大数据计算新贵Spark在腾讯雅虎优酷成功应用解析
【编者按】MapReduce由于其设计上的约束只适合处理离线计算,在实时查询和迭代计算上仍有较大的不足,而随着业务的发展,业界对实时查询和迭代分析有更多的需求,单纯依靠MapReduce框架已经不能满足业务的需求了。Spark由于其可伸缩、基于内存计算等特点,且可以直接读写Hadoop上任何格式的数据,成为满足业务需求的最佳候选者。本文来自腾讯大数据。
 免费订阅“CSDN云计算”微信公众号,实时掌握第一手云中消息!
免费订阅“CSDN云计算”微信公众号,实时掌握第一手云中消息!
CSDN作为国内最专业的云计算服务平台,提供云计算、大数据、虚拟化、数据中心、OpenStack、CloudStack、Hadoop、Spark、机器学习、智能算法等相关云计算观点,云计算技术,云计算平台,云计算实践,云计算产业资讯等服务。
以下为原文:
Spark作为Apache顶级的开源项目,项目主页见http://spark.apache.org。在迭代计算,交互式查询计算以及批量流计算方面都有相关的子项目,如Shark、Spark Streaming、MLbase、GraphX、SparkR等。从13年起Spark开始举行了自已的Spark Summit会议,会议网址见http://spark-summit.org。Amplab实验室单独成立了独立公司Databricks来支持Spark的研发。
为了满足挖掘分析与交互式实时查询的计算需求,腾讯大数据使用了Spark平台来支持挖掘分析类计算、交互式实时查询计算以及允许误差范围的快速查询计算,目前腾讯大数据拥有超过200台的Spark集群,并独立维护Spark和Shark分支。Spark集群已稳定运行2年,我们积累了大量的案例和运营经验能力,另外多个业务的大数据查询与分析应用,已在陆续上线并稳定运行。在SQL查询性能方面普遍比MapReduce高出2倍以上,利用内存计算和内存表的特性,性能至少在10倍以上。在迭代计算与挖掘分析方面,精准推荐将小时和天级别的模型训练转变为Spark的分钟级别的训练,同时简洁的编程接口使得算法实现比MR在时间成本和代码量上高出许多。
Spark VS MapReduce
尽管MapReduce适用大多数批处理工作,并且在大数据时代成为企业大数据处理的首选技术,但由于以下几个限制,它对一些场景并不是最优选择:
- 缺少对迭代计算以及DAG运算的支持
- Shuffle过程多次排序和落地,MR之间的数据需要落Hdfs文件系统
Spark在很多方面都弥补了MapReduce的不足,比MapReduce的通用性更好,迭代运算效率更高,作业延迟更低,它的主要优势包括:
- 提供了一套支持DAG图的分布式并行计算的编程框架,减少多次计算之间中间结果写到Hdfs的开销
- 提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销
- 使用多线程池模型来减少task启动开稍,shuffle过程中避免不必要的sort操作以及减少磁盘IO操作
- 广泛的数据集操作类型
MapReduce由于其设计上的约束只适合处理离线计算,在实时查询和迭代计算上仍有较大的不足,而随着业务的发展,业界对实时查询和迭代分析有更多的需求,单纯依靠MapReduce框架已经不能满足业务的需求了。Spark由于其可伸缩、基于内存计算等特点,且可以直接读写Hadoop上任何格式的数据,成为满足业务需求的最佳候选者。
应用Spark的成功案例
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。
这些应用场景的普遍特点是计算量大、效率要求高。Spark恰恰满足了这些要求,该项目一经推出便受到开源社区的广泛关注和好评。并在近两年内发展成为大数据处理领域最炙手可热的开源项目。
