Tensorflow学习笔记(一)
一.启动Tensorboard
在python文件中
加上tf.reset_default_graph()来重置流
然后:
logdir='D:/log' #定义log的存放目录
writer=tf.summary.FileWriter(logdir,tf.get_default_graph()) #将流图获取到放到log目录里
writer.close()
在Cmd中,
1:切换路径 cd /d D:
2:切换到D盘
3:然后输入tensorboard.exe --logdir=D:\log 来启动tensorboard。
4:在浏览器输入localhost:6006即可
二.placeholder占位符
1.Variable变量类型在定义的时候需要初始化,有些变量定义时并不知道数值,只有当真正开始运行程序的时候才由外部输入,比如训练数据,这时就需要占位符。
接口函数如下:
tf.placeholder(dtype,shape=None,name=None)
例如:
tf.placeholder(tf.float32,[2,3],name='tx')
生成一个2x3的二维数组,每个元素的类型都是float32
2.Feed提交数据
如果构建了一个包含placeholder操作的计算图,当在session中调用run方法时,placeholder占用的变量必须通过feed_dict参数传递进去,否则报错
import tensorflow as tf
a=tf.placeholder(tf.float32,name='a')
b=tf.placeholder(tf.float32,name='b')
c=tf.multiply(a,b,name='c')
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
result=sess.run(c,feed_dict={a:8.0,b:3.5})
print(result)
三.机器学习梯度下降法
1.梯度:一个向量,表示某一个函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大。
2.学习率:用梯度乘以一个称为学习速率(或作步长)的标量,来确定下一个点的位置。
3.超参数:在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。
4.批量是指用于在单词迭代中计算梯度的样本总数
随机梯度下降法(SGD)每次迭代只使用一个样本,批量大小为1,如果进行足够的迭代,SGD也可以发挥作用。
小批量随机梯度下降法:是介于全批量迭代与SGD之间的这种方案,通常包括10-1000个随机样本。
四.单变量线性回归

五.多变量线性回归——波士顿房价
1.归一化解决不同特征值取值范围带来的影响
用特征值/(特征值最大值-特征值最小值)
2.过拟合


六.Mnist手写体识别
1.添加数据集:
import tensorflow as tf
import tensorflow.examples.tutorials.mnist.input_data as input_data
mnist=input_data.read_data_sets("MNIST_data/",one_hot=True)
2.one-hot编码
将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点,,使得距离和相似度的计算都是基于欧式空间的
3.argmax
np.argmax(mnist.train.labels[1])表示第一张图片的标签中最大的值的索引
4.为了使模型对新的数据做出良好的预测
将数据集分为:训练集和测试集
确保测试集规模足够大,具有统计学意义,能代表整个数据集
5.为了降低过拟合的几率
划分为:训练集,验证集,测试集
使用验证集来评估训练集的效果,在通过验证集后,再使用测试集进行检查评估
6.训练集:55000
验证集:5000
测试集:10000
7.逻辑回归(logistic regression)
许多问题的预测结果是一个在连续空间的数值,比如房价预测问题,可以用线性模型来描述,但很多场景需要输出的概率估算值,比如:根据邮件内容判断是垃圾邮件的可能性。
这时需要将预测输出值控制在[0,1]区间内
二元分类问题的目标是正确预测两个可能的标签中的一个
逻辑回归可以处理这类问题
8.sigmod函数

9.逻辑回归里的损失函数
如果使用MSE,则会出现局部最小值
使用对数损失函数
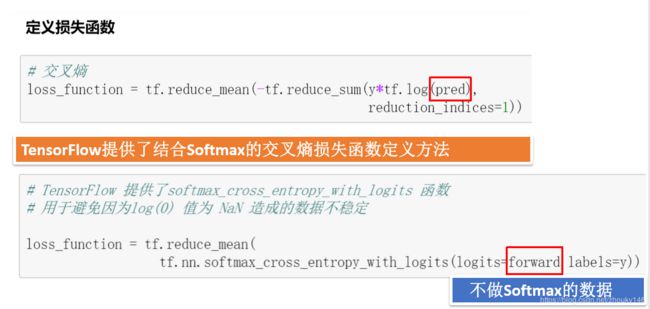
10.交叉熵损失函数
全连接神经网络的层数只看隐藏层,不看输入层和输出层。
11.层数的影响

