PaxosLease:实现租约的无盘Paxos算法
这篇论文描述了PaxosLease算法,一种用于租约协商的分布式算法。PaxosLease基于Paxos算法,但无需写盘和时钟同步。PaxosLease在开源的分布式复制KV存储Keyspace中被用来做Master租约协商。
1. 介绍
在并发编程中,锁 是进程用来同步共享资源访问的基本原语。在锁以不设置过期时间的方式分配(也没有一个监督进程)的系统中,锁的持有者在释放锁之前如果失效(Failure),就可能导致其它进程阻塞。
在高可用系统中,期望避免单点失效导致整个系统阻塞的情况。另外,“重启”失效的系统会比重启一个多线程程序要更困难。因此,在分布式系统中,租约 取代锁以避免饿死的情况。租约 就是 有过期时间的锁 。如果锁的持有者失效了或是和其它结点断开连接,它的租约会自动过期,其它结点可以得到租约。
我们假设基本的步骤如下:系统由一组请求者和一组接受者组成,请求者和接受者都有各自的算法;系统没有拜占庭问题,即结点之间不会通过不遵守各自算法作弊(也没有被Hack)。接受者的数目是固定不变的。
一个朴素的多数派投票式的算法可以正确地解决分布式租约的问题;这里 正确 的意思是,任何时候租约不会被多于一个结点持有。但是,这个简单的算法在有多个请求者时会频繁 阻塞 ,因此需要一个更成熟的方案。
朴素的多数派算法是这样的: 请求者启动一个开始本地超时计时,超时时间T秒,然后向接受者发送请求时长为T的租约。接受者收到请求后启动一个时长为T秒的定时器,然后发送接受消息给 请求者。超时之后,接受者清除自己的状态。如果接受者收到一个请求但他的状态不是空,则接受者不回应或是发一个拒绝消息。为确保任何时间只有一个请求者能 获得租约,请求者必须收到多数派的接受者的接受消息;这样它获取租约直到它本地的定时器超时。
正如上面讨论的,有多个请求者时,有可能(而且很有可能)没有请求者能得到多数派,请求者会一直互相阻塞着。举个例子,有3个请求者1、2、3和三 个接受者A、B、C,如果分布状态是这样的:A接受1的请求,B接受2的和C接受3的,然后没有一个请求者得到多数派的接受。系统必须等到超时过期,接受 者清空自己的状态,这时请求者会再重试。但很很可能会再次阻塞。
在本文描述的解决方法是采取Paxos [1] 方案,引入 准备 和 提议 阶段,这样可以完全避免这类阻塞问题 [*] 。Paxos解决复制状态机的问题,每个结点有一个本地的状态机拷贝,希望在下一个状态转换时结点间达成一致。Paxos是一个基于多数派的算法,意味 着,多数派的结点没有宕并且之间可以通信,是可能的。Paxos达成一致的处理在一个状态转换上,所以在实践中,需要逐次运行多个Paxos实例来协商出 一序列的状态转换 [3] 。Paxos中,接受者在发送响应之前要先把自己的状态记录到盘上,以保证一旦一个值(状态转换)被选定,之后一直选定该值;换句话说,不管是否有出错情况出现,所有的状态机经历相同的状态转换序列。
不像之前的那些基于Paxos的分布式租约算法,比如Fatlease [5] ,PaxosLease不对结点的本地时钟做任务时间同步的假设(也不需要全局的同步)。另外,Fatlease为了租约命令连续地运行Paxos实例,而PaxosLease利用租约的临时性完全避免了这样的复杂性,是一个更简单和优雅的算法。
PaxosLease是Paxos的一个自然特化变种。因为在Paxos中假设结点个数是固定的(并且结点标识是全局已知的)。PaxosLease处理一个特殊的复制状态机,形式是:

图1:PaxosLease的分布式状态机
为了获得租约,PaxosLease的请求者结点提交的值是“结点i持有租约”,在租约过期后将会自动返回“没有结点持有租约”。请求者也可以延长租约通过在前一次租约过期之前再次提交“结点i持有租约”值,或者在过期之前释放租约(可选操作)。
类似于Paxos,PaxosLease本质上处理了所有有关的失效情况:
- 结点停止和重启
- 网络分割不通
- 消息丢失和乱序
- 传输中的消息延时
2. 定义
一个PaxosLease单元由请求者和接受者组成。我们假设有 n 个接受者和任意个的请求者。在实践中,结点常常会同时扮演请求者和接受者的角色,但这是个实现上的问题不会影响这里的讨论。
请求者发送 准备请求 (Prepare Request)和 提议请求 (Propose Request)消息给接受者;接受者回应的是 准备响应 (Prepare Response)和 提议响应 (Propose Response)消息。这些消息有下面的结构:
- 准备请求 = 投票编号
- 提议请求 = 投票编号,响应结果,已经接受了的提案
- 准备响应 = 投票编号,租约
- 提议响应 = 投票编号,响应结果
投票编号和租约两者组成 提案 (Proposal)。 租约 由 请求者id (希望成为租约持有者的结点)和 时间间隔 T 组成。
接受者存储下面的状态信息:
- 承诺的最高编号: 接受者忽略投票编号小于该值的消息
- 已经接受的提案: 最后一个接受的提案(投票编号 和 租约)
有一个全局已知的最大租约时间 M 。请求者请求的租约时间间隔 T 总是 < M 。
每个请求者的投票编号是全局唯一的并且单调增加。在实践中,实现的方式可以是,投票编号由 请求者id 字段 ,一个 重启计数器 和 一个 请求次数的 计数器 字段 组成(可以处理最坏的情况)。每次请求者启动时重启计数器递增,并写到可靠的存储中。
PaxosLease保证了 租约不变式 :在任何给定的时间点,不会有多余1个请求者持有租约。
3. 基本算法