本章将列举国内外应用Spark的成功案例。
1. 腾讯
广点通是最早使用Spark的应用之一。腾讯大数据精准推荐借助Spark快速迭代的优势,围绕“数据+算法+系统”这套技术方案,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上,支持每天上百亿的请求量。
基于日志数据的快速查询系统业务构建于Spark之上的Shark,利用其快速查询以及内存表等优势,承担了日志数据的即席查询工作。在性能方面,普遍比Hive高2-10倍,如果使用内存表的功能,性能将会比Hive快百倍。
2. Yahoo
Yahoo将Spark用在Audience Expansion中的应用。Audience Expansion是广告中寻找目标用户的一种方法:首先广告者提供一些观看了广告并且购买产品的样本客户,据此进行学习,寻找更多可能转化的用户,对他们定向广告。Yahoo采用的算法是logistic regression。同时由于有些SQL负载需要更高的服务质量,又加入了专门跑Shark的大内存集群,用于取代商业BI/OLAP工具,承担报表/仪表盘和交互式/即席查询,同时与桌面BI工具对接。目前在Yahoo部署的Spark集群有112台节点,9.2TB内存。
3. 淘宝
阿里搜索和广告业务,最初使用Mahout或者自己写的MR来解决复杂的机器学习,导致效率低而且代码不易维护。淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。将Spark运用于淘宝的推荐相关算法上,同时还利用Graphx解决了许多生产问题,包括以下计算场景:基于度分布的中枢节点发现、基于最大连通图的社区发现、基于三角形计数的关系衡量、基于随机游走的用户属性传播等。
4. 优酷土豆
优酷土豆在使用Hadoop集群的突出问题主要包括:第一是商业智能BI方面,分析师提交任务之后需要等待很久才得到结果;第二就是大数据量计算,比如进行一些模拟广告投放之时,计算量非常大的同时对效率要求也比较高,最后就是机器学习和图计算的迭代运算也是需要耗费大量资源且速度很慢。
最终发现这些应用场景并不适合在MapReduce里面去处理。通过对比,发现Spark性能比MapReduce提升很多。首先,交互查询响应快,性能比Hadoop提高若干倍;模拟广告投放计算效率高、延迟小(同hadoop比延迟至少降低一个数量级);机器学习、图计算等迭代计算,大大减少了网络传输、数据落地等,极大的提高的计算性能。目前Spark已经广泛使用在优酷土豆的视频推荐(图计算)、广告业务等。
Spark与Shark的原理
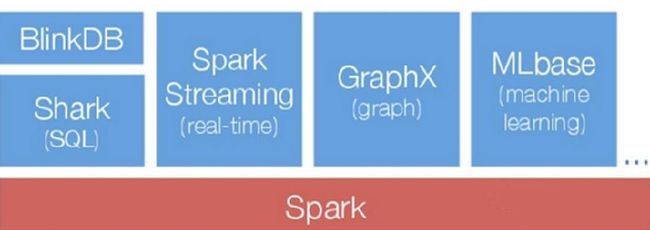
1.Spark生态圈
如下图所示为Spark的整个生态圈,最底层为资源管理器,采用Mesos、Yarn等资源管理集群或者Spark自带的Standalone模式,底层存储为文件系统或者其他格式的存储系统如HBase。Spark作为计算框架,为上层多种应用提供服务。Graphx和MLBase提供数据挖掘服务,如图计算和挖掘迭代计算等。Shark提供SQL查询服务,兼容Hive语法,性能比Hive快3-50倍,BlinkDB是一个通过权衡数据精确度来提升查询晌应时间的交互SQL查询引擎,二者都可作为交互式查询使用。Spark Streaming将流式计算分解成一系列短小的批处理计算,并且提供高可靠和吞吐量服务。
2.Spark基本原理
Spark运行框架如下图所示,首先有集群资源管理服务(Cluster Manager)和运行作业任务的结点(Worker Node),然后就是每个应用的任务控制结点Driver和每个机器节点上有具体任务的执行进程(Executor)。

