JDK1.8 HashMap 深入理解
转自:http://blog.csdn.net/zdsicecoco/article/details/51775545
一 什么是HashMap,HashMap的工作原理
HashMap是一个基于哈希表的Map接口实现。
首先先看一下,在JDK1.8的时候,HashMap数据存储jniego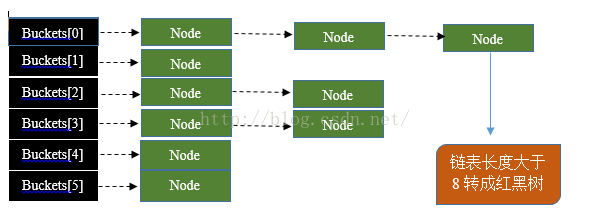
工作原理:
当我们使用put(KEY,VALUE)存储键值对象到HashMap ,首先会对
Key进行哈希计算,就是调用hashcode方法,如果key为空,hash值是0. 并且对hash结果进行位异或运算。
| staticfinal int hash(Objectkey) { int h; return (key ==null) ? 0 : (h =key.hashCode()) ^ (h >>> 16); } |
比如h的值是15 那么就是 key=null?0:(15^(h>>>16));h较小的时候一般为0。
HashMap有一个Node[]数组,即哈希桶数组。Node是啥呢?
| staticclass Node<K,V> implements Map.Entry<K,V> { final inthash; final K key; V value; Node<K,V> next;
Node(inthash, K key, Vvalue, Node<K,V>next) { this.hash =hash; this.key =key; this.value =value; this.next =next; } |
其实Node就是一个基于单向链表数据结构的存储key和value的一个对象。next指向下一个Node.实现了Map.Entry接口
HashMap有几个比较重要的属性:
intthreshod; //存储键值对的极限
final float loadFactor;//加载因子
intmodCount;
intsize;
首先Node[]哈希桶数组默认长度是16,加载因子是0.75。
加载因子是对空间和时间效率的一个平衡,不建议修改。如果内存足够,并且对时间效率要求较高,可以设置大点。可以大于1.
threshold是所能容纳的Node最大数量。threshod=length*loadFactor.比如这里就是16*0.75=12.一旦超过这个threshod这个阀值,就要重新计算size.也就是调用resize方法。
size:当前map时机存储的键值对的数量。他和哈希桶的长度应该区别开。
modCount:主要用来记录HashMap 内部结构发生变化的次数
哈希桶数组的长度length大小必须是2的n次方,一般常规做法是把桶设计为素数,因为素数导致冲突的概率小很多。
即使hash算法设计的再合理,也避免不了链过长的情况,一旦出现链过长,那就查询很慢,严重影响HashMap性能。于是1.8对数据结构作了进一步的优化,引入红黑树,默认超过8时,链表就转化为红黑树,利用红黑树快速增删改查的特点提高hashMap性能。
Put方法分析:
- 判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容
- 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向第6步;如果table[i]不为空,转向第3步
- 判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向第四步,这里的相同指的是hashCode以及equals
- 判断table[i]是否为treeNode,即table[i]是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向第5步;
- 遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可
- 插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
| final V putVal(inthash, K key, Vvalue, booleanonlyIfAbsent, booleanevict) { Node<K,V>[]tab; Node<K,V>p; int n,i; if ((tab =table) == null || (n =tab.length) == 0) n = (tab = resize()).length;//tab为null或者长度为0,则resize //i = (n - 1) & hash 计算存储哈希桶数组的下标 //根据这个下标判断当前这个位置有无Node元素,如果没有则创建Node if ((p =tab[i = (n - 1) &hash]) == null) tab[i] = newNode(hash,key, value,null); else { Node<K,V>e; K k; //判断key是否存在且key是否和链表第一个Node的key相同,如果相同,则覆盖 if (p.hash ==hash && ((k =p.key) == key || (key != null &&key.equals(k)))) e = p; //hash不同,或者key不一样,则判断该链是否是红黑树,如果是添加到红黑树 else if (pinstanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this,tab, hash, key, value); //否则该链为链表 else { for (intbinCount = 0; ; ++binCount) { //判断next是否为空 if ((e =p.next) == null) { //如果为空创建Node,并赋给next p.next = newNode(hash,key, value,null); //如果链表长度大于8,转为红黑树处理 if (binCount >=TREEIFY_THRESHOLD - 1)// -1 for 1st treeifyBin(tab,hash); break; } //判断下一个node的hash和key,如果key相同且hash相同,则覆盖 if (e.hash ==hash && ((k =e.key) == key || (key != null &&key.equals(k)))) break; p = e; } } if (e !=null) { // existing mapping for key VoldValue = e.value; if (!onlyIfAbsent ||oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size >threshold) resize(); afterNodeInsertion(evict); return null; } |
二 HashMap扩容机制:
向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。由于Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组。
JDK1.7实现
| void resize(int newCapacity) { //传入新的容量 Entry[] oldTable = table; //引用扩容前的Entry数组 int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了 threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了 return; }
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组 transfer(newTable); //将数据转移到新的Entry数组里 table = newTable; //HashMap的table属性引用新的Entry数组 threshold = (int)(newCapacity * loadFactor);//修改阈值 }
void transfer(Entry[] newTable) { Entry[] src = table; //src引用了旧的Entry数组 int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组 Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素 if (e != null) { src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象) do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); //重新计算每个元素在数组中的位置 e.next = newTable[i]; //标记[1] newTable[i] = e; //将元素放在数组上 e = next; //访问下一个Entry链上的元素 } while (e != null); } } } |
三 HashMap线程不安全,为什么?