这一节描述分别从请求者和接受者出发的算法基本流程。请求者发送准备和提议请求,接受者回应准备和提议响应。如果一切正常和话,请求者获得租约花费两轮通信的时间。
- 一个请求者想要获得租约,时长 T < M 。它生成投票编号 [request.ballotNumber],然后发送准备请求给多数派的接受者。
Proposer::Propose() { state.ballotNumber = NextBallotNumber() request.type = PrepareRequest request.ballotNumber = state.ballotNumber Broadcast(request) }
- 接受者,当收到准备请求时,检查 [request.ballotNumber] 是否高于自己在 [state.highestPromised] 里承诺的本地投票编号中的最大值。如果提议请求的投票编号更低则可以丢弃这个消息,或者发送一个响应结果是 拒绝 的准备响应。如果相等或者更高,接受者用 接受 的回答构造一个准备响应,回答中有当前已接受的提案 [state.acceptedProposal] ,提案可以为空。接受者设置已承诺的最高投票编号 [state.highestPromised] 为 请求消息的投票编号 [request.ballotNumber] ,然后把这个准备响应发回给请求者。
Acceptor::OnPrepareRequest() { if (request.ballotNumber < state.highestPromised) return state.highestPromised = request.ballotNumber response.type = PrepareRespose response.ballotNumber = request.ballotNumber response.acceptedProposal = state.acceptedProposal // may be ’empty’ Send(response) }
- 请求者检查从接受者过来的准备响应。如果有多数派的接受者响应的是空的提案,意味着他们可以接受新的提案,请求者可以提交它自己作为租约的获得者,时长是 T 。请求者启动一个定时器,过期时间是 T 秒,发送提议请求,其中包含了投票编号 和 租约(它自己的 请求者id 和 T )。
Proposer::OnPrepareResponse()
{
if (response.ballotNumber != state.ballotNumber)
return // some other proposal
if (response.acceptedProposal == ’empty’)
numOpen++
if (numOpen < majority)
return
state.timeout = T
SetTimeout(state.timeout)
request.type = ProposeRequest
request.ballotNumber = state.ballotNumber
request.proposal.proposerID = self.proposerID
request.proposal.timeout = state.timeout
Broadcast(request)
}
Proposer::OnTimeout()
{
state.ballotNumber = empty // set in Proposer::Propose()
state.leaseOwner = false // set in Proposer::OnProposeResponse()
}
- 接受者,当收到提议请求时,检查投票编号 [request.ballotNumber] 是否高于自己在 [state.highestPromised] 里承诺的本地投票编号中的最大值。如果提议请求的投票编号更低则可以丢弃这个消息,或者发送一个响应结果是 拒绝 的提议响应。如果相等或者更高,接受者接受这个提议:启动过期时间T的超时计时,设置它已接受的提案为这个收到的提案(如果还存着前一个提案,丢弃掉)。接受者用 接受 的回答构造一个提议响应,回答中有投票编号 [request.ballotNumber] 。在超时过期后,接受者重置它已接受的提案为 空 。接受者决不重置它的已承诺的最高投票编号,除非在重启的时候。
Acceptor::OnProposeRequest() { if (request.ballotNumber < state.highestPromised) return state.acceptedProposal = request.proposal SetTimeout(state.acceptedProposal.timeout) response.type = ProposeResponse response.ballotNumber = request.ballotNumber Send(response) } Acceptor::OnTimeout() { state.acceptedProposal = empty }
- 请求者检查提议响应消息。如果有多数派的接受者响应了接受提案,则这个请求者获得了租约直到本地的定时器超时(在第3步中启动)。它收到多数派消息的最后一条的时间点就是它获得租约的时间点,可以切换它的内部状态到“我持有租约”。
