.03.08
开始看 Spark 机器学习的部分,然后粗略记录一下一些重点部分,方便之后查阅。
训练方法几乎一样,只是模型特定可配置的模型参数不尽相同,MLlib 中大多数情况下都会 设置明确的默认值,当然最好还是使用评估技术来选择相应的参数,更加妥当。
为交叉验证:分割数据集->sample 20% & subtractByKey 80%
机器学习模型种类
- 监督学习
推荐引擎、回归 & 分类 - 无监督学习
聚类、降维 & 文本处理 - 应用领域
个性化、目标营销、客户细分&预测建模与分析(回归 / 分类) - 提取数据集有用特征
- 数值特征–>当处于原始形式时,可用性降低
- 类别特征(名义 / 有序变量)
- 文本特征–>NLP(e.g. 词袋法:分词 / 删除停用词 / 提取词干 / 向量化)
- 派生特征–>平均值 / 方差 / 中位数 / 和 / 差 /Max/Min/Count
- 正则化特征–>norm
分类模型
- 模型分类
- 线性模型
- 线性 SVM–>合页损失
- 逻辑回归模型–>逻辑损失
- 决策树
- 朴素贝叶斯模型
- 线性模型
- 训练分类模型
需要配置的参数有:逻辑回归与 SVM 的迭代次数 / 决策树的最大树深度等。 - 评估性能
- 正确率
- 错误率
- 准确率
- 召回率
回归模型
- 模型分类
- 最小二乘回归
- 决策树回归
- 训练回归模型
- 线性模型:迭代 / 步长 / L2正则化 / L1正则化 / 截距
- 决策树:最大树深度 / 最大划分数
- 评估性能
- MSE 均方误差
- RMSE 均方根误差
- MAE 平均绝对误差
- RMSLE 均方根对数误差 (Kaggle)
- R-平方数
- 改进模型性能可采用的途径
- 取对数
- 平方根
2016.03.09
决定还是先消化一下前面两个主要的监督学习算法(分类 / 聚类),做出一个模型实 例后,再往下继续深入学习,当然,这都建立在总时间允许的情况下。
之前找了一个机器学习数据集的 UCI 学校机器学习官网,没想到倒是和 Spark 机器学 习这本书上的推荐不谋而合了。不难发现,官网的分类中有一种分类很科学方便地可以一 步步、一个个地熟悉算法。如下图所示:
分类 / 聚类 / 回归

基于多年以前做过一个非常记忆深刻的回归算法模型,承认自己有回归算法的特殊情 结并不困难。于是我选择从书上推荐的 Bike-Sharing 数据集开始下手!
当然,接下来需要考虑的问题就一步步棘手了起来。
为了方便演示,我需要搭建一个网站后台,这不麻烦,可是用什么语言来写呢?Java? 好像不用那么麻烦。用 python?是个好主意,可惜 C# .NET、Python Web(Django)视我为异 类,实在没有过多精力来搞定这些网站方面的拓展领域。简单起见,PHP 吧!“PHP 是世 界上最好的语言。”我曾天真地这么以为着,虽然现在被 PHP 对多线程的不兼容性搞得一个头两个大,我依然觉得这个目前来说还算小巧的解释型语言还是很值得褒奖的,除了低门槛导致的大量初学者的渣代码出现令人不快之外。
简单写了个 html,引入了一些外部 css、js 和 jquery 库,接下来,等着 php exec(),一 切都是那么顺其自然。
But,问题还有很多!Spark 支持 Python / Java / Scala / R 语言,到底选哪一个!基于对 以前写的一些网络配置的脚本中大量外部引入的 GUI 库这种方便实用做法的喜爱与热衷, 以及 Python无需编译就能直接投入使用,(省去 Scala sbt / Java Maven 等)幸福来得太突然了!
接下来就是两种语言交接以及 PHP 对于 spark 处理完毕的数据的读取显示问题了。这就留着做完基本的 Python 模块之后再想吧,先投入 Spark 的浩瀚海洋中!
2016.03.10
简单总结一下做到现在所遇到的一些问题和感触。
- 虚机下搭建 Linux——操作系统;
- Linux 下搭建集群环境——计算机系统结构; 搭建网站显示界面——数据库(PHP) / JavaEE;
- Spark 编程——JavaSE / 网络脚本(实习);
- 机器学习——集体智慧编程(书)/ 数学建模大赛(回归模型)。
这样算算,短时间内的一个毕设也算是磨练了专业两年以来的各项技能,融会贯通使 用的过程中,也确实不禁感慨计算机短短 70 余载的历史中,有那么多伟大的设计。
昨天看了乔布斯在 1990 年参加 BBC 的采访时尚且青涩但却洋溢对计算机设计之美的 热忱的总裁之风,其中,乔布斯对 InterPersonal 的互联网际时代到来的向往。
在互联网+时代的今天,曾经的行业大佬们,所谓的老炮,对于现如今网络时代的浮躁 表示不解。
我想这也正是计算机及其相关专业的魅力所在,其实本无所谓专业,专业与专业之间 总是相通的。而终究“码农”不可为,计算机爱好者之心不可弃。
永远不要放弃做一个学者,因为放下对未知世界的好奇感之后,长江后浪推前浪,“码 农”分分钟就失业了。
No loser.
2016.03.29
Python运行第一个bike-sharing的例子。
如何配置SparkContext
对于应该在yarn集群上配置何种方式,有点confuse,参考如下:
Spark源码分析:多种部署方式之间的区别与联系.2016.03.29.
从广义上讲,yarn-cluster适用于生产环境;而yarn-client适用于交互和调试,也就是希望快速地看到application的输出。
从深层次的含义讲,yarn-cluster和yarn-client模式的区别其实就是Application Master进程的区别,yarn-cluster模式下,driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。然而yarn-cluster模式不适合运行交互类型的作业。而yarn-client模式下,Application Master仅仅向YARN请求executor,client会和请求的container通信来调度他们工作,也就是说Client不能离开。
yarn-cluster:

yarn-client:(适合交互,但client不能离开)
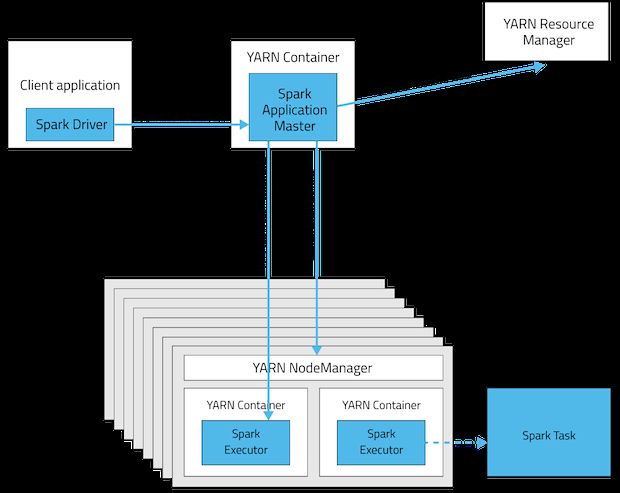
需要注意的是,Spark在YARN模式上运行只支持yarn-client模式,如果你将MASTER设置成了yarn-cluster,那么将会出现异常:
org.apache.spark.SparkException: Detected yarn-cluster mode, but isn’t running on a cluster. Deployment to YARN is not supported directly by SparkContext. Please use spark-submit.
- 在Yarn上运行Apache Zeppelin & Spark.2016.03.29.
- Pyspark on yarn-cluster mode.2016.03.29.
果然学完了就要马上上手,视频教程中看到的一些细节有很多都忘了。
小技巧
在window里面编辑文档时习惯了按ctrl+s保存文档,转到linux下时,保存文档时也按了,然后没有反应;查阅网络资料发现在vi编辑器中ctrl+s为终止屏幕输出(停止回显),ctrl+q恢复屏幕输出。
在vi按了ctrl+s后.2016.03.29.
2016.04.03
numpy import出错
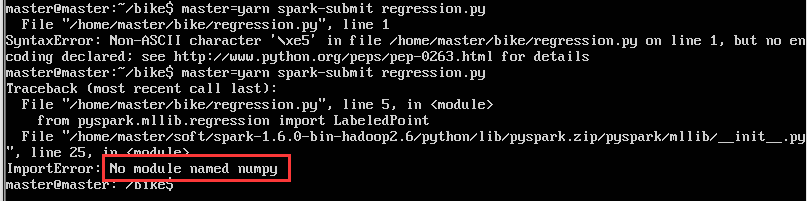
Linux(Fedora)下python”no module named numpy”解决方案.2016.04.03
结果出现了连环未安装的情况!!
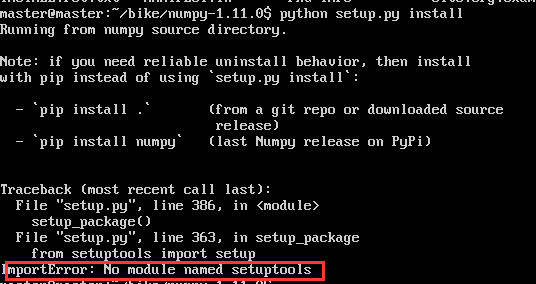
Python安装模块出错(ImportError: No module named setuptools)解决方法.2016.04.03

运行python需要具有sudo权限,指令如下:
wget https://bootstrap.pypa.io/ez_setup.py -O - | sudo python这果然是一个连环的报错。

Have a try!
在一排warning的惊吓和五分钟下载,十多分钟安装的等待后,终于!

Out of memory?!
从输出结果看,spark内存又不够了。
Ubuntu-desktop只能用guest权限登陆?
sudo stop lightdm;
sudo apt-get update;
sudo apt-get upgrade
sudo apt-get install --reinstall lightdm;
sudo rebootubuntu 14.04 安装后无法登陆进入桌面
apt-get重新安装环境,结果用原来的账户还是无法登陆。考虑可能是有些隐藏文件被删了,干脆重新新建一个账户,专门用作桌面登陆,在terminal下su切换账户好了。
2016.04.07
Note_10
执行到first(),总是报错,估计是extract_features时用numpy出的错?
Numpy需要在所有节点上安装?OMG!

结论就是,参考书上代码不可信,还是先做决策树,后面有时间再说线性回归的问题。