利用Jsoup抓取网络数据
一、了解Jsoup
作用:能够获取网络上的HTML文本内容,并解析HTML标签。
①、获取HTML文档
1、获取String字符串中的HTML内容
方法:
public static Document parse(String html); 示例一
public static Document parse(String html,String baseUrl); 示例二
返回值:Document 代表解析器,等会会提到。
解释:这个方法就是获取文本,返回解析器。
那么第二个方法的baseUrl是干什么用的呢?
有时候我们会在标签上看到:<a href=\"/public\"> 这里是 jsoup 项目的相关文章 </a>
这里的href ="/public"是相对路径,而不是绝对路径。
绝对路径是这样的:href ="http://write.blog.csdn.net/public"
所以为获取到绝对路径:就是baseUrl+/public
调用element.absUrl("href");获取绝对路径。如果还是用elements.attr("href");只能获得相对路径
特殊的方法:
public static Document parseBodyFragment(String html)
public static Document parseBodyFragment(String html,String baseUrl)
作用:让残缺不缺的html片段加上<body>标签
例:现在有<a href=\"/public\">
用了之后其实就变成<body><a href=\"/public\"> </body>
示例一:
public class Main {
public static void main(String[]args){
String html = "<html><head><title> CSDN </title></head>"
+ "<body><a href=\"/public\"> 这里是 jsoup 项目的相关文章 </a></body></html>";
//创建解析文档(相当于解析器)
Document doc = Jsoup.parse(html);
parseHtml(doc);
}
public static void parseHtml(Document doc){
//解析数据,稍后讲到
Elements elements = doc.getElementsByTag("a");
Element element = elements.get(0);
String href = element.attr("href");
String p = element.text();
System.out.println(href);// 返回的结果/public
System.out.println(p);// 返回的结果: 这里是 jsoup 项目的相关文章
}
}
示例二:
public class Main {
public static void main(String[]args){
String html = "<html><head><title> CSDN </title></head>"
+ "<body><a href=\"/public\"> 这里是 jsoup 项目的相关文章 </a></body></html>";
Document doc = Jsoup.parse(html,"http://write.blog.csdn.net/");
parseHtml(doc);
}
public static void parseHtml(Document doc){
//解析数据,稍后讲到
Elements elements = doc.getElementsByTag("a");
Element element = elements.get(0);
//获取绝对路径
String href1 = element.absUrl("href");
//获取相对路径
String href2 = element.attr("href");
String p = element.text();
System.out.println(href1);// 返回的结果 http://write.blog.csdn.net/public
System.out.println(href2);// 返回的结果: /public
}
}
2、获取File文件中的HTML内容
方法:
public static Document parse(File file,String charset)
public static Document parse(File file,String charset,String baseUrl)
作用:从file中获取HTML解析器
baseUrl的作用刚才已经讲了。第一个方法没有baseUrl,则默认为File的路径作为baseUrl。
charset:为字体编码:有 UTF-8 ASCII等
示例:
File file = new File(fileName);
Document doc = Jsoup.parse(file,"UTF-8","http://write.blog.csdn.net/");
其他的地方与上个例子相同。
3、获取网络中的HTML内容
标准写法:
Document doc = Jsoup.connect("http://write.blog.csdn.net/")//连接的网络 .data("query", "Java")//提交的数据 .userAgent("Mozilla")//设置的代理 .cookie("auth", "token")//cookie值 .timeout(3000)//等待连接的时常 .post();//GET传输还时POST传输 视情况而定这样就能从网络中获取html内容了。
不过一般的没必要写怎么长,这么写就可以
<span style="font-size:18px;">Document doc = Jsoup.connect("http://write.blog.csdn.net/").data("key","value").timeout(3000).post();</span>
关于data(String key, String value)上传需要提交的数据有两种写法:
第一种:
String [] keys = {"数据"};
String [] values = {"数据"};
//获取连接的句柄
Connection con = Jsoup.connect("http://write.blog.csdn.net/");
//通过for循环提交相应数据