Proposer::OnProposeResponse() { if (response.ballotNumber != state.ballotNumber) return // some other proposal numAccepted++ if (numAccepted < majority) return state.leaseOwner = true // I am the lease owner }
可以看到,接受者没有把自己的状态存到存储上。重启时,请求者以空白状态启动。为了保证重启中结点不会破坏租约不变式,结点要在重新加入网络前等待 M 秒。 M 是一个全局已知最大租约时间,所有的结点都知道,请求者请求的租约时长 T 总是< M秒 。
传递都是时间间隔(相对时间),这一点很重要,导致只有获取了租约的请求者才知道自己有租约。该请求者不能告诉其它结点它获取了租约(与经典 Paxos的学习消息类似),因为其它结点不能知道学习消息在传输的过程要消耗多少时间。因此,只有获得了租约的请求者知道它自己持有租约。所有其它的结 点知道的是自己没有获得租约。换句话说,每个请求者关于租约有两种状态:“我没有租约,我也不知道谁持有租约” 和 “我持有租约”。当然,结果可以发出学习消息作为 hint ,这可以用在高级应用中或是用来探索,但这些使用方式超出本论文范围。
有可能一个请求者在第3步和第5步中没有得到多数派接受者赞同响应。这种情况下,请求者可以休眠一会儿再重新从第1步用更高的投票编号执行算法。
4. 租约不变式证明
我们先给出为什么PaxosLease可以工作的直觉感受。图2是以画图方式的解释:请求者在发送提议请求之前开启定时器,接受者只能 一段时间后 开启他们的定时器;接受者在发送提议响应之前开启定时器的。因此,如果有多数派的接受者存下了状态并开启定时器,在请求者定时器过期前,将没有其它的请求者可以得到租约。将没有2个请求者同时认为自己是租约的持有者。
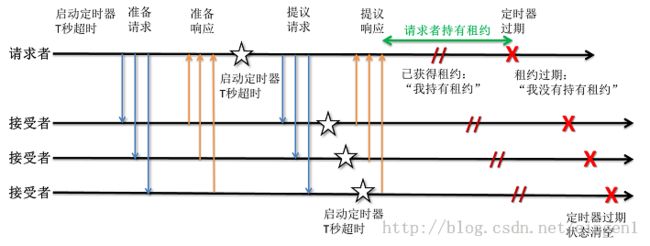
图2:一个请求者获得租约的时间流程图
更正式地说,PaxosLease保证了如果请求者 i 发出的投票编号是 b 和 时长是 T 的提案 从多数派的接受者那里接收到了接受消息,假定请求者在时间点 tnow 启动定时器,那么没有其它请求者能再接收到多数派的接受消息,直到 tend = tstart + T 。
证明:假定请求者 p 用投票编号 b 获得了租约。它从多数派的接受者那里收到了类型是 接受 的空准备响应,在时间点 tstart 启动定时器,在时间点 tacquire 从多数派的接受者那里收到了类型是 接受 的提议响应,这样请求者持有租约直到 tend = tstart + T。令 A1 为用空准备响应回应 p 的准备请求的接受者多数派,令 A2 为接受 p 提案 并且 发送类型是 接受 的准备响应 的接受者多数派。
第一部分: 在 tacquire 到 tend 的时间内,没有其它的请求者 q 能以 b’ < b 的投票编号的请求来获得租约。为了持有租约,请求者 q 必须得到多数派接受者 A’2 的接受。 令 a 为同时在 A’2 和 A1 的接受者。因为 b’ < b , a 必须是先接受了 q 的提案然后发送准备响应给 p 的。但是如果 a 发送一个空准备响应给 p 它的状态必须为空,它的定时器必须已经过期了,即 q 的定时器过期了,因此 q 已经失去了租约。在 p 和 q 的租约之间没有重叠。
第二部分:在 tacquire 到 tend 的时间内,没有其它的请求者 q 能以 b < b’ 的投票编号的请求来获得租约。为了持有租约,请求者 q 必须得到多数派接受者 A’1 给它发送空个准备响应。 令 a 为同时在 A’1 和 A2 的接受者。因为 b < b’ , a 必须是先接受了 p 的提案然后发送准备响应给 q 的。但是既然 a 接受了 p 的提案,如果它发送一个空个准备响应给 q 它的状态必须是空的,它的定时器必须已经过期了,即 p 的定时器过期了,因此 p 已经失去了租约。在 p 和 q 的租约之间没有重叠。
5. 活性(Liveness)
Paxos类型的算法比如PaxosLease,有动态死锁的可能:两个请求者可能连续地生成越来越高的投票编号,发送准备请求给接受者,接受者连续地增加自己承诺的最高投票编号,结果没有请求者可以让接受者接受提案。在实践中,可以通过让请求者在重新执行算法前等待一小段随机的时间来规避。
Paxos类型的算法一个主要的优点是没有静态死锁,在朴素的投票算法中有说到。没有静态死锁是因为请求者可以覆盖接受者的状态,算法又保证了多数派是不会被覆盖的。
6. 延长租约
在某些情况下,一旦一个请求者持有资源后可以持续持有而不是一个原来的租给时间,这一点很重要。一个典型的场景是,在分布式系统中当租约指出Master结点后,期望这个结点可以长时间作为Master。
为了适应这个需求,只要请求者的算法需要修改。要第3步中,如果多数派响应了空的提案或是 已存在提案 (即这个提案中的该请求者的租约还没有过期),它可以再次提议自己为租约的持有者。这样允许请求者延长它的租约 O(T) 的时间。接受者的算法无需修改。
7. 释放租约
到现在的算法描述中,请求者的租约是在一定时间后自动过期的。在一些情况下,尽快释放租约让其它的结点获取是很重要的。一个典型例子是分布式处理,处理进程获得一个资源的租约,执行其上的操作,然后期望尽快释放租约好让其它处理进行获得。
