聚类分析之dbscan
算法概念解析
DBSCAN:一种基于高密度连通区域的基于密度的聚类方法,该算法将具有足够高密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇。它将簇定义为密度相连的点的最大集合;为了理解基于密度聚类的思想,首先要掌握以下几个定义:
给定对象半径r内的邻域称为该对象的r邻域;
如果对象的r邻域至少包含最小数目MinPts的对象,则称该对象为核心对象;
给定一个对象集合D,如果p在q的r邻域内,并且q是一个核心对象,则我们说对象p从对象q出发是直接密度可达的;
如果存在一个对象链p1,p2,p3,...,pn,p1=q,pn=p,对于pi属于D,i属于1~n,p(i+1)是从pi关于r和MinPts直接密度可达的,则对象p是从对象q关于r和MinPts密度可达的;
如果存在对象o属于D,使对象p和q都是从o关于r和MinPts密度可达的,那么对于对象p到q是关于r和MinPts密度相连的;密度可达是直接密度可达的传递闭包,这种关系非对称,只有核心对象之间相互密度可达;密度相连是一种对称的关系;
有了以上的概念接下来就是算法描述了:DBSCAN通过检查数据库中每点的r邻域来搜索簇。如果点p的r邻域包含的点多余MinPts个,则创建一个以p为核心对象的新簇。然后,DBSCAN迭代的聚集从这些核心对象直接密度可达的对象,这个过程可能涉及一些密度可达簇的合并。当没有新的点可以添加到任何簇时,该过程结束;
具体的伪代码描述如下(摘自维基百科):
DBSCAN(D, eps, MinPts)
C = 0 //类别标示
for each unvisited point P in dataset D //遍历
mark P as visited //已经访问
NeighborPts = regionQuery(P, eps) //计算这个点的邻域
if sizeof(NeighborPts) < MinPts //不能作为核心点
mark P as NOISE //标记为噪音数据
else //作为核心点,根据该点创建一个类别
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts) //根据该核心点扩展类别
expandCluster(P, NeighborPts, C, eps, MinPts)
add P to cluster C //扩展类别,核心点先加入
for each point P' in NeighborPts //然后针对核心店邻域内的点,如果该点没有被访问,
if P' is not visited
mark P' as visited //进行访问
NeighborPts' = regionQuery(P', eps) //如果该点为核心点,则扩充该类别
if sizeof(NeighborPts') >= MinPts
NeighborPts = NeighborPts joined with NeighborPts'
if P' is not yet member of any cluster //如果邻域内点不是核心点,并且无类别,比如噪音数据,则加入此类别
add P' to cluster C
regionQuery(P, eps) //计算邻域
return all points within P's eps-neighborhood
现实场景应用
场景描述:例如活动送一些礼品套件,恶意黑产来利用这个活动频繁刷取这些套件,我们需要智能识别出这些黑产用户,将其和正常用户区别开来。
问题分析:观察这些恶意刷取套件的用户id存在高密度聚合,那我们可以采取时间作为x轴,uid作为y轴建立一个二维空间数据集合,数据集合如下所示:
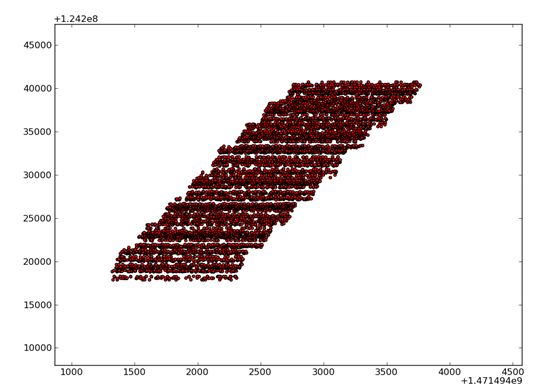
图中所示的点都是恶意用户的数据点集合,他们的特点从y坐标轴可以看出上下相差幅度不到5000,所以在5000之内是一个高密度聚合的特点。我们采用dbscan来进行处理。
dbscan线上实时运算架构
整个实现可以分为三个关键模块:实时运算、异步数据采集、数据聚类及模型输出。
由于数据量较大的情况下线上实时聚类效率较低,1.5W数据实时聚类需要10s,考虑到实时聚类的时效性,可以采取异步聚类,实时拖取模型在线运算的模式。
实现
流程图

这里实现和标准的地方有如下不一样的点:
1、 系统关注每个簇的中心节点,会记录下中心节点;
2、系统设置每个簇的大小不是依据扩展查询得到的,而是直接使用本节点的邻域值大小来设置,这点原因是由于扩展查询会忽略掉其它簇依据被访问添加节点,所以会出现一个邻域查询到节点为n,而实际扩展查询之后只有m(其中m<n),由于后续的在线聚类是关注每个簇的实际大小,所以这里直接设置邻域查询的大小。
3、在线实时运算只需要将一个在线点和所有簇的中心节点计算欧式距离,找出一个欧式距离最小的簇作为该节点所在的簇,进而计算本次节点所在聚类的簇群大小。
4、异步聚类的时候由于数据集合我们关注的是账户id这项,所以采取id作为x轴,而二位平面的坐标点的y轴我们采取随机值实现(小于1)这样聚类的算法就完全关注x轴,最终结果也会依据x轴进行聚类,这样处理对关注点的聚类效果比较好。
关键代码实现
Dbscan聚类
for (final Clusterable instance : instances) {
if (visited.get(instance) != null) {
continue;
}
final List<Clusterable> neighbors = (List<Clusterable>) getNeighbors(instance, instances);
if (neighbors.size() - 1 >= minPts) {
final Cluster<Clusterable> cluster = new Cluster<Clusterable>();
expandCluster(cluster, instance, neighbors,
instances, visited);
final SimpleCluster<Clusterable> simpleCluster = new SimpleCluster<Clusterable>();
simpleCluster.setCenterInstance(instance);
simpleCluster.setClusterSize(neighbors.size());
clusters.add(simpleCluster);
} else {
visited.put(instance, InstanceStatus.NOISE);
noiseSize++;
}
Dbscan在线分类
DBscanResult dBscanResult = new DBscanResult();
double minDistans = 0;
double pointCliusterSize = 0;
for (SimpleCluster<Clusterable> cluster : clusters) {
if(!cluster.isNoise()){
double distans = getDistanceMeasure().compute(instances.getFeatures(), cluster.getCenterInstance().getFeatures());
if(distans <= this.eps && (minDistans == 0 || distans < minDistans)){
pointCliusterSize = cluster.getClusterSize();
minDistans = distans;
}
}
}
double result = 1;
result = 1 - (pointCliusterSize / instanceSize);
dBscanResult.setResult(result);
结果

Y轴为(1-所在簇大小占总聚类数的比例值),也就是说密度越高的数据Y值就越小,正常用户的Y轴是接近1.0,而恶意用户的Y轴都分布在0.6以下。