我们知道,HashMap在插入数据的时候,会先检查size有没有超过threshold这个阀值的大小,如果超过了,需要进行resize 扩容操作。
并且把老的哈希桶数组迁移到扩容之后的哈希桶数组中。
我们举个例子:
| publicclass Calcu { privatestatic HashMap<Integer, String> map =new HashMap<Integer, String>(2, 0.75f); publicstatic void main(String[]args) { map.put(5, "C"); new Thread("Thread1") { public void run() { try { Thread.sleep(5); }catch (InterruptedException e) { // TODO Auto-generated catch block e.printStackTrace(); } map.put(7, "B"); System.out.println(map); }; }.start(); new Thread("Thread2") { public void run() { map.put(3, "A"); System.out.println(map); }; }.start(); } } |
我们先让主线程走,线程一二在run方法第一行挂起,然后在放开线程一二结果是:
| void resize(intnewCapacity) { Entry[] oldTable = table; int oldCapacity =oldTable.length; if (oldCapacity ==MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; }
Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity *loadFactor); } void transfer(Entry[]newTable) { Entry[]src = table; int newCapacity =newTable.length; for (intj = 0; j < src.length; j++) { Entry<K,V>e = src[j]; if (e !=null) { src[j] = null; do { Entry<K,V>next = e.next; int i = indexFor(e.hash,newCapacity); e.next = newTable[i]; newTable[i] =e; e = next; }while (e !=null); } } } |
然后断点处设在transfer方法第一行,然后线程一二都在此处挂起。
然后再把断点设在Entry<K,V> next = e.next; 此时线程一挂起,线程二断点设在run方法最后一行代码。
此时线程二已经完成rehash操作,链表重组完成,结果如图:
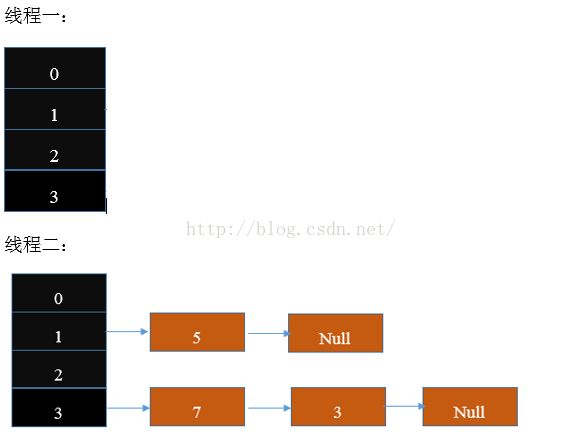
但是这个时候,线程一的e指向的还是key(3) 然后key(3)的next是key(7),指向了新的链表。
放开线程一后:
Entry<K,V>next = e.next;
=>next=key(3).next=key(7);
=>next = key(7);
inti = indexFor(e.hash, newCapacity);
结果i=3;
e.next = newTable[i];
=> e.next = null,也就是说key(3).next =null;
newTable[i] = e;
=>把key(3) 赋给newTable[3]
e = next;
此时e=key(7),即e指向key(7);
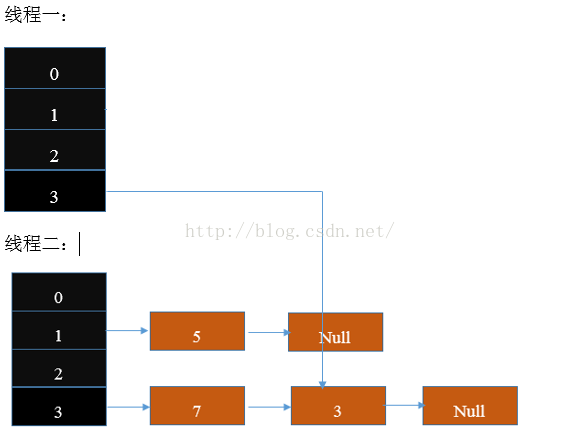
如此,下一次循环,处理key(7),可知
Entry<K,V>next = e.next; //此时key(7)的next就是key(3)
=>next=key(7).next=key(3);
inti = indexFor(e.hash, newCapacity);
结果i=3;
e.next = newTable[i];
=> e.next = key(3),也就是说key(7).next = key(3);
newTable[i] = e;
=>把key(7) 放入桶newTable
e = next;
此时e=key(3),即e指向key(3);
这个过程之后,死循环出现。结果如图示:
四 两个对象的hashcode相同,为有什么结果?如果hashcode相同,如何获取值
如果hashcode相同,发生碰撞的可能性很大。一般会采用开放地址法或者链地址法来解决hash冲突。
先根据hashcode得到元素应该存在哪一个位置,然后找到位置之后,插入到链表中。
如果这样,如何获取值呢?
通过get(key)来获取,在获取的时候,会对key进行一个比较,判断是不是同一个,比较依据就是key的equal方法来判断。