为了适应这个需求,请求者可以发送一个特定释放消息给接受者,消息中包含了它要释放租给的投票编号。在发送释放消息之前,请求者把内部状态从“我持有租约”切换到“我没有持有租约”。当接受者收到释放租约时,查检是否与已接受的投票编号相同。如相同则清空自己的状态;否则不做任何操作。请求者也可以发送一个释放消息给其它请求者作为提示,告诉他们可以去获取租约了。
8. 多个资源的租约
算法定义了关于一个资源 R 的租约动作。在实践中,结点会要处理多个资源,比如一个分布式处理中要用的租约。PaxosLease可以为各个资源运行独立的实例,不同的实例的消息、请求者和接受者状态标志上 资源标识 。一个结点作为请求者和接受者,每个PaxosLease实例消耗内存不超过 ~100字节,这样结点上1G内存可以处理 ~1千万个资源租约。再加上PaxosLease不需要硬盘同步和时钟同步,该算法可以用在很多需要细粒度锁的场景上。
9. 实现
在Scalien的分布式复制key-value存储Keyspace中 [†]译注,PaxosLease用于Master的租约协商。Keyspace作为PaxosLease的参考实现,包含了很多实践上的优化。由于基于开源AGPL许可 [6] ,感兴趣的读者可以自由获取Keyspace实现。源代码和二进制文件可以在 http://scalien.com [‡]译注 下载。
10. 宗谱
Leslie Lamport在1990年发明Paxos算法,但在1998才发表的。这篇论文《The Part-Time Parliament》对于很多读者过于极客,这导致第二篇论文《Paxos Made Simple》 [2] 。Paxos通过引入个准备和提议两个阶段和让接受者在响应消息前把自己状态写入稳定存储,解决了发布式一致性问题。多轮的Paxos可以顺序运行以协调复制状态机的状态转换。
在论文《Paxos Made Live - An Engineering Perspective》和《The Chubby Lock Service for Loosely-Coupled Distributed Systems》 [4] 中描述的Google内部的分布式实现栈用了Paxos,这让Paxos流行起来。在Google的Chubby中,多轮顺序执行Paxos以达到,在复制数据库中下次写操作上的一致性,提供了思考复制状态机的另一种方法。
《FaTLease: Scalable Fault-Tolerant Lease Negotiation with Paxos》中描述的Fatlease解决了和PaxosLease一样的问题,但它结构更复杂,因为模仿了在Google论文中提到的多轮Paxos, 而不是PaxosLease所用的简单的接受者状态超时。另外,FaTLease需要结点同步他们的时钟,这一点使的它在现实世界使用中没有吸引力。 PaxosLease灵感来自于FaTLease,解决了上述的缺点。
参考文献
| [1 ] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] | AGPL License. http://www.fsf.org/licensing/licenses/agpl-3.0.html |
注释
| [*] | 另一个解决方法是,让系统阻塞,但是引入一个“撤销”机制,让请求者撤销他的请求从而让某个其它的请求者可以获得租约。 |
| [†] | 译注,scalien的GitHub代码工程在 https://github.com/scalien |
| [‡] | 译注,这个网站已经没有内容了,Keyspace源代码可以在 https://github.com/scalien/keyspace 下载。 |
Paxos算法 Paxos Made Simple
目录(?)[+]
Paxos算法
Paxos Made Simple
Leslie Lamport
2001.11.1
简介
Paxos算法,纯文本方式描述,非常简单。
1 介绍
为 实现具有容错能力的分布式系统而提出的Paxos算法,曾被认为难以理解,可能因为对于大部分读者而言,原来的描述是基于希腊故事的[5]。【为了描述 Paxos算法,Lamport设计了一个虚拟的希腊城邦Paxos】实际上,它是最简单和直观的分布式算法之一【这个…,其实没那么简单吧】。它的核心 是一个一致性算法——[5]中提出的“synod”算法。下一节描述这个一致性算法,并遵从我们要求的性质。最后一节解释了完整的Paxos算法,从一致 性的直观应用到构建分布式系统的有限状态机模型——应该是总所周知的模型,因为它是论文[5]的主题——它可能是分布式系统理论被引用最多的论文。
2 一致性算法
2.1 问题的提出
设想一组可以提出决议(value)的process。一致性算法保证所有提出的决议中,有一个决议会被选择(chosen)。如果没有提出决议,那么将不会有选择。如果一个决议被选择,那么process最终都能知道这个被选择的决议。一致性的安全性包括:
——决议只有被提出后才可能被选择,
——只有一个决议被选择,并且
——process永远不会获知一个决议被选择了,除非这个决议确实已经被选择。
我们将不会特别明确精确的时间性要求。然而,其目标是最终有一个提出的决议被选择,并且process最终会获知被选择的决议,如果有的话。
我们为一致性算法划分3个角色,并分别以代理:proposer(提出者),acceptor(批准者)和listener(接收者)表示。实现中,允许一个process扮演多个代理,这里我们不关心从代理到process的映射。
假设代理之间用消息通信。我们采用异步、非拜占庭模型【拜占庭模型(Byzantine model),消息可能丢失、重复或者内容损坏。换而言之,非拜占庭模型就是允许消息的丢失或者重复,但是不会出现内容损坏的情况】:
——代理以任意的速度操作,可能会因为停机而失效,可能会重启。因为任一个代理都可能会在决议被选择后停机再重启,因此解决方案要求代理必须能够记忆某些信息,从而能在重启后重新载入。
——消息传送速度不可预测,可能会重复或丢失,但是内容不会损坏。
2.2 选择决议
最简单的方法就是用单个acceptor代理。Proposer发送议案(proposal)给这个acceptor,它选择最先收到的议案。尽管简单,但是如果acceptor停机了,那么系统就不能继续运行了,这个方案并不能满足要求。【明显的单点问题】
看 来我们需要选择另外的方法,我们用多个acceptor代理,而非一个,proposer向一组acceptor提出议案。一个acceptor可能批准 该议案,当有足够大的acceptor集合批准了这个议案时,决议【议案是一个{编号,决议}对】就被选择了。那么这个集合多大才足够呢?为了保证只有一 个决议被选择,我们可以让这个集合包含多数的代理【后面也会称之为多数派】。因为任意两个多数派至少有一个相同的代理,如果一个acceptor最多只能 批准一个决议,这就是可行的。
假设没有失败或者消息丢失,即使仅有一个proposer提出了一个决议,我们也希望能选择一个决议。这就导出了下面的需求:
P1. Acceptor必须批准它接收到的第一个决议。
但 是该需求会导致一个问题。同时可能有几个proposer提出了几个不同的决议,从而导致每个acceptor都批准了一个决议,但是没有一个决议被多数 派批准。即使只有两个决议,如果每个都被半数的acceptor批准,单个的acceptor失效也会导致不可能知道到底哪个决议被选择了。
一个 决议要经过多数派的批准才能被选择,这个需求和P1暗示了acceptor必须能够批准多个议案。我们为每个议案分配一个编号来记录不同的议案,因此一个 议案由编号和决议构成【也就是议案={编号,决议}】。为避免混淆,我们要求议案的编号是唯一的。这个取决于实现,我们假设可以做到这一点。如果一个议案 {n, v}通过多数派的批准,那么决议v就被选择了。这种情况下,我们称议案(包括其决议v)被选择了。
我们允许选择多个议案,但是必须保证所有选择的议案包括相同的决议。对议案编号归纳,可以保证:
P2. 如果一个议案{n, v}被选择,那么所有被选择的议案(编号更高)包含的决议都是v。
因为编号是全序的,P2保证了“只有一个决议被选择”这一关键安全属性。议案必须至少被一个acceptor批准才可能被选择。因此只要满足下面的条件,就可以满足P2:
P2A. 如果一个议案{n, v}被选择,那么任何acceptor批准的议案(编号更高)包含的决议都是v。
我 们依然保证P1来确认选择了某些议案。因为通信是异步的,在特殊情况下,某些acceptor c没有接收到过任何议案,它们可能会【错误的】批准一个议案。设想一个新的proposer“醒来”并提出了一个更高编号的议案(包含不同的决议)。根据 P1的要求,c应该批准这个议案,但是这违反了P2A。为了同时保证P1和P2A,我们需要增强P2A:
P2B. 如果一个议案{n, v}被选择,那么此后,任何proposer提出的议案(编号更高)包含的决议都是v。
因为一个议案必须在被proposer提出后才能被acceptor批准,因此P2B包含了P2A,进而包含了P2。
如 何才能满足P2B呢,让我们来考虑如何证明它是成立的。我们假设某个议案{m, v}被选择,然后证明任何编号n>m的议案的决议都是v。对n归纳可以简化证明,根据条件:每个提出的议案(编号从m到n-1)的决议都是v,我们 可以证明编号为n的议案的决议是v。对于选择的议案(编号为m),必定存在一个集合C(acceptor的多数派),C中的每个acceptor都批准了 该议案。结合归纳假设,m被选择这一前提意味着:
C中的每个acceptor都批准了一个编号在m到n-1范围内的议案,并且议案的决议为v。
因为任何由多数派组成的集合S都至少包含C中的一个成员,我们可以得出结论:如果下面的不变性成立,那么编号为n的议案的决议就是v:
P2C. 对于任意的v和n,如果议案{n, v}被提出,那么存在一个由acceptor的多数派组成的集合S,或者a) S中没有acceptor批准过编号小于n的议案,或者b) 在S的任何acceptor批准的所有议案(编号小于n)中,v是编号最大的议案的决议。
通过保持P2C,我们就能满足P2B。
为 了保持不变性P2C,准备提出议案(编号为n)的proposer必须知道所有编号小于n的议案中编号最大的那个,如果存在的话,它已经或将要被 acceptor的某个多数派批准。获取已经批准的议案是简单的,但是预知将来可能批准的议案是困难的。Proposer并不做预测,而是假定不会有这样 的情况。也就是说,proposer要求acceptor不能批准任何编号小于n的议案。这引出了下面提出议案的算法【这就是两阶段提交了】。
1 proposer选择一个新编号n,向某个acceptor集合中的所有成员发送请求,【prepare请求阶段,n是prepare请求的编号,也是下面accept请求的议案编号】并要求回应:
a) 一个永不批准编号小于n的议案的承诺,以及
b) 在它已经批准的所有编号小于n的议案中,编号最大的议案,如果存在的话。
我把这样的请求称为prepare请求n。
2 如果proposer收到了多数acceptor的回应,那么它就可以提出议案{n, v},其中v是所有回应中编号最高的议案的决议,或者是proposer选择的任意值,如果acceptor们回应说还没有批准过议案。
