DeeoID:Deep learning face representation from predicting 10,000 classes
参考文献:《DeeoID:Deep learning face representation from predicting 10,000 classes》
1 Effective way to learn high-level over-complete features with deep ConvNets.
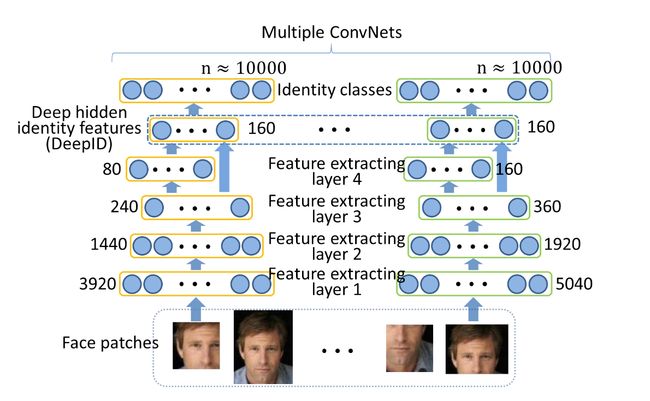
图1 箭头指示传播的方向。每一层神经元的数量的标记在multiple deep ConvNets的旁边。DeepID提取自每一个ConvNet的最后一个隐层,and predict a large number of identity classes。沿着特征提取特征数量继续减少级联到DeepID层。 特征的数量沿着特征提取的级联方向逐渐减少,直到DeepID层.
The ConvNets are learned to classify all the faces available for training by their identities, with the last hidden layer neuron activations as features (referred to as Deep hidden IDentity features or DeepID).每一个 ConvNet 的输入为一个face patch,在最下面的层提取局部的低级特征. 沿着特征提取的级联方向提取的特征的数量会逐渐减少,但是更多全局的和高级的特征会在上面的层提取出来。最后得到的是一个160维的DeepID特征,包行rich identity information,并且可以直接用来预测大数据量的身份类别分类(比如,1000类).
同时分类所有的身份类别,而不是训练二元分类器是基于两方面的考虑。首先, it is much more difficult to predict a training sample into one of many classes than to perform binary classification。这个具有挑战性的任务可以充分利用神经网络的超级学习能力的提取人脸识别的有效特征。第二,它隐式地对ConvNets添加了一个强正规化, 这有助于形成共享的隐藏表示, 可以很好的分类所有的身份类别。所以,这样学习到的高级特征具有很好的凡或能力并且用小数据集做人脸训练不会导致过拟合。我们限制DeepID的维数要显著少于分类的类别,这是学习得到具有高度紧凑和区分性的特征的关键。我们进一步连接提取自不同人脸区域的DeepID来形成复杂完备的表示。测试中发现,学习得到的特征可以很好的一般化到新(训练中没有用到, which are not seen in training)的身份类别测试,并且可以和任何人脸验证的分类器(例如,Joint Bayesian)集成。
2 网络结构(Deep ConvNets)
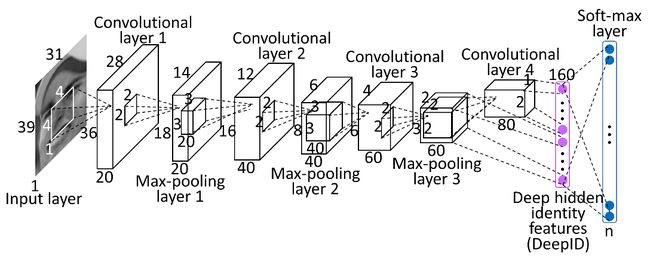
图2 网络中有4个卷积层的网络,除了第4个卷积层,前3个卷积层后面都连接一个max-pooling层。DeepID层和第4个卷积层以及第3个max-pooling层全连接(这样做的是因为第4层卷积层含有的神经元个数太少,成为信息传递的瓶颈),这做是作者所谓的Multi-scaleConvNets。 第4个卷积层提取到的特征是比第3个max-pooling层更加具有全局性的特征。最后,DeepID接一个softmax进行分类。这样提取到的特征是对类间具有很好的判别性的,相当于增加了类间的距离。(从作者的另外一篇文章DeepID2的得出)。
如图所示的Deep ConvNet输入是39x31xk的长方形面片或者是31x31xk的正方形面片,k=3是RGB三通道彩色面片,k=1是灰度图面片。如果输入图的尺寸发生变化,则后面的卷积层的尺寸也要相应发生变化。预测的类别数目发生变化,相应的softmax层输出尺寸也发生变化。DeepID层是固定的160维,不发生改变。卷积过程跟普通的卷积神经网络一样,每个卷积后面的相应函数式ReLU, 被实验证明(在这篇文章中提到)比sigmoid函数的有更好的拟合能力。
3 特征提取
图3, 上半部分:中度尺度的10个人脸区域。上半部分左侧的5个是弱对齐的人脸,右侧的5个,是分别以5个标记点为中心的局部区域。
下半部分:其中2个面片的3中尺度表示。
对人脸图片检测5个标记(包括两个眼睛的中心,鼻尖,和两个嘴角),基于两个眼睛的中心点和两个嘴角的中点对人脸进行全局对齐。特征提取出自60个人脸面片,这60个面片,包含10个不同的区域,3种尺度,RGB或灰度通道。图3是一组示例。
论文中训练了60个ConvNets, 每一个提取2个160维的特征(即一个face patch和该face patch水平翻转后的相对应的face patch). A special case is patches around the two eye centers and the two mouth corners, which are not flipped themselves, but the patches symmetric with them (for example, the flipped counterpart of the patch centered on the left eye is derived by flipping the patch centered on the right eye). The total length of DeepID is 19, 200 (160 × 2 × 60), which is ready for the final face verification.
4 人脸验证
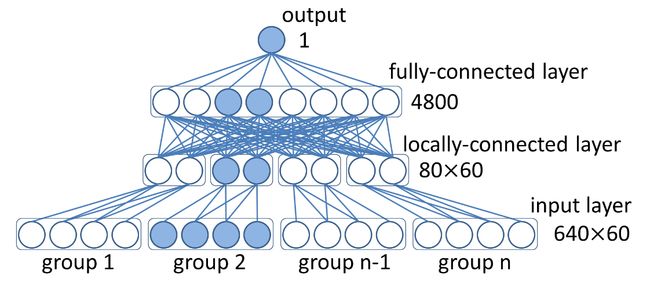
图 4,用于人脸验证的神经网络结构。已经标注了层的类型和维数。
We use the Joint Bayesian technique for face verification based on the DeepID.
该部分的神经网络的输入是60组(前面60个ConvNets的输出),每一组640维,(人脸验证,需要输入两张人脸图片,来判定这两张人脸图片是不是来自同一个人),每一张face patch包括做侧面和右侧面,320维,故每一组共640维。
从face patch学习到的是局部特征,将这些face patch组合起来再训练一个神经网络,这样从局部特征中可以学到一种全局性的特征。
第一个隐藏层和这60组是局部连接的,目的使该隐藏层能够学习到该局部face patch压缩的特征表示,然后这个隐藏层和跟它节点数目相同的隐藏层进行全连接,以求学到全局特征。
最后连接一个二分类器,来判定是否来自同一个人。(The hidden neurons are ReLUs and the output neuron is sigmoid)隐藏层的相应也是用的ReLU,并且同时对所有隐藏层节点使用了dropout方式。使用dropout对于使用梯度法来训练网络是必须的,因为不用dropout而学习高维特征会带来梯度扩散(gradientdiffusion)问题。
5 配置和实验数据