12.隐藏层函数


七.卷积神经网络(Convolutional Neutral network)
1.全连接神经网络的局限:全连接网络的参数多,导致计算速度慢,过拟合。
2.CNN是一个多层的神经网络,每层由多个二维平面组成,其中每个平面由多个独立神经元组成。
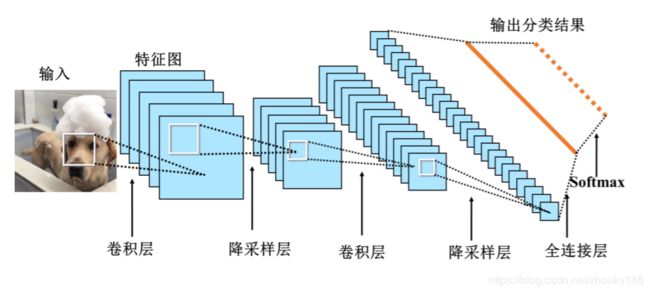
(1)输入层:将每个像素代表一个特征节点输入到网络中
(2)卷积层:卷积运算的主要目的是使原信号特征增强,并降低噪音
(3)降采样层:降低网络训练参数及模型的过拟合程度。池化可以实现降采样,但降采样不只是有池化。
(4)全连接层:对生成的特征进行加权
3.卷积:卷积核在2维输入数据上“滑动”,对当前输入部分的元素进行矩阵乘法,然后讲结果汇为单个输出像素值,重复这个过程直到遍历整个图像。

卷积核:权值矩阵
特征图:卷积操作后的图像
卷积层:目的是使原信号的特征增强,降低噪音
4.卷积的特点:权值共享:卷积核在图像上滑动过程中保持不变
局部连接:每个输出特性不用查看每个输入特征,而只需查看部分输入特征。


5.多通道卷积:为了使特征提取更充分,可以添加多个卷积核以提取不同的特征
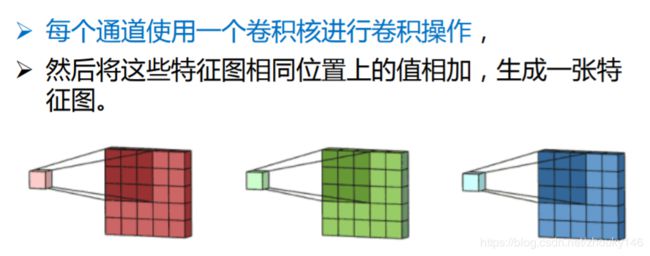
将这些特征图相同位置上的值相加,生成一张特征图
每个位置加偏置
6.池化:计算图像一个区域上的某个特定特征的平均值或最大值叫做池化
卷积层的作用使探测上一层特征的局部连接,而池化的作用是在语义上把相似的特征合并起来,达到降维的目的。
池化不仅具有低得多的维度,也不容易产生过拟合。
①均值池化:对池化的像素取均值,得到的特征数据对背景信息更加敏感
②最大池化:对池化区域内所有的像素点取最大值。得到的特征对纹理信息更加敏感。
7.步长:
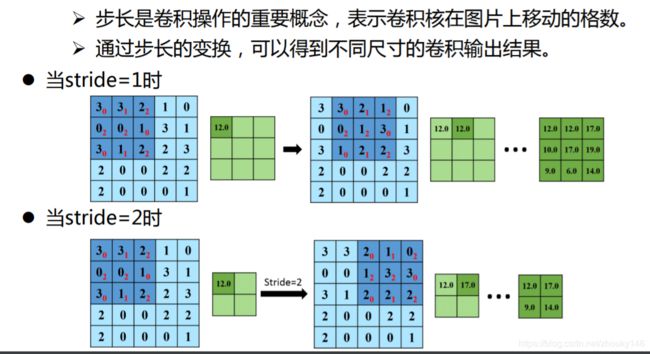
步长大于1的卷积操作也是降维的一种方式。
假如步长为S,原始图片的尺寸为[N1,N1],卷积核的大小为[N2,N2]
那么卷积之后图像的大小:
[(N1-N2)/S+1,(N1-N2)/S+1]
卷积的作用:使原信号特征增强(得到显著的边缘特征),并且降低噪音
降采样后:减少数据处理量的同时保留有用信息。
八.Tensorflow里的卷积函数

池化函数