一个proposer向一个acceptor集合发送已经被批准的议案(不一定是回应proposer初始请求的acceptor集合),我们称之为accept请求。
我 们已经描述了proposer的算法。那么acceptor呢?它可以接收两种来自proposer的请求: prepare请求和accept请求。Acceptor可以忽略任何请求,而不用担心安全性。因此,我们只需要描述它需要回应请求的情况。任何时候它都 可以回应prepare请求【本文中,回应就意味着接受了这个prepare请求和编号n】,它可以回应accept请求,并批准议案,当且仅当它没有承 诺过【承诺批准或批准一个更高编号的议案】。换句话讲:
P1A. acceptor可以批准一个编号为n的议案,当且仅当它没有回应过一个编号大于n的prepare请求。
P1A蕴含了P1。
现在我们得到了一个完整的决议选择算法,并满足我们要求的安全属性——假设议案编号唯一。通过一些简单优化就能得到最终算法。
假 设一个acceptor接收到一个编号为n的prepare请求,但是它已经回应了一个编号大于n的prepare请求。于是acceptor就没有必要 回应这个prepare请求了,因为它不会批准这个编号为n的议案。它还可以忽略已经批准过的议案的prepare请求。
有了这些优 化,acceptor只需要保存它已经批准的最高编号的议案(包括编号和决议),以及它已经回应的所有prepare请求的最高编号。因为任何情况下,都 需要保证P2C,acceptor必须记住这些信息,包括失效并重启之后。注意,proposer可以随意的抛弃一个议案——只要它永远不会使用相同的编 号来提出另一个议案。
结合proposer和acceptor的行为,我们将把算法可以分为两个阶段来执行。
阶段1.
a) Proposer选择一个议案编号n,向acceptor的多数派发送编号也为n的prepare请求。
b) Acceptor:如果接收到的prepare请求的编号n大于它已经回应的任何prepare请求,它就回应已经批准的编号最高的议案(如果有的话),并承诺不再回应任何编号小于n的议案;
阶段2.
a) Proposer:如果收到了多数acceptor对prepare请求(编号为n)的回应,它就向这些acceptor发送议案{n, v}的accept请求,其中v是所有回应中编号最高的议案的决议,或者是proposer选择的值,如果回应说还没有议案。
b) Acceptor:如果收到了议案{n, v}的accept请求,它就批准该议案,除非它已经回应了一个编号大于n的议案。
Proposer 可以提出多个议案,只要它遵循上面的算法。它可以在任何时刻放弃一个议案。(这不会破坏正确性,即使在议案被放弃后,议案的请求或者回应消息才到达目标) 如果其它的proposer已经开始提出更高编号的议案,那么最好能放弃当前的议案。因此,如果acceptor忽略一个prepare或者accept 请求(因为已经收到了更高编号的prepare请求),它应该告知proposer放弃议案。这是一个性能优化,而不影响正确性。
2.3 获知选择的决议
Learner 必须找到一个被多数acceptor批准的议案,才能知道一个决议被选择了。一个显而易见的算法就是,让每个acceptor在批准议案时通知所有的 learner。于是learner可以尽快知道选择的决议,但是要求每个acceptor通知每个learner——需要的消息个数等于learner 数和acceptor数的乘积。
基于非拜占庭假设,一个learner可以从另一个learner得知被选择的决议。我们可以让acceptor 将批准情况回应给一个主Learner,它再把被选择的决议通知给其它的learner。这增加了一次额外的消息传递,也不可靠,因为主learner可 能会失效,但是要求的消息个数仅是learner数和acceptor数的总和。
更一般的,可以有多个主Learner,每个都能通知其它所有的acceptor。主learner越多越可靠,但是通信代价会增加【消息个数越多】。
由 于消息丢失,可能没有learner知道选择了一个决议。Learner可以向acceptor询问批准的议案,但是由于acceptor的失效,可能难 以得知多数派是否批准了一个议案。这样,learner只能在新的议案被选择时才能知道acceptor选择的决议。如果learner需要知道是否已经 选择了一个决议,它可以让proposer根据上面的算法提出一个议案【提出请求就有回应,并且新的提案的决议就是当前选择的决议】。
2.4 处理流程
很 容易构造这样一个场景,两个proposer轮流提出一系列编号递增的议案,但是都没有被选择。Propoer p选择议案的编号为n1,并结束阶段1。接着,另外一个proposer q选择了议案编号n2>n1,并结束阶段1。于是p在阶段2的accept请求将被忽略,因为acceptor已经承诺不再批准编号小于n2的议 案。于是p再回到阶段1并选择了编号n3 > n2,这又导致q第二阶段的accept请求被忽略,…
为了保证流程,必须选择一个主 proposer,只有主proposer才能提出议案。如果主proposer和多数acceptor成功通信,并提出一个编号更高的议案,议案将被批 准。如果它得知已经有编号更高的议案,它将放弃当前的议案,并最终能选择一个足够大的编号。