for(int i=0; i<keys.length; ++i){
con.data(keys[i],values[i])
}第二种:
Map<String,String> map = new HashMap();
map.put("数据","数据");
Connection con = Jsoup.connect("http://write.blog.csdn.net/");
//将map收集到的数据给data
con.data(map);
第一种方法相对来讲比第二种方法方便一点,因为不用弄那么多的put,但是第二种方法在数据少的情况下,不用创建那么多的对象。
②、解析HTML标签
1.首先了解一下解析类的构成
Document 继承 Element 继承 Node。
2、根据这个HTML文本分析:
<span style="font-size:18px;"><html>
<head lang="en">
<meta charset="UTF-8">
<title>CSDN</title>
</head>
<body test="试验">
<a href="/public"> 这里是 jsoup 项目的相关文章 </a>
</body>
</html></span>
就是说<body>标签是一个节点,那么内部的<a>标签是属于<body>节点的。
Node类的作用:获取节点的属性和文本的。
方法:Node
public String attr("attr"); //获取当前节点的具体属性的属性值
public String text();//获取节点内的文本
什么是属性
<body test="试验"> 这个test 就是属性。通过attr()返回的就是属性值。
什么是文本:闭合标签的内部区域
<a>这里就是文本</a>
那么继续
attr("attr")的作用:
比如说我们现在的Node是<body>标签,那么我们只能用attr("attr")获取当前标签的属性,不能获取当前标签内部标签的属性。
就是说 我能够获取 <body>中的text属性 ,无法获得<a>中的href属性。
text()的作用:
但是能够获取节点内部的全部文本。也就是能够获取<body>节点内部<a>的文本。
再了解Element
作用:查找需要的元素。
主要方法:
getElementById(String id):根据标签的id查找元素,因为ID是唯一的,所以返回值为Element
getElementsByTag(String tag):根据标签的名字查找元素
getElementsByClass(String className):根据标签的Class 查找元素
getElementsByAttribute(String key) :根据标签的属性查找元素。
返回值都是Elements类。
Elements:表示Element的集合,相当于List<Element>
因为查找到的标签,可能不唯一,所以返回的是统一类的标签集合。
最后就是Document
作用:获取文本内容之后,返回的文本句柄。相当于一个全局的标签。
二、解析网络上的HTML
①、以B站的搜索为例:http://search.bilibili.com/
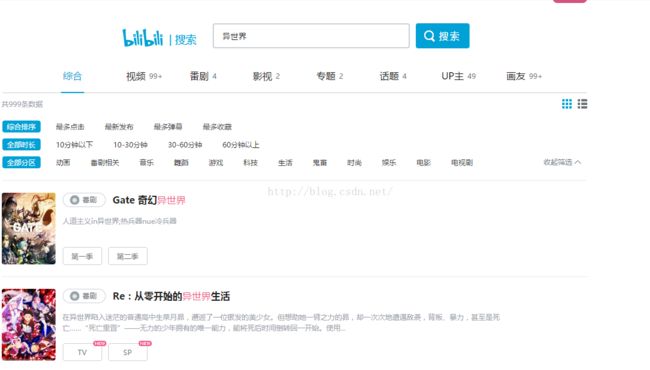
②、打开chrome的开发者工具F12
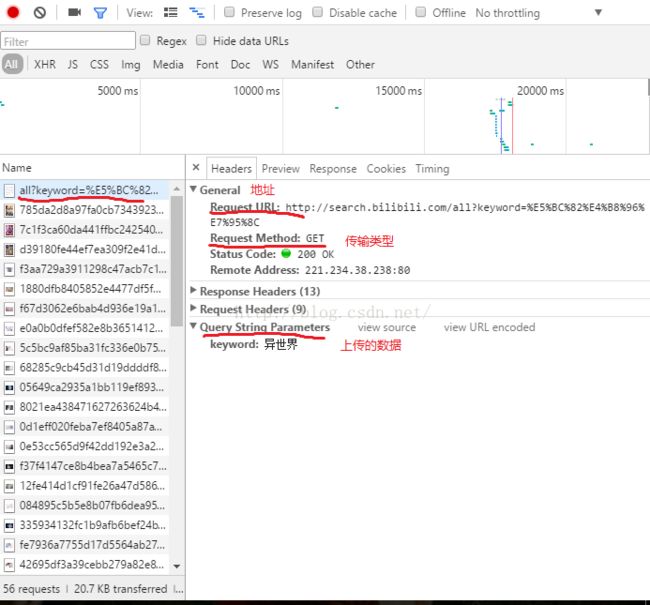
点击all?keyword这个传输文件,我们找到搜索完成后的html地址,传输类型和上传的数据。
③、查看html内容,找到要抓取的html标签

这一部分就是我们想要的内容。
④、前期的准备都完成,那么就开始制作吧
1、首先创建接收数据的封装类DataBean
/**
* 获取B站搜索条的标题和简介
*
*/
public class DataBean {
private String title;
private String brief;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getBrief() {
return brief;
}
public void setBrief(String brief) {
this.brief = brief;
}
}
2、获取HTML文本内容,并进行搜索
public class Main {
//URL路径
private static final String URL = "http://search.bilibili.com/all";
private static Map<String,String> postData = new HashMap<String,String>();
private static List<DataBean> dataBeans = new ArrayList<>();
public static void main(String[]args){
try {
//设置提交的key,value
postData.put("keyword", "异世界");
//根据刚才Chrome传到的参数,设置URL,和传输类型
Document doc = Jsoup.connect(URL)
.data(postData)
.timeout(3000)
.get();
Elements items = doc.getElementsByClass("synthetical");
System.out.println(""+items.size());
for(Element ele : items){
//创建存储类
DataBean dataBean = new DataBean();
//根据文档,解析html文本,获取title
Elements titles = ele.getElementsByClass("title");
dataBean.setTitle(titles.get(0).attr("title"));
//根据文档,解析html文本,获取brief
Elements briefs = ele.getElementsByClass("des");
dataBean.setBrief(briefs.get(0).text());
//装到List中
dataBeans.add(dataBean);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
for(DataBean bean : dataBeans){
System.out.println(bean.toString());
}
}
}
3、了解用选择器查询标签
http://www.open-open.com/jsoup/selector-syntax.htm
进阶:如何持续获取带Cookie并且经过数据加密的html文本