与MR计算框架相比,Executor有二个优点:一个是多线程来执行具体的任务,而不是像MR那样采用进程模型,减少了任务的启动开稍。二个是Executor上会有一个BlockManager存储模块,类似于KV系统(内存和磁盘共同作为存储设备),当需要迭代多轮时,可以将中间过程的数据先放到这个存储系统上,下次需要时直接读该存储上数据,而不需要读写到hdfs等相关的文件系统里,或者在交互式查询场景下,事先将表Cache到该存储系统上,提高读写IO性能。另外Spark在做Shuffle时,在Groupby,Join等场景下去掉了不必要的Sort操作,相比于MapReduce只有Map和Reduce二种模式,Spark还提供了更加丰富全面的运算操作如filter,groupby,join等。
Spark采用了Scala来编写,在函数表达上Scala有天然的优势,因此在表达复杂的机器学习算法能力比其他语言更强且简单易懂。提供各种操作函数来建立起RDD的DAG计算模型。把每一个操作都看成构建一个RDD来对待,而RDD则表示的是分布在多台机器上的数据集合,并且可以带上各种操作函数。如下图所示:
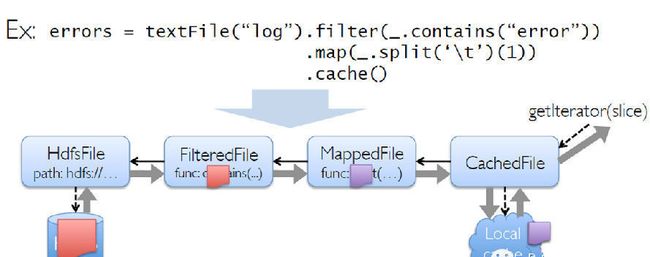
首先从hdfs文件里读取文本内容构建成一个RDD,然后使用filter()操作来对上次的RDD进行过滤,再使用map()操作取得记录的第一个字段,最后将其cache在内存上,后面就可以对之前cache过的数据做其他的操作。整个过程都将形成一个DAG计算图,每个操作步骤都有容错机制,同时还可以将需要多次使用的数据cache起来,供后续迭代使用。
3.Shark的工作原理
Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,由于底层的计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,如果是纯内存计算的SQL,要快5倍以上,当数据全部load在内存的话,将快10倍以上,因此Shark可以作为交互式查询应用服务来使用。

上图就是整个Shark的框架图,与其他的SQL引擎相比,除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上。
与Hive相比,Shark的特性如下:
1.以在线服务的方式执行任务,避免任务进程的启动和销毁开稍,通常MapReduce里的每个任务都是启动和关闭进程的方式来运行的,而在Shark中,Server运行后,所有的工作节点也随之启动,随后以常驻服务的形式不断的接受Server发来的任务。
2.Groupby和Join操作不需要Sort工作,当数据量内存能装下时,一边接收数据一边执行计算操作。在Hive中,不管任何操作在Map到Reduce的过程都需要对Key进行Sort操作。
3.对于性能要求更高的表,提供分布式Cache系统将表数据事先Cache至内存中,后续的查询将直接访问内存数据,不再需要磁盘开稍。
4.还有很多Spark的特性,如可以采用Torrent来广播变量和小数据,将执行计划直接传送给Task,DAG过程中的中间数据不需要落地到Hdfs文件系统。
腾讯大数据Spark的概况
腾讯大数据综合了多个业务线的各种需求和特性,目前正在进行以下工作:
1.经过改造和优化的Shark和Spark吸收了TDW平台的功能,如Hive的特有功能:元数据重构,分区优化等,同时可以通过IDE或者洛子调度来直接执行HiveSql查询和定时调度Spark的任务;
2.与Gaia和TDW的底层存储直接兼容,可以直接安全且高效地使用TDW集群上的数据;
3.对Spark底层的使用门槛,资源管理与调度,任务监控以及容灾等多个功能进行完善,并支持快速的迁移和扩容。
编辑注:TDW是腾讯内部规模最大的分布式系统,为腾讯的各个产品提供海量数据存储和分析服务,目前该项目已经开源,更多资料可查看项目介绍。