如果系统中有足够的组件 (proposer,acceptor和网络)能正常工作,通过选择一个主proposer,系统就能保持响应。Fischer、Lynch和 Patterson的著名结论[1]表明:选择proposer的可靠算法必须是随机的或者实时的——例如,使用超时机制。然而不管选择成功与否,安全性 都能得到保证。
2.5 实现
Paxos算法[5]假设了一组网络进程。在其一致性算法中,每个 process都同时扮演proposer、acceptor和learner的角色。算法选择一个leader,它就是主proposer和主 learner。Paxos一致性算法就是上面描述的那个,请求和响应都用消息发送(响应会被打上对应议案的编号,以防止混淆)。使用持久化存储来保证 acceptor失效后也能记起必要的信息。Acceptor在发送响应前必须持久化存储该响应。
接下来就是描述保证任何两个议案的编号都不相同 的机制。proposer从互不相交的集合中选择议案编号,因此两个不同的proposer永远不会提出相同编号的议案。【假设有5个proposer, 编号为0~4,可以使proposer i的议案编号选择序列为:5*j + i(j >= 0),就能保证永不重复,且递增】每个proposer都持久化保存它已经提出的编号最高的议案,并使用一个更高的议案编号来开始阶段1。
3 实现状态机模型
实 现分布式系统的简单方式就是使用一些客户端向中心服务器发送命令【就是C/S模式了】。服务器可以看作是根据一定顺序执行客户端命令的确定状态自动机。状 态机包含当前状态,每读入一个命令并产生相应的结果,它就执行一步。比如,分布式银行系统的客户端可能是出纳员,状态机的状态由所有用户的账户余额构成。 取款操作将会执行一条状态机命令:减少账户余额,输出新旧余额数(当且仅当余额大于取款值)。
使用单个中心服务器的实现是不可靠的,因此我们使用一组服务器,每一个都独立的执行状态机。因为状态机是确定的,如果执行相同的命令序列,所有的服务器将会产生同样的状态序列和输出【非拜占庭模型假设再一次起作用了】。客户端发起命令后,可以使用任何服务器的输出。
为 了保证所有的服务器执行的是相同的命令序列,我们执行一个paxos一致性算法的实例(instance)序列【注解#】,每个实例是一个独立运行的 paxos一致性算法,第i个实例选择的决议就是序列的第i个状态机命令。在算法的每个实例中,每个server都扮演所有的角色(proposer、 acceptor和learner)。现在,假设服务器组固定,所有的实例都使用相同的代理。
【注解#】
某些资料会把“实例”称为“轮” (round),每轮选择一个决议,但每轮可能会执行多次一致性算法,比如如果主proposer在阶段1提出的prepare请求被否决了,那么它将会 选择新的议案编号,重新提出议案请求,直到议案被多数acceptor批准(消息发送失败也会导致重传请求)。引入轮(就是实例啦)这一概念后,可以做到 各轮并行运行,同时批准多个决议,互不干涉,更有效率。
【end #】
正常操作下,一个服务器被选择为leader,它就是所有的实例的 主proposer(唯一能够提出议案的)。客户端向leader发送命令,leader决定命令的顺序。如果leader决定某个客户端命令应该是第 15个命令,它将试图把该命令选择为第135个实例的决议,通常都能成功。有可能因为失效而失败,或者另外的一个服务器相信它是leader,有另外的选 择。但是一致性算法保证最多只能有一个命令被选成第135个。
Paxos一致性算法有效性的关键在于,决议直到阶段2才会真正提出。回忆 proposer算法的阶段1结束后,或者要提的决议已经决定了,或者proposer可以提出任何决议。我将描述正常操作下Paxos状态机的执行情 况。接下来,再讨论可能的错误情况。我会考虑前一个leader失效、新的leader被选择后会发生什么情况(系统启动是个特例,这时还没有提出命 令)。
【在下面的部分,因为客户端的命令就是议案的决议,因此决议就是命令,会混用,并不影响理解】
在一致性算法的所有实例中,新的 leader也是learner,应该知道已经选择的命令。假设它知道命令1–134、138和139——也就是算法实例1–134、138和139选择 的决议(后面将看到命令序列中的间隔是如何引起的)。然后leader为实例135-137和所有大于139的实例执行阶段1(后面会说明是怎么做到 的)。假设这些执行的输出将决定实例135和140提出的决议,但是不会影响其它实例的决议。然后leader为实例135和140执行阶段2,并选择了 第135和140个命令。
Leader和其它所有知道leader命令的服务器,现在可以执行命令1-135。但是不能执行命令 138-140(虽然它们也知道),因为必须选择命令136和137。Leader也可以把客户端提出的后面两个命令选为命令136和137。我们希望尽 快的消除间隔,于是为命令136和137提出一个特殊的“noop”命令(不改变状态)(为命令136和137执行阶段2)。一旦noop命令被选择,命 令138-140就能执行了。
现在命令1-140已经被选择了。Leader还已经为所有大于140的实例完成了一致性算法的阶段1的操作【注解*】,并可以在阶段2中提出任何决议。它把客户端的下一条命令编号为141,并当作实例141的阶段2的决议。再把下一条编号为142,以此执行。
【注解*】
对于同一个leader而言,如果它在执行实例i中执行了阶段1,那么后续的执行实例就不需要再次执行阶段1了,而直接执行阶段2,原因如下:
