机器学习_周志华(西瓜书) 课后习题答案 第四章 Chapter4
习题4.3
Q:试编程实现基于信息熵进行划分选择的决策树算法,并为表4.3中数据生成一棵决策树。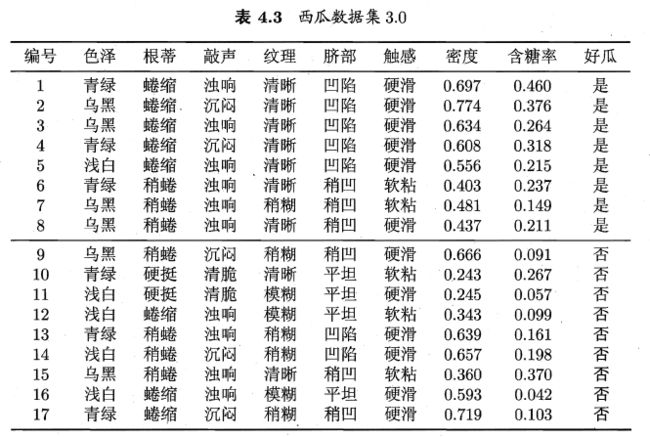
表4.3 西瓜数据集3.0中包含6个离散属性(分别3个属性值)、两个连续属性(分别17个属性值)。
●●●●●●
Step1:对于离散属性,我们可以直接计算各属性的信息增益Gain(D,a);
Step2:对于连续属性,我们需要先根据其属性值(17个),首先确定候选值(16个),然后计算各属性的信息增益,选择其划分点;
Step3:对比各属性的信息增益,选择最大的一个属性选作根结点划分属性;
Step4:根结点将数据集D划分为若干子集,分别对这些子集进行划分选择(选择信息增益最大的属性作为下一个结点),直至不能再划分
●●●●●●
其中,不能划分的情况可以认为有以下几种:
1.当前结点包含的样本全属于同一类,无需划分,此结点即为叶结点;
2.当前属性集为空(离散属性划分一次少一个),或是所有样本在所有属性上取值相同,无法划分;
3.当前结点的样本集合为空,不能划分;
接下来我们一步步进行:
Step1:读取数据集,并规范为数值形式
数据文件为‘data.txt’
编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜
1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是
2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是
3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是
4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是
5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是
6,青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是
7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是
8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是
9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否
10,青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否
11,浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否
12,浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否
13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否
14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否
15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.36,0.37,否
16,浅白,蜷缩,浊响,模糊,平坦,硬滑,0.593,0.042,否
17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否
import numpy as np
replace_items = [['乌黑', '0'], ['青绿', '1'], ['浅白', '2'], ['蜷缩', '0'], ['稍蜷', '1'], ['硬挺', '2'],
['沉闷', '0'], ['浊响', '1'], ['清脆', '2'], ['模糊', '0'], ['稍糊', '1'], ['清晰', '2'],
['凹陷', '0'], ['稍凹', '1'], ['平坦', '2'], ['硬滑', '0'], ['软粘', '1'],
['是', '0'], ['否', '1']]
def read_data(frame, replace_items):
"""读取文本数据(数据格式:第一行属性,第二行:属性值), 并返回数值化的数据集矩阵和属性矩阵"""
data = open(frame, 'r')
lines_data = data.readlines()
data.close()
array_feature = np.array(lines_data[0].strip('\n').split(','))
array_data = np.zeros((len(lines_data)-1, array_feature.shape[0]))
i = 0
for line in lines_data[1:]:
line = line.strip('\n')
for item in replace_items:
line = line.replace(item[0], item[1])
array_data[i, :] = line.split(',')
i += 1
return array_data, array_feature
Step1:计算离散属性的信息增益
def caculate_ent(array_data):
kinds_count = np.bincount(array_data[:, -1].astype('int32'))
n = sum(kinds_count)
ent = 0
for kind in kinds_count:
if kind != 0:
ent -= (kind/n)*log((kind/n), 2)
else:
pass
return ent
Step2:计算连续属性的信息增益
def caculate_gain(array_data, feature_index):
ent_d = caculate_ent(array_data)
kinds_dict = {}
sorted_data = array_data[array_data[:, feature_index].argsort()]
"""根据第feature_index属性对数据集进行排序分组,得到一个字典:key为属性值,value为矩阵"""
for i in range(array_data.shape[0]):
j = sorted_data[i, feature_index]
if j in kinds_dict.keys():
kinds_dict[j] = np.row_stack((kinds_dict[j], sorted_data[i, :]))
else:
kinds_dict[j] = np.array(sorted_data[i, :])
ent_sum_dv = 0
for key in kinds_dict.keys():
ent_dv = caculate_ent(kinds_dict[key])
p = kinds_dict[key].shape[0]/array_data.shape[0]
ent_sum_dv += p * ent_dv
return ent_d - ent_sum_dv
Step3:划分选择,直至不能划分或无需划分
Step4:生成决策树
(持续更新……)