1. 因为它提出的议案编号总是递增的,acceptor必定接受阶段1的prepare请求;
2. 每个实例都是独立运行的paxos算法,互不干扰,决议互相独立;
减少了一个阶段,效率也必定有所提高。
【end*】
在 知道提出的命令141被选择之前,Leader可以提出命令142。它提出命令141的消息可能都丢失了,还可能在其他服务器知道leader提出命令 141之前,命令142已经被选择了。 当leader在实例141的阶段2中没有收到期望的回应后,它将重传这些消息。如果一切顺利,它提出的命令将被选择。然而,也可能会失败,在命令序列中 留下了一个间隔。一般来说,假设leader可以预取r个命令——也就是说,在命令1到i被选择之后,它就可以同步提出命令i+1, …, i+r。那么最多可以产生r-1个间隔【容易理解,前面的r-1个命令都失败了】。
新选出的leader要为算法的无限个实例执行阶段1——在上 面的场景中,是实例135-137,和139之后的所有实例【我的理解是,为了这些实例,它总共只需要成功的执行一次阶段1,理由见上面的注解*,当然多 次执行也不会出问题,就像下面所说的那样】。它可以向其他的服务器发送一条简单的合理短消息,并为所有实例使用相同的议案编号。在阶段1,仅当 acceptor已经收到了一个来自其它proposer的阶段2的消息时,除了简单的OK,它的回应会包含额外的消息,(在上述场景中,仅实例135和 140是这样的【像前面所描述的,实例135-137和139执行的输出将决定实例135和140提出的决议】)。因此,服务器(作为acceptor) 可以为所有实例回应一条简单的短消息。多次执行阶段1并不会出问题。
因为leader的失效和由此引发的选举应该是小概率事件,有效执行一条状态 机命令的开销——达到对命令/决议的一致性——仅仅是一致性算法的阶段2的开销【又一次验证了阶段1并不需要多次执行】。可以证明,在允许失效的情况下, 在所有的同类(一致性)算法中, paxos一致性算法的阶段2具有最小可能的【时间】复杂度[2]。因此paxos算法在本质上就是优化的。
上 面对系统正常操作的讨论假设一直存在单个leader,除去在当前leader失效和选举新leader之间的一小段时间。在异常环境中,leader选 择可能失败。如果没有服务器被选为leader,那么将不能接受命令。如果多个服务器都认为自己是leader,在同一个算法实例中,它们将都能提出议 案,这可能会导致所有的议案都不能被选择。然而,安全属性是满足的——两个不同的服务器将永远不会在第i个状态机命令的选择上达成一致。选择单一的 leader只是为了保证流程【避免冲突】。
如果服务器组可以变动,必须有方法能检测哪些服务器执行的是算法的哪些实例。最简单的做法就是让状态 机自己检测。当前的服务器组可以作为状态的一部分,并能被原生的状态机命令修改。我们可以让leader预取r个命令,并将执行算法实例i+r的服务器组 的状态设置成执行第i个状态机命令后的状态。于是你可以使用简单的重配置算法来进一步增强算法的可靠性【如果半数服务器同时失效,重配置机制也束手无策, 然而这种概率太低了】。
【下面wiki的两篇文章也是paxos很好的参考资料,一篇中文,一篇英文,然而内容并不重复】
http://en.wikipedia.org/wiki/Paxos_algorithm
http://www.wikilib.com/wiki/Paxos%E7%AE%97%E6%B3%95
【还有两个重要的问题就是如何选举leader,以及server间数据的同步,可以参看zookeeper的实现;这些内容整理好下次再单独发出来:)】
参考文献
[1] Michael J. Fischer, Nancy Lynch, and Michael S. Paterson. Impossibility of distributed consensus with one faulty process. Journal of the ACM, 32(2):374–382, April 1985.
[2] Idit Keidar and Sergio Rajsbaum. On the cost of fault-tolerant consensus when there are no faults—a tutorial. TechnicalReport MIT-LCS-TR-821, Laboratory for Computer Science, Massachusetts Institute Technology, Cambridge, MA, 02139, May 2001. also published in SIGACT News 32(2) (June 2001).
[3] Leslie Lamport. The implementation of reliable distributed multiprocess systems. Computer Networks, 2:95–114, 1978.
[4] Leslie Lamport. Time, clocks, and the ordering of events in a distributed system. Communications of the ACM, 21(7):558–565, July 1978.
[5] Leslie Lamport. The part-time parliament. ACM Transactions on Computer Systems, 16(2):133–169